Heritrix工具实现网络爬虫
2017-08-15 16:38
204 查看
上次用的java相关知识实现了一个简单的网络爬虫,现在存在许多开源免费的爬虫工具,相对来说,可以很简单的获取网页数据,并写入到本地。
下面我就阐述一下我用Heritrix爬虫工具实现网页数据爬取。
------>
目录
1、Heritrix文件配置
2、Heritrix服务器job配置
3、如何创建job并执行
4、有选择的爬取网页
5、总结
----->
1‘ 基础文件配置
网上下载heritrix的压缩包,即可配置一个爬虫服务器,其核心使用的是Tomcat。
解压压缩包,将conf目录下的 文件拷贝到根目录下。
文件拷贝到根目录下。
修改根目录下此文件,将.template去掉。
然后用记事本(我用的UItraEdit工具 ,方便看配置文件和代码)将文件打开,将@PASSWORD@的内容,更改为你的用户名和密码(自定义)。
,方便看配置文件和代码)将文件打开,将@PASSWORD@的内容,更改为你的用户名和密码(自定义)。

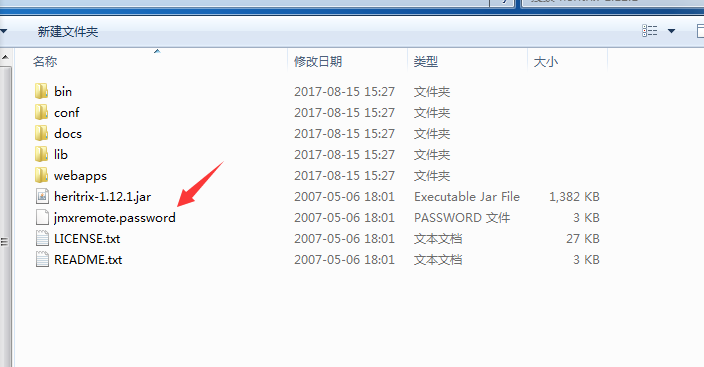
将imxremote.password的文件变为只读(属性)。
注意:【!!!如果是win7系统,需要将此文件的所有者改为当前用户,如图。
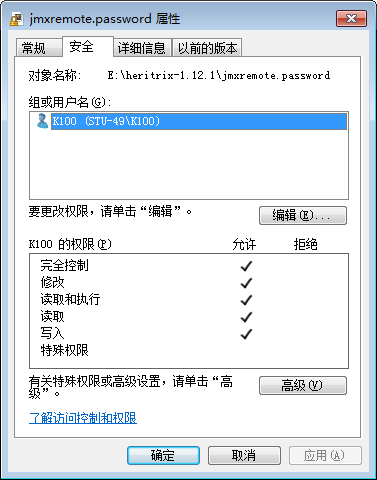
点击“高级”,
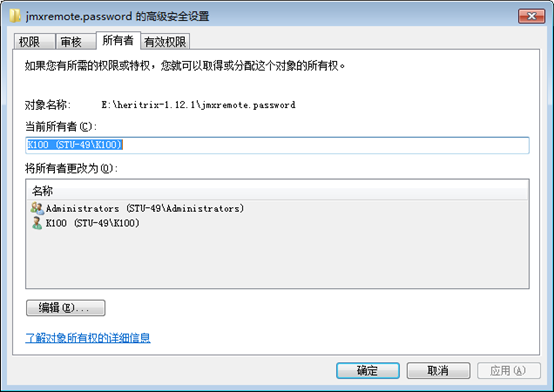
点击“编辑”
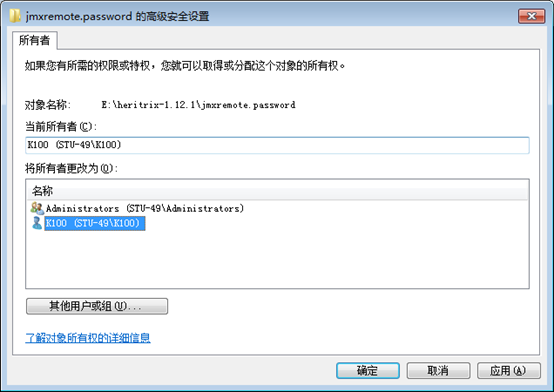
此处选择当前的用户,再点击”应用“,即可。
!!!】
2’ 服务器Job配置
执行bin目录下的heritrix.cmd命令,用来启动这个服务器(必须在命令行下执行)。
示例:首先进入该文件的bin目录下,启动命令为:
heritrix.cmd --admin=user:password
启动如果成功,显示窗口:

