RNN循环神经网络代码实例
2017-08-14 17:00
567 查看
本文代码原文地址:blog.csdn.net/zzukun/article/details/49968129
原文中有更详尽的对RNN原理的介绍,形象生动,值得一看。
本文是我在读原文代码时作的批注,有更详细的解释和注释,看起来更容易一些。
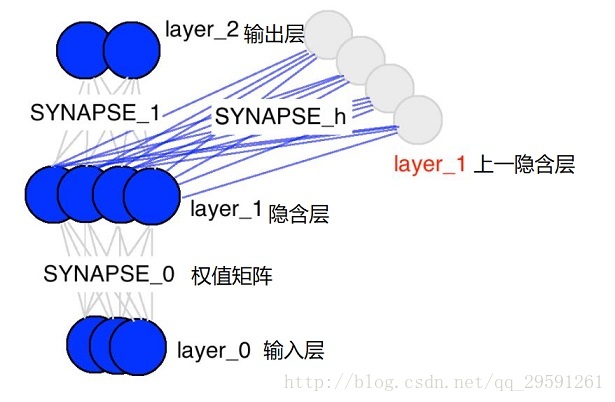
这个RNN模型的目的是计算两个八位二进制数的和,有进位。
顺便说一句,synapse是突触的意思,很形象。文末有出现在代码中numpy的函数的解释。
我们现在使用循环神经网络去建模二进制加法。你看到下面的序列了么?上边这俩在方框里的,有颜色的1是什么意思呢?
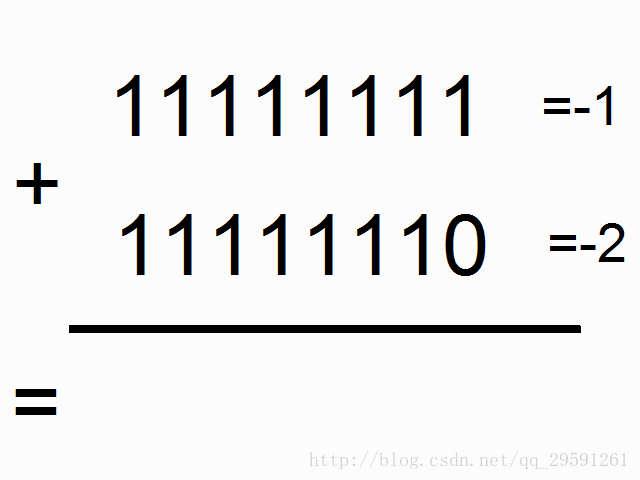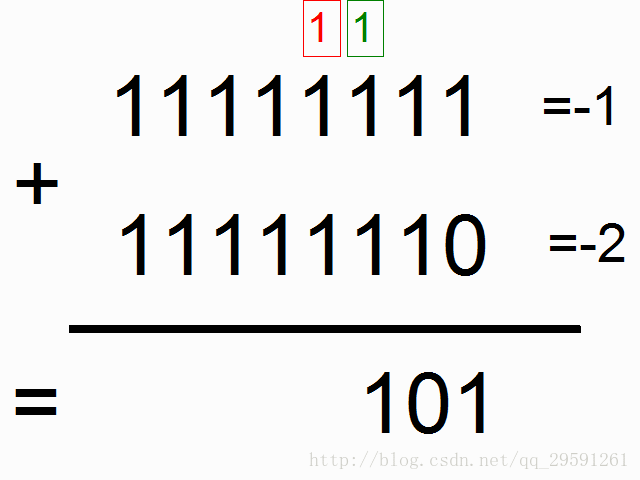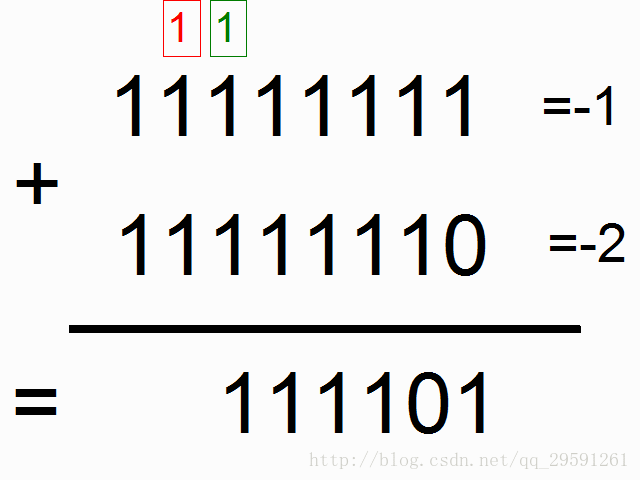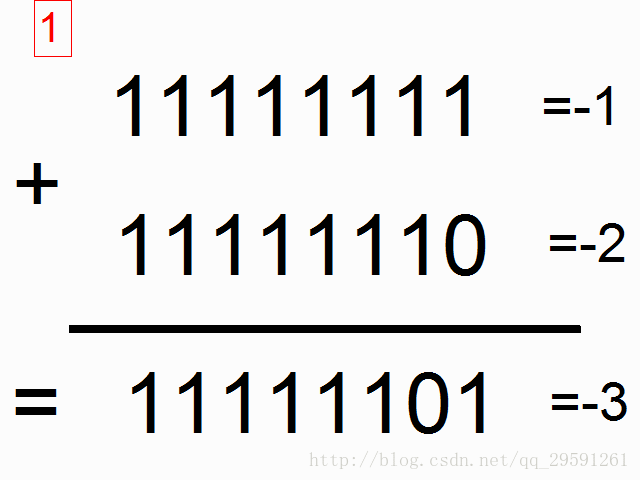
框框中彩色的1表示“携带位”。当每个位置的和溢出时(需要进位),它们“携带这个‘1’”。我们就是要教神经网络学习去记住这个“携带位”。当“和”需要它,它需要去“携带这个‘1’”。
二进制加法从右边到左边进行计算,我们试图通过上边的数字,去预测横线下边的数字。我们想让神经网络遍历这个二进制序列并且记住它携带这个1与没有携带这个1的时候,这样的话网络就能进行正确的预测了。不要迷恋于这个问题本身,因为神经网络事实上也不在乎。就当作我们有两个在每个时间步数上的输入(1或者0加到每个数字的开头),这两个输入将会传播到隐含层,隐含层会记住是否有携带位。预测值会考虑所有的信息,然后去预测每个位置(时间步数)正确的值。
代码:
运行输出:
