数据库连接池示例以及性能分析
2017-08-16 14:34
232 查看
直接上代码:
连接池ConnectionPool:
package com.shuaicenglou.ConnectionPool;
import java.util.LinkedList;
public class ConnectionPool {
private LinkedList<Connection> pool = new LinkedList<>();
public ConnectionPool(int ininum){
if(ininum>0){
for(int i=0;i<ininum;i++) pool.addLast(new Connection(Integer.toString(i+1)));
}
}
public void relese(Connection connection){
if(connection!=null){
synchronized (pool) {
pool.addLast(connection);
pool.notifyAll();
}
}
}
public Connection getConnection(long millis){
synchronized (pool) {
if(!pool.isEmpty()){
return pool.removeLast();
}else{
long future = System.currentTimeMillis()+millis;
long remaning = millis;
while(pool.isEmpty()&&remaning>0){
try {
pool.wait(remaning);
remaning = future - System.currentTimeMillis();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
Connection result = null;
if(!pool.isEmpty()) result = pool.removeLast();
return result;
}
}
}
}
在超时等待那里,也就是代码的27-34行,我原本是直接使用pool.wait(remaning);没有像<<Java并发编程的艺术>>上面那样使用future-remaining的写法,这导致我的连接池超时等待时间莫名地比书上的短,此处为何使用future-remaining的写法会让连接等待时间长一些,我无法理解,但是我的实现与<<Java并发编程的艺术>>上的实现对比,我的实现在并发程度高的时候劣化不够平缓。
模拟的数据库Connection:其commit方法只是睡眠100毫秒:
package com.shuaicenglou.ConnectionPool;
import java.util.concurrent.TimeUnit;
import java.util.jar.Attributes.Name;
public class Connection {
private String name;
public Connection(String name){
this.name = name;
}
public void commit(){
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
测试:
连接池ConnectionPool:
package com.shuaicenglou.ConnectionPool;
import java.util.LinkedList;
public class ConnectionPool {
private LinkedList<Connection> pool = new LinkedList<>();
public ConnectionPool(int ininum){
if(ininum>0){
for(int i=0;i<ininum;i++) pool.addLast(new Connection(Integer.toString(i+1)));
}
}
public void relese(Connection connection){
if(connection!=null){
synchronized (pool) {
pool.addLast(connection);
pool.notifyAll();
}
}
}
public Connection getConnection(long millis){
synchronized (pool) {
if(!pool.isEmpty()){
return pool.removeLast();
}else{
long future = System.currentTimeMillis()+millis;
long remaning = millis;
while(pool.isEmpty()&&remaning>0){
try {
pool.wait(remaning);
remaning = future - System.currentTimeMillis();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
Connection result = null;
if(!pool.isEmpty()) result = pool.removeLast();
return result;
}
}
}
}
在超时等待那里,也就是代码的27-34行,我原本是直接使用pool.wait(remaning);没有像<<Java并发编程的艺术>>上面那样使用future-remaining的写法,这导致我的连接池超时等待时间莫名地比书上的短,此处为何使用future-remaining的写法会让连接等待时间长一些,我无法理解,但是我的实现与<<Java并发编程的艺术>>上的实现对比,我的实现在并发程度高的时候劣化不够平缓。
模拟的数据库Connection:其commit方法只是睡眠100毫秒:
package com.shuaicenglou.ConnectionPool;
import java.util.concurrent.TimeUnit;
import java.util.jar.Attributes.Name;
public class Connection {
private String name;
public Connection(String name){
this.name = name;
}
public void commit(){
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
测试:
package com.shuaicenglou.ConnectionPool;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicInteger;
public class Test {
static ConnectionPool pool = new ConnectionPool(10);
static CountDownLatch start = new CountDownLatch(1);
static CountDownLatch end;
public static void main(String[] args)throws Exception {
int threadCount = 20;
end = new CountDownLatch(threadCount);
int count = 20;
AtomicInteger got = new AtomicInteger();
AtomicInteger notGot = new AtomicInteger();
for(int i=0;i<threadCount;i++){
Thread thread = new Thread(new R(count, got, notGot),"ConnectionRunnerThread");
thread.start();
}
start.countDown();
end.await();
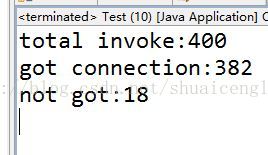
System.out.println("total invoke:"+(threadCount * count));
System.out.println("got connection:"+got);
System.out.println("not got:"+notGot);
}
static class R implements Runnable{
int count;
AtomicInteger got,notGot;
public R(int count,AtomicInteger got,AtomicInteger notGot) {
this.count = count;
this.got = got;
this.notGot = notGot;
}
@Override
public void run() {
try {
start.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
for(int i=0;i<count;i++){
Connection c = pool.getConnection(1000);
if(c!=null){
c.commit();
got.incrementAndGet();
pool.relese(c);
}else notGot.incrementAndGet();
}
end.countDown();
}
}
}结果:

相关文章推荐
- 9:Yii中的主题、日志、性能分析以及错误处理(Yii权威指南)
- c++中类似于java jprofiler/eclispe memoryanalysis的性能以及内存分析工具
- 从零开始学习OpenCL开发(二)一个最简单的示例与简单性能分析
- JS几种数组遍历方式以及性能分析对比
- JS几种数组遍历方式以及性能分析对比
- Map集合中value()、keySet()和entrySet()以及性能的分析
- 用示例说明filter()与find()的用法以及children()与find()的区别分析
- JS几种变量交换方式以及性能分析对比
- 数据库连接池DBCP框架的研究以及源代码分析三:打开AbandonedObjectPool连接池
- Shiro用户登录认证、权限授权示例,以及源码分析(上)
- ibatis一对一、一对多实现以及性能分析
- Linux性能测试工具-UnixBench--安装以及结果分析
- JDK下虚拟机性能监控以及故障分析工具
- GNSS星座覆盖以及导航定位性能评估分析
- JS几种数组遍历方式以及性能分析对比
- Map集合中value()、keySet()和entrySet()以及性能的分析
- JS几种数组遍历方式以及性能分析对比
- Linux性能测试工具-UnixBench--安装以及结果分析
- php中serialize序列化与json性能测试的示例分析
- php中serialize序列化与json性能测试的示例分析