启动成功之后,通过浏览器访问当前服务器的8080端口来准备进行数据采集。
即输入 localhost:8080/

进入之后首先输入你刚开始配置时设定的用户名和密码。
然后进入首页:
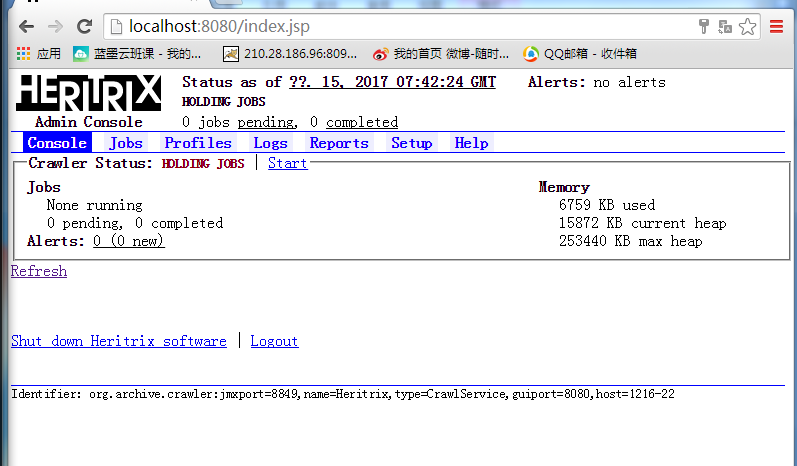
此窗口可以看到一些选项,有三个选项是比较重要的:
1) Console:控制台,在这里可以监控当前的任务爬取状态
2) Jobs:可以在这里建立新的爬取任务
3) Profiles:配置爬取的属性,例如:爬取的总线程数
首先需要在profiles中自己建立一个自定义的爬取的属性配置。在Profiles选项内选择New Profile based on it

进入界面:

点击Modules,
这里需要设置爬取时的参数类。
例如:爬取的范围,下载后的保存类型,爬取时所要下载的文件类型等。
首先要注意一点,两个change必须要点一下,我当时就是忽略了这个导致job无法提交!!!

之后,你需要在此界面下面设置10个类,按我的图来(规则我就不解释了):
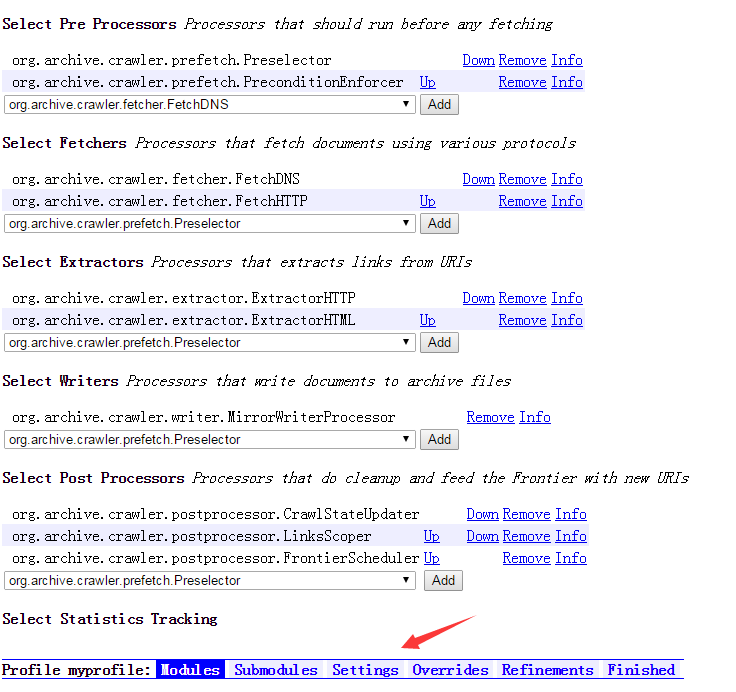
之后,选择Settings进行一些其他属性的配置,此处要更改一个线程数,(这个看你的电脑配置咯),之后再http-headers里面需要填写你的工具版本,ip地址以及个人邮箱(这个主要是告诉网站管理者哪个帅锅在爬我的网页,当然,劝告一下,国外和国内一些大型的网站不要爬取,很容易被监测到也可能触犯到信息窃取):