代码中用到的numpy的函数:
np.array([],dtype=np.uint8)
用来创建数组,dtype=np.uint8表示数据类型是八位无符号整数
参考:https://docs.scipy.org/doc/numpy/reference/generated/numpy.array.html
np.array().T
返回矩阵的转置,即行列互换。如果只有一行,则返回本身
参考:https://docs.scipy.org/doc/numpy/reference/generated/numpy.ndarray.T.html
np.unpackbits()
将八位无符号整数以二进制形式表示,返回一个矩阵
参考:https://docs.scipy.org/doc/numpy/reference/generated/numpy.unpackbits.html
np.zeros_like([[]])
返回形状一样,值都为0的矩阵
参考:https://docs.scipy.org/doc/numpy/reference/generated/numpy.zeros_like.html
np.atleast_2d
把一个数或一维数组以二维数组形式返回
参考:https://docs.scipy.org/doc/numpy/reference/generated/numpy.atleast_2d.html
原文中有更详尽的对RNN原理的介绍,形象生动,值得一看。
本文是我在读原文代码时作的批注,有更详细的解释和注释,看起来更容易一些。
这个RNN模型的目的是计算两个八位二进制数的和,有进位。
顺便说一句,synapse是突触的意思,很形象。文末有出现在代码中numpy的函数的解释。
我们现在使用循环神经网络去建模二进制加法。你看到下面的序列了么?上边这俩在方框里的,有颜色的1是什么意思呢?
