java开发编程及工程部署中编码问题
2017-08-16 17:42
253 查看
public static void currentSystemChartSet(){
System.out.println("Default Charset: " + Charset.defaultCharset());
System.out.println("file.encoding: " + System.getProperty("file.encoding"));
System.out.println("sun.jnu.encoding: "+System.getProperty("sun.jnu.encoding"));
System.out.println("Default Charset in Use: " + (new OutputStreamWriter(new ByteArrayOutputStream()).getEncoding()));
BufferedReader br = new BufferedReader(new InputStreamReader(inputStream));
BufferedReader br = new BufferedReader(new InputStreamReader(inputStream,encoding));//最好写成这种样式
}
输出结果:
Default Charset: UTF-8
file.encoding: UTF-8
sun.jnu.encoding: GBK
Default Charset in Use: UTF8
1.Charset.defaultCharset(),获取的语言环境的编码到底是哪里来的
是eclipse默认编码的问题;修改既可以。如下图
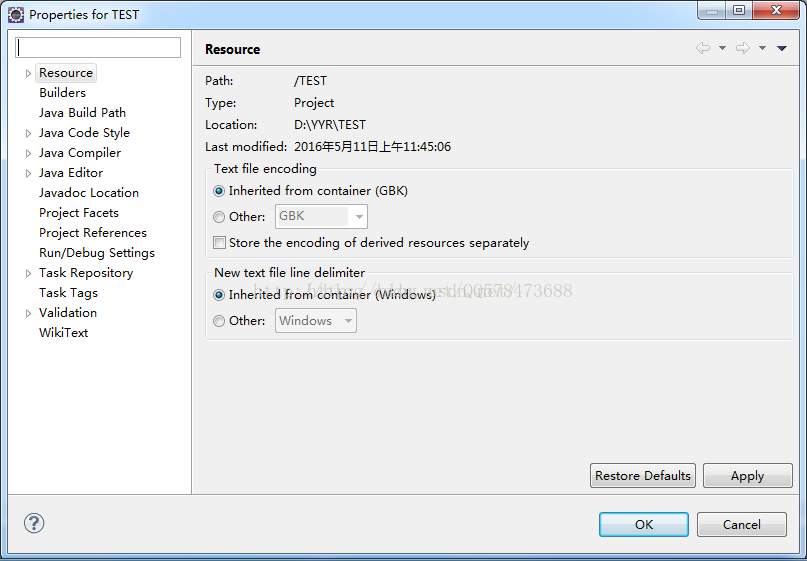
但是这就是问题了:线上是放在tomcat中的。没有eclipse。你说Charset.defaultCharset() 读取是哪里的语言环境的编码呢?
补充:tomcat没有默认语言编码。可以设置conf/server.xml文件中Connector 标签;设置<Connector URIEncoding="utf-8" />;
可以修改环境变量:
变量名:JAVA_TOOL_OPTIONS变量值:-Dfile.encoding=UTF-8

Charset.defaultCharset()默认读取还是配置的语言编码;也是就是系统的;
在java中,一切存储在硬盘上的数据都是二进制的字节,当我们从硬盘读取到字节数组后,如果我们需要把字节 数组转化成String类型的字符串,字节数组需要遵守一定的规则才能正确的转化为字符串,这就用到了编码 :charset。
1、如果使用了eclipse,由java文件的编码决定
2、如果没有使用eclipse,则有本地电脑语言环境决定,中国的都是默认GBK编码
2.System.getProperty("file.encoding")
以前一直以为file.encoding的编码就是系统的编码,直到最近碰见一个怪异的情况:WEB工程中通过上述代码打印出来的编码是GB18030,而登录Linux服务器执行locale或者vi /etc/sysconfig/i18n查出来的编码是UTF-8,竟然两者不一致,一度怀疑是不是服务器编码变了,引发了这篇文章的思考。
file.encoding的值保存的是每个程序的main入口的那个Java文件的保存编码,是.java文件的编码。
3.System.getProperty("sun.jnu.encoding")
sun.jnu.encoding 影响文件名的创建、类名的读取和Main方法参数的读取
参考:http://huangyunbin.iteye.com/blog/2356505 http://blog.csdn.net/youling_lh/article/details/9475519
参考:http://blog.csdn.net/bxyz1203/article/details/7352864 http://blog.csdn.net/u010234516/article/details/52842170 http://blog.csdn.net/loongshawn/article/details/50918506 http://blog.csdn.net/spritenet/article/details/5650622
System.out.println("Default Charset: " + Charset.defaultCharset());
System.out.println("file.encoding: " + System.getProperty("file.encoding"));
System.out.println("sun.jnu.encoding: "+System.getProperty("sun.jnu.encoding"));
System.out.println("Default Charset in Use: " + (new OutputStreamWriter(new ByteArrayOutputStream()).getEncoding()));
BufferedReader br = new BufferedReader(new InputStreamReader(inputStream));
BufferedReader br = new BufferedReader(new InputStreamReader(inputStream,encoding));//最好写成这种样式
}
输出结果:
Default Charset: UTF-8
file.encoding: UTF-8
sun.jnu.encoding: GBK
Default Charset in Use: UTF8
1.Charset.defaultCharset(),获取的语言环境的编码到底是哪里来的
是eclipse默认编码的问题;修改既可以。如下图
但是这就是问题了:线上是放在tomcat中的。没有eclipse。你说Charset.defaultCharset() 读取是哪里的语言环境的编码呢?