之后,点击Finished会提示Profile modified,表示修改成功。
3’ 建立爬取任务并执行
在Jobs选项里,选择Based on a profile选项,然后选择刚刚配置的那个myprofile,在此处选择你需要爬取的网站,我选择的是新浪新闻的首页:
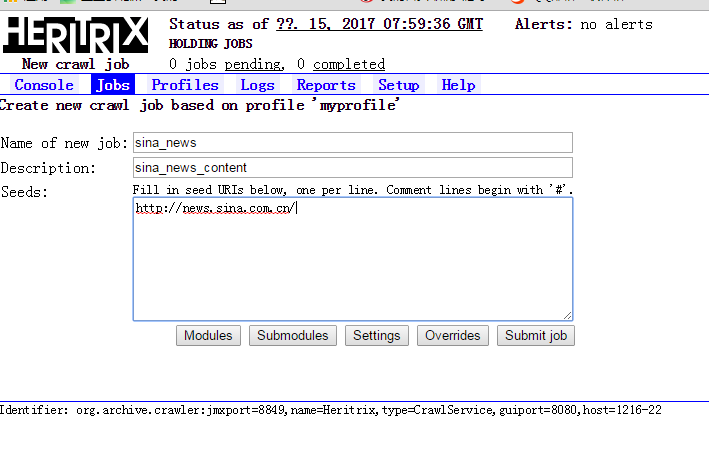
然后点击submit job,如果两个箭头都显示才表示创建job成功,相反我有一个配置类的没有点击change下面一个箭头就会提示初始化错误!