框框中彩色的1表示“携带位”。当每个位置的和溢出时(需要进位),它们“携带这个‘1’”。我们就是要教神经网络学习去记住这个“携带位”。当“和”需要它,它需要去“携带这个‘1’”。
二进制加法从右边到左边进行计算,我们试图通过上边的数字,去预测横线下边的数字。我们想让神经网络遍历这个二进制序列并且记住它携带这个1与没有携带这个1的时候,这样的话网络就能进行正确的预测了。不要迷恋于这个问题本身,因为神经网络事实上也不在乎。就当作我们有两个在每个时间步数上的输入(1或者0加到每个数字的开头),这两个输入将会传播到隐含层,隐含层会记住是否有携带位。预测值会考虑所有的信息,然后去预测每个位置(时间步数)正确的值。
代码:
import copy, numpy as np
np.random.seed(0)
# compute sigmoid nonlinearity
def sigmoid(x):
output = 1/(1+np.exp(-x)) #我们用到的非线性函数
return output
# convert output of sigmoid function to its derivative
def sigmoid_output_to_derivative(output): #上述函数的导数
return output*(1-output)
# training dataset generation
int2binary = {} #键是十进制数字,值是相对应的八位二进制,以列表形式存储,如int2binary[2]=[0,0,0,0,0,0,1,0]
binary_dim = 8 #二进制最大位数
largest_number = pow(2,binary_dim) #相对应的十进制最大的数
binary = np.unpackbits(
np.array([range(largest_number)],dtype=np.uint8).T,axis=1) #计算0~63的二进制数
for i in range(largest_number):
int2binary[i] = binary[i] #存进字典中
# input variables
alpha = 0.1 #学习速率
input_dim = 2 #输入是两个数
hidden_dim = 16 #隐含层是16位
output_dim = 1 #输出是一个数
# initialize neural network weights
synapse_0 = 2*np.random.random((input_dim,hidden_dim)) - 1 #初始化输入层和隐含层之间的权值矩阵,2X16的矩阵
synapse_1 = 2*np.random.random((hidden_dim,output_dim)) - 1 #初始化隐含层和输出层之间的权值矩阵,16X1的矩阵
synapse_h = 2*np.random.random((hidden_dim,hidden_dim)) - 1 #初始化上一个隐含层和当前隐含层的权值矩阵,16X16的矩阵
synapse_0_update = np.zeros_like(synapse_0) #初始化synapse_0的更新值
synapse_1_update = np.zeros_like(synapse_1) #初始化synapse_1的更新值
synapse_h_update = np.zeros_like(synapse_h) #初始化synapse_h的更新值
# training logic
for j in range(10000): #进行10000次迭代
# generate a simple addition problem (a + b = c) 以9+60为例
a_int = np.random.randint(largest_number/2) # int version 随机取一个小于二分之一最大值的整数,比如9
a = int2binary[a_int] # binary encoding #取其二进制表示[0,0,0,0,1,0,0,1]
b_int = np.random.randint(largest_number/2) # int version 随机取一个小于二分之一最大值的整数,比如60
b = int2binary[b_int] # binary encoding #取其二进制表示[0,0,1,1,1,1,0,0]
# true answer
c_int = a_int + b_int #正确结果的十进制69
c = int2binary[c_int] #正确结果的二进制[0,1,0,0,0,1,0,1]
# where we'll store our best guess (binary encoded)
d = np.zeros_like(c) #用来存放预测结果的二进制,这里只是初始化为0
overallError = 0 #重置误差
layer_2_deltas = list() #记录layer_2的导数值
layer_1_values = list() #记录layer 1的值
layer_1_values.append(np.zeros(hidden_dim)) #重置layer_1_values
# moving along the positions in the binary encoding
for position in range(binary_dim): #八位二进制从首位向末位循环
# generate input and output
X = np.array([[a[binary_dim - position - 1],b[binary_dim - position - 1]]]) #取9和60二进制首位[[0,0]]
y = np.array([[c[binary_dim - position - 1]]]).T #取正确结果二进制首位[[0]]
# hidden layer (input ~+ prev_hidden)
layer_1 = sigmoid(np.dot(X,synapse_0) + np.dot(layer_1_values[-1],synapse_h)) #根据当前输入和上一隐含层计算当前隐含层,1X16的矩阵