补充:tomcat没有默认语言编码。可以设置conf/server.xml文件中Connector 标签;设置<Connector URIEncoding="utf-8" />;
可以修改环境变量:
变量名:JAVA_TOOL_OPTIONS变量值:-Dfile.encoding=UTF-8
Charset.defaultCharset()默认读取还是配置的语言编码;也是就是系统的;
在java中,一切存储在硬盘上的数据都是二进制的字节,当我们从硬盘读取到字节数组后,如果我们需要把字节 数组转化成String类型的字符串,字节数组需要遵守一定的规则才能正确的转化为字符串,这就用到了编码 :charset。
1、如果使用了eclipse,由java文件的编码决定
2、如果没有使用eclipse,则有本地电脑语言环境决定,中国的都是默认GBK编码
2.System.getProperty("file.encoding")
以前一直以为file.encoding的编码就是系统的编码,直到最近碰见一个怪异的情况:WEB工程中通过上述代码打印出来的编码是GB18030,而登录Linux服务器执行locale或者vi /etc/sysconfig/i18n查出来的编码是UTF-8,竟然两者不一致,一度怀疑是不是服务器编码变了,引发了这篇文章的思考。
file.encoding的值保存的是每个程序的main入口的那个Java文件的保存编码,是.java文件的编码。
3.System.getProperty("sun.jnu.encoding")
sun.jnu.encoding 影响文件名的创建、类名的读取和Main方法参数的读取
参考:http://huangyunbin.iteye.com/blog/2356505 http://blog.csdn.net/youling_lh/article/details/9475519
参考:http://blog.csdn.net/bxyz1203/article/details/7352864 http://blog.csdn.net/u010234516/article/details/52842170 http://blog.csdn.net/loongshawn/article/details/50918506 http://blog.csdn.net/spritenet/article/details/5650622

相关文章推荐
- linux 下部署Java工程编码问题
- Java 程序编码规范-Java基础-Java-编程开发
- 探索JDK1.5高级编码特征-Java基础-Java-编程开发
- JAVA 开发中的编码问题
- java web 开发 编码问题详解
- Java语言深入-构造函数的继承问题-Java基础-Java-编程开发
- java中 中文问题详解-Java基础-Java-编程开发
- 开发日志:项目没错,但不管怎么修改页面/Java内容,在Tomcat上部署的项目都没有更新的问题
- javaWeb开发中的中文编码问题
- Java开发的编码问题
- weblogic部署项目问题-Java/Web开发
- Java Web开发构想(3) -- 可配置、可编程、可热部署、脚本逻辑 vs XML Tag逻辑
- Sublime Text 2搭建Java开发环境及输出编码问题解决
- Java web开发中的编码问题
- 每个java初学者都应该搞懂的问题-Java基础-Java-编程开发
- 比较开发阶段工程部署到tomcat问题
- Java常见问题集锦(来自Sun中国官方站)-Java基础-Java-编程开发
- android 工程开发问题Failed java.util.EmptyStackException
- Weblogic81和Hibernate 的集成问题-Java基础-Java-编程开发
- JAVA web开发中的编码问题-解决乱码问题