机器学习总结(二):逻辑回归
2017-08-16 23:31
507 查看
上一篇博客我简要总结了线性回归的知识点,这篇博客将主要回顾逻辑回归的知识点,作为线性模型的另一种,逻辑回归主要用于分类问题,即用于因变量是离散类型的场景,在实际的应用中尤其是二分类问题中比较常见。
决策边界(decision boundary)
高级优化算法
多类别分类问题
逻辑回归代码实现
正则化后的逻辑回归
以上知识点因为数学公式较多,编辑困难的原因,我都采用手写的形式呈现出来,具体可见最后面的附加笔记部分。
注释:test_logisticRegression方法使用的是默认参数的逻辑回归;test_logisticRegression_multinomial方法使用的是设置了multi_class和solver参数的逻辑回归;test_logisticRegression_C方法使用的是设置了参数C的逻辑回归。
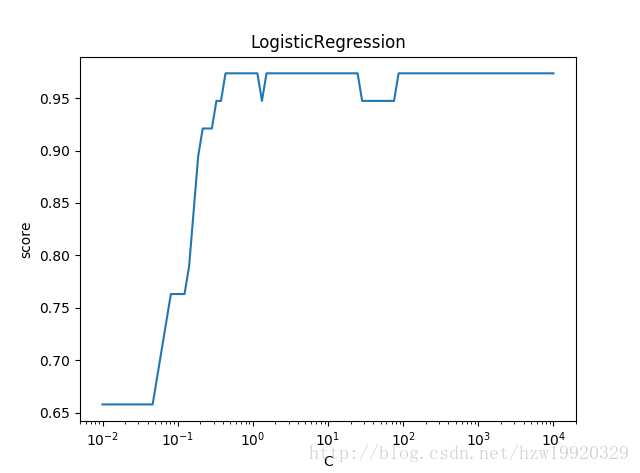
可以看到,使用默认参数的逻辑回归,准确率能达到97%;设置multi_class以及solver参数之后的逻辑回归,准确率居然能达到100%;而对于设置了不同C值的逻辑回归,随着C值的变大(正则化项变小,因为C值是正则化系数的倒数,系数变大,为了保证损失函数变小,正则化项只能变小啦),预测的准确率是呈现上升趋势的,当C值增大到一定程度之后,准确率也维持在一个相对稳定的状态了。




Andrew Ng 机器学习公开课
http://www.jianshu.com/p/f374de37efc3
http://blog.csdn.net/programmer_wei/article/details/52072939
逻辑回归知识点
逻辑回归损失函数及其梯度的推导决策边界(decision boundary)
高级优化算法
多类别分类问题
逻辑回归代码实现
正则化后的逻辑回归
以上知识点因为数学公式较多,编辑困难的原因,我都采用手写的形式呈现出来,具体可见最后面的附加笔记部分。
逻辑回归代码实现
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model, discriminant_analysis, cross_validation
def load_data():
iris = datasets.load_iris()
y_train = iris.target
#在此最后一个参数stratify表示分层采样,因为原始的iris数据集前50个样本类别都是0,中间50个样本类别是1
#最后50个样本的类别是2,如果不采用分层采样的话,会造成测试数据集不是无偏的情况
return cross_validation.train_test_split(iris.data, iris.target, test_size=0.25, random_state=0, stratify=y_train)
def test_logisticRegression(*data):
X_train, X_test, y_train, y_test = data
logisticRegression = linear_model.LogisticRegression()
logisticRegression.fit(X_train, y_train)
print("权重向量:%s, b的值为:%s" % (logisticRegression.coef_, logisticRegression.intercept_))
print("预测性能得分: %.2f" % logisticRegression.score(X_test, y_test))
# 测试multi_class参数对分类结果的影响,multi_class参数可以设置成ovr即one-vs-rest策略和multinomial两种
# 默认采用的是one-vs-rest策略,但是逻辑回归是支持多类分类的,在我们设置multi_class='multinomial'使用
# LogisticRegression的时候,只有solver参数为牛顿法或者拟牛顿法才能配合其使用,否则会报错。
def test_logisticRegression_multinomial(*data):
X_train, X_test, y_train, y_test = data
logisticRegression = linear_model.LogisticRegression(multi_class='multinomial', solver='lbfgs')
logisticRegression.fit(X_train, y_train)
print("权重向量:%s, b的值为:%s" % (logisticRegression.coef_, logisticRegression.intercept_))
print("预测性能得分: %.2f" % logisticRegression.score(X_test, y_test))
#测试参数C对分类结果的影响,参数C表示正则化系数的倒数,他越小则正则化项的权重越大。
def test_logisticRegression_C(*data):
X_train, X_test, y_train, y_test = data
# 创建从10的-2次方开始,10的4次方结束的100个数组成的等比数列,注意logspace函数默认是用10作为幂的
# 如果想要修改幂的话,可以设置base参数
Cs = np.logspace(-2, 4, num=100)