此时你进入console点击Start就会开始执行任务:
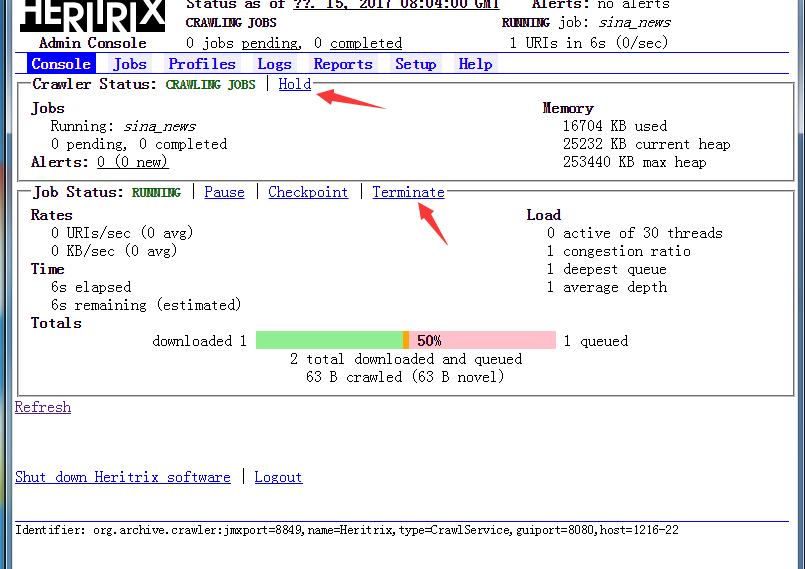
如果你要结束或者暂停任务,点击Terminate。
此时线程在不断爬取数据,你不断的点击Refresh会发现在不断更新数据,然后爬取的文件会在heritrix的根目录jobs里面找到,所有数据存放位置在如下路径的mirror文件夹内:
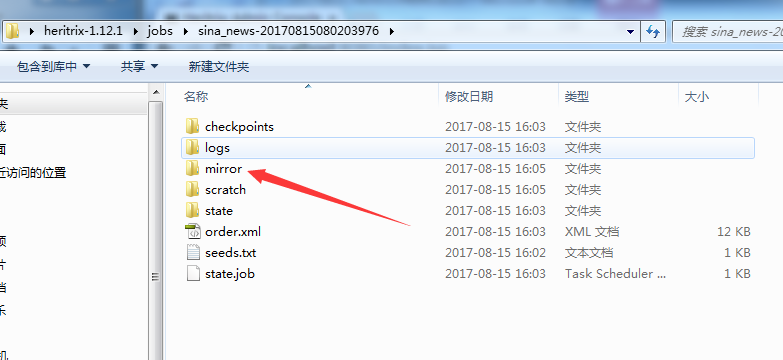
到此刻,网络爬取结束,如上就是这个工具的使用方法。
4‘ 如何有选择的爬取网页
测试时会发现,爬取的内容太杂,不一定都是我们想要的,因此我们需要对这个工具的源代码进行一些简单的调整。
首先要将heritrix的jar包备份解压;
然后需要将heritrix-1.12.1.jar文件拷贝到一个项目里,基于这个文件来进行配置。
编写好以后,需要将这个类打包到jar包里。(使用class文件)
之后,修改modules下的Processor.options文件。
将以下内容加入到这个文件中。
然后使用jar命令将包打到一起。
将jar包替换掉原有的包(可以把原有的做个备份留下,防止打包有问题无法恢复)。
重新启动heritrix,然后修改Profile的配置。
此时,再次爬取新浪新闻的时候,只会提取链接含有指定字符串的网址,排除很多无关的链接。
总结:
相对来说,Heritrix工具来爬取网页数据是相当简单的,无需写代码就可以进行大量的数据收集。
但是,与我上一篇博客《java实现网络爬虫》还是有些许不同:
首先在自由度上,手写的代码可以确认爬取的深度、排除无需爬取的网页、提取有用的数据;
其次在内容上很繁杂,很多无效的数据也收集了,而且爬取的网页会越来越多(当然,有一种修改配置的方法,写一个java代码限制爬取的网页,然后将该class文件放入heritrix的jar包(上述第四个标题)),关于修改源代码我相信很多新手都会望而止步,而且多写java代码来实现网络爬虫,益处多多;
最后在下一步数据分析上,可能多一点麻烦,谁会乐意整理一堆繁杂纷乱的数据呢?
至此,我还是倾向于java代码实现网络爬虫,而且可以很方便的将数据收集到hadoop中,进行大数据的mapreduce进行分析。
这样就相当于一个初步的大数据数据采集了。
下面我就阐述一下我用Heritrix爬虫工具实现网页数据爬取。
------>
目录
1、Heritrix文件配置
2、Heritrix服务器job配置
3、如何创建job并执行
4、有选择的爬取网页
5、总结
----->
1‘ 基础文件配置
网上下载heritrix的压缩包,即可配置一个爬虫服务器,其核心使用的是Tomcat。
解压压缩包,将conf目录下的
文件拷贝到根目录下。修改根目录下此文件,将.template去掉。
然后用记事本(我用的UItraEdit工具
,方便看配置文件和代码)将文件打开,将@PASSWORD@的内容,更改为你的用户名和密码(自定义)。
将imxremote.password的文件变为只读(属性)。
注意:【!!!如果是win7系统,需要将此文件的所有者改为当前用户,如图。
点击“高级”,
点击“编辑”
此处选择当前的用户,再点击”应用“,即可。
!!!】
2’ 服务器Job配置
执行bin目录下的heritrix.cmd命令,用来启动这个服务器(必须在命令行下执行)。
示例:首先进入该文件的bin目录下,启动命令为:
heritrix.cmd --admin=user:password
启动如果成功,显示窗口:
启动成功之后,通过浏览器访问当前服务器的8080端口来准备进行数据采集。
即输入 localhost:8080/
进入之后首先输入你刚开始配置时设定的用户名和密码。
然后进入首页:
此窗口可以看到一些选项,有三个选项是比较重要的:
1) Console:控制台,在这里可以监控当前的任务爬取状态
2) Jobs:可以在这里建立新的爬取任务
3) Profiles:配置爬取的属性,例如:爬取的总线程数
首先需要在profiles中自己建立一个自定义的爬取的属性配置。在Profiles选项内选择New Profile based on it
进入界面:
点击Modules,
这里需要设置爬取时的参数类。
例如:爬取的范围,下载后的保存类型,爬取时所要下载的文件类型等。
首先要注意一点,两个change必须要点一下,我当时就是忽略了这个导致job无法提交!!!
之后,你需要在此界面下面设置10个类,按我的图来(规则我就不解释了):
之后,选择Settings进行一些其他属性的配置,此处要更改一个线程数,(这个看你的电脑配置咯),之后再http-headers里面需要填写你的工具版本,ip地址以及个人邮箱(这个主要是告诉网站管理者哪个帅锅在爬我的网页,当然,劝告一下,国外和国内一些大型的网站不要爬取,很容易被监测到也可能触犯到信息窃取):
之后,点击Finished会提示Profile modified,表示修改成功。
3’ 建立爬取任务并执行
在Jobs选项里,选择Based on a profile选项,然后选择刚刚配置的那个myprofile,在此处选择你需要爬取的网站,我选择的是新浪新闻的首页:
然后点击submit job,如果两个箭头都显示才表示创建job成功,相反我有一个配置类的没有点击change下面一个箭头就会提示初始化错误!
此时你进入console点击Start就会开始执行任务:
如果你要结束或者暂停任务,点击Terminate。
此时线程在不断爬取数据,你不断的点击Refresh会发现在不断更新数据,然后爬取的文件会在heritrix的根目录jobs里面找到,所有数据存放位置在如下路径的mirror文件夹内:
到此刻,网络爬取结束,如上就是这个工具的使用方法。
4‘ 如何有选择的爬取网页
测试时会发现,爬取的内容太杂,不一定都是我们想要的,因此我们需要对这个工具的源代码进行一些简单的调整。
首先要将heritrix的jar包备份解压;
然后需要将heritrix-1.12.1.jar文件拷贝到一个项目里,基于这个文件来进行配置。
1 package org.liky.utils;
2
3 import org.archive.crawler.datamodel.CandidateURI;
4 import org.archive.crawler.postprocessor.FrontierScheduler;
5
6 public class SinaNewsScheduler extends FrontierScheduler {
7
8 public SinaNewsScheduler(String name) {
9 super(name);
10 }
11
12 @Override
13 public void schedule(CandidateURI caUri) {
14 // 根据路径,判断该url是否有必要抓取。
15 // 这里我们要求路径必须包含, news.sina.com.cn
16 if (caUri.toString().contains("news.sina.com.cn")) {
17 // 允许爬取
18 super.schedule(caUri);
19 }
20 }
21 }
自己编写好这个工具类。编写好以后,需要将这个类打包到jar包里。(使用class文件)
之后,修改modules下的Processor.options文件。
将以下内容加入到这个文件中。
|
org.liky.utils.SinaNewsScheduler|SinaNewsScheduler |
|
前半部分是包.类名,后半部分就是类名,中间用 | 分隔。 |
然后使用jar命令将包打到一起。
将jar包替换掉原有的包(可以把原有的做个备份留下,防止打包有问题无法恢复)。
重新启动heritrix,然后修改Profile的配置。
此时,再次爬取新浪新闻的时候,只会提取链接含有指定字符串的网址,排除很多无关的链接。
总结:
相对来说,Heritrix工具来爬取网页数据是相当简单的,无需写代码就可以进行大量的数据收集。
但是,与我上一篇博客《java实现网络爬虫》还是有些许不同:
首先在自由度上,手写的代码可以确认爬取的深度、排除无需爬取的网页、提取有用的数据;
其次在内容上很繁杂,很多无效的数据也收集了,而且爬取的网页会越来越多(当然,有一种修改配置的方法,写一个java代码限制爬取的网页,然后将该class文件放入heritrix的jar包(上述第四个标题)),关于修改源代码我相信很多新手都会望而止步,而且多写java代码来实现网络爬虫,益处多多;
最后在下一步数据分析上,可能多一点麻烦,谁会乐意整理一堆繁杂纷乱的数据呢?
至此,我还是倾向于java代码实现网络爬虫,而且可以很方便的将数据收集到hadoop中,进行大数据的mapreduce进行分析。
这样就相当于一个初步的大数据数据采集了。