scores = []
for C in Cs:
logisticRegression = linear_model.LogisticRegression(C=C)
logisticRegression.fit(X_train, y_train)
scores.append(logisticRegression.score(X_test, y_test))
return Cs, scores
def show_plot(Cs, scores):
figure = plt.figure()
axe = figure.add_subplot(1, 1, 1)
axe.plot(Cs, scores)
axe.set_xlabel(r"C")
axe.set_ylabel(r"score")
axe.set_xscale('log')
axe.set_title("LogisticRegression")
plt.show()
if __name__== '__main__':
#使用默认的参数情况下的逻辑回归
X_train, X_test, y_train, y_test = load_data()
test_logisticRegression(X_train, X_test, y_train, y_test)
#设置参数multi_class='multinomial',参数solver='lbfgs'情况下的逻辑回归
test_logisticRegression_multinomial(X_train, X_test, y_train, y_test)
#测试参数C对逻辑回归分类结果的影响,并绘制出C值与预测准确率之间的图像
Cs, scores = test_logisticRegression_C(X_train, X_test, y_train, y_test)
show_plot(Cs, scores)注释:test_logisticRegression方法使用的是默认参数的逻辑回归;test_logisticRegression_multinomial方法使用的是设置了multi_class和solver参数的逻辑回归;test_logisticRegression_C方法使用的是设置了参数C的逻辑回归。
示例输出
权重向量:[[ 0.39310895 1.35470406 -2.12308303 -0.96477916] [ 0.22462128 -1.34888898 0.60067997 -1.24122398] [-1.50918214 -1.29436177 2.14150484 2.2961458 ]], b的值为:[ 0.24122458 1.13775782 -1.09418724] 预测性能得分: 0.97 权重向量:[[-0.38369615 0.85492705 -2.27255078 -0.98450966] [ 0.34345813 -0.3737305 -0.03022902 -0.86134613] [ 0.04023802 -0.48119655 2.3027798 1.84585579]], b的值为:[ 8.80069791 2.46878114 -11.26947905] 预测性能得分: 1.00
可以看到,使用默认参数的逻辑回归,准确率能达到97%;设置multi_class以及solver参数之后的逻辑回归,准确率居然能达到100%;而对于设置了不同C值的逻辑回归,随着C值的变大(正则化项变小,因为C值是正则化系数的倒数,系数变大,为了保证损失函数变小,正则化项只能变小啦),预测的准确率是呈现上升趋势的,当C值增大到一定程度之后,准确率也维持在一个相对稳定的状态了。
附加笔记
参考文献
python大战机器学习Andrew Ng 机器学习公开课
http://www.jianshu.com/p/f374de37efc3
http://blog.csdn.net/programmer_wei/article/details/52072939

相关文章推荐
- 机器学习总结(二)——逻辑斯谛回归和最大熵模型
- 机器学习总结之逻辑回归Logistic Regression
- 机器学习逻辑回归模型总结——从原理到sklearn实践
- 机器学习总结(二):线性回归、逻辑斯谛回归(LR)、softmax回归、过拟合
- 机器学习总结之逻辑回归Logistic Regression
- 机器学习逻辑回归模型总结——从原理到sklearn实践
- [置顶] 机器学习总结二:逻辑回归Logistic Regression
- 机器学习总结(lecture 4)算法:逻辑回归Logistic Regression (LR)
- 机器学习总结系列之逻辑回归
- 机器学习总结5_Logistic Regression(逻辑回归)
- 机器学习概念总结笔记(二)——逻辑回归、贝叶斯分类、支持向量分类SVM、分类决策树ID3、
- 机器学习(三):逻辑回归应用_手写数字识别_OneVsAll_Python
- 七月算法机器学习笔记4--线性回归与逻辑回归
- 机器学习知识体系 - 逻辑回归
- 机器学习(二):逻辑回归
- [机器学习] Coursera ML笔记 - 逻辑回归(Logistic Regression)
- 【机器学习】逻辑回归(Logistic Regression)
- 机器学习_最小二乘法,线性回归与逻辑回归
- 机器学习之逻辑斯提回归(Logistic Regression)模型
- 机器学习:逻辑回归