相关文章推荐
- PYTHON 实现 NBA 赛程查询工具(二)—— 网络爬虫
- 基于Heritrix的特定主题的网络爬虫配置与实现
- 基于Heritrix的特定主题的网络爬虫配置与实现
- 基于Heritrix的特定主题的网络爬虫配置与实现
- 【正完成】Java基于Jsoup的网络爬虫工具实现
- 基于Heritrix的特定主题的网络爬虫配置与实现
- 【计算机网络】网络诊断工具ping的模拟实现之基础知识
- 【使用JSOUP实现网络爬虫】处理URLs
- 网络爬虫:基于对象持久化实现爬虫现场快速还原
- 【本科毕业设计论文】分布式网络爬虫的研究与实现
- node.js实现简单的网络爬虫程序
- 网络爬虫系统Heritrix的结构分析
- 网络爬虫heritrix 3.1 在Windows上的搭建与使用方法说明
- JAVA实现网络爬虫
- [搜片神器]之DHT网络爬虫的代码实现方法
- Python爬虫实战三之实现山东大学无线网络掉线自动重连
- 水晶报表的jsp实现(开发工具:bea weblogic workshop)整理自网络
- 基于HttpClient4.0的网络爬虫基本框架(Java实现)
- 模仿Wireshark网络抓包工具实现---c++
- Python实现网络爬虫