# output layer (new binary representation)
layer_2 = sigmoid(np.dot(layer_1,synapse_1)) #根据隐含层计算输出层,1X1的矩阵
# did we miss?... if so by how much?
layer_2_error = y - layer_2 #计算误差
layer_2_deltas.append((layer_2_error)*sigmoid_output_to_derivative(layer_2)) #把误差和输出层导数相乘存起来
overallError += np.abs(layer_2_error[0]) #计算误差绝对值之和
# decode estimate so we can print it out
d[binary_dim - position - 1] = np.round(layer_2[0][0]) #存放预测结果当前位
# store hidden layer so we can use it in the next timestep
layer_1_values.append(copy.deepcopy(layer_1)) #存放每一个隐含层,在反向传播的时候会用到
future_layer_1_delta = np.zeros(hidden_dim) #重置1X16矩阵
for position in range(binary_dim): #
db71
反向传播,所以是从末位向首位循环
X = np.array([[a[position],b[position]]]) #输入[[1,0]]
layer_1 = layer_1_values[-position-1] #取隐含层
prev_layer_1 = layer_1_values[-position-2] #取上一隐含层
# error at output layer
layer_2_delta = layer_2_deltas[-position-1] #取输出层误差和导数的乘积
# error at hidden layer
layer_1_delta = (future_layer_1_delta.dot(synapse_h.T) + \
layer_2_delta.dot(synapse_1.T)) * sigmoid_output_to_derivative(layer_1) #根据上一隐含层误差、输出层误差和导数的乘积,计算隐含层误差
# let's update all our weights so we can try again
synapse_1_update += np.atleast_2d(layer_1).T.dot(layer_2_delta) #计算权值矩阵的更新值
synapse_h_update += np.atleast_2d(prev_layer_1).T.dot(layer_1_delta) #计算权值矩阵的更新值
synapse_0_update += X.T.dot(layer_1_delta) #计算权值矩阵的更新值
future_layer_1_delta = layer_1_delta #存放隐含层误差,下轮循环使用
synapse_0 += synapse_0_update * alpha #更新权值矩阵,alpha是学习效率
synapse_1 += synapse_1_update * alpha
synapse_h += synapse_h_update * alpha
synapse_0_update *= 0 #重置权值更新矩阵
synapse_1_update *= 0
synapse_h_update *= 0
# print out progress #输出一些值供我们观察
if(j % 1000 == 0):
print ("Error:" + str(overallError)) #输出误差
print ("Pred:" + str(d)) #输出预测值二进制
print ("True:" + str(c)) #输出正确结果二进制
out = 0
for index,x in enumerate(reversed(d)):
out += x*pow(2,index)
print (str(a_int) + " + " + str(b_int) + " = " + str(out)) #输出a+b=预测结果
print ("------------") #我是华丽的分割线运行输出:
Error:[ 3.45638663] Pred:[0 0 0 0 0 0 0 1] True:[0 1 0 0 0 1 0 1] 9 + 60 = 1 ------------ Error:[ 3.63389116] Pred:[1 1 1 1 1 1 1 1] True:[0 0 1 1 1 1 1 1] 28 + 35 = 255 ------------ Error:[ 3.91366595] Pred:[0 1 0 0 1 0 0 0] True:[1 0 1 0 0 0 0 0] 116 + 44 = 72 ------------ Error:[ 3.72191702] Pred:[1 1 0 1 1 1 1 1] True:[0 1 0 0 1 1 0 1] 4 + 73 = 223 ------------ Error:[ 3.5852713] Pred:[0 0 0 0 1 0 0 0] True:[0 1 0 1 0 0 1 0] 71 + 11 = 8 ------------ Error:[ 2.53352328] Pred:[1 0 1 0 0 0 1 0] True:[1 1 0 0 0 0 1 0] 81 + 113 = 162 ------------ Error:[ 0.57691441] Pred:[0 1 0 1 0 0 0 1] True:[0 1 0 1 0 0 0 1] 81 + 0 = 81 ------------ Error:[ 1.42589952] Pred:[1 0 0 0 0 0 0 1] True:[1 0 0 0 0 0 0 1] 4 + 125 = 129 ------------ Error:[ 0.47477457] Pred:[0 0 1 1 1 0 0 0] True:[0 0 1 1 1 0 0 0] 39 + 17 = 56 ------------ Error:[ 0.21595037] Pred:[0 0 0 0 1 1 1 0] True:[0 0 0 0 1 1 1 0] 11 + 3 = 14 ------------
代码中用到的numpy的函数:
np.array([],dtype=np.uint8)
用来创建数组,dtype=np.uint8表示数据类型是八位无符号整数
参考:https://docs.scipy.org/doc/numpy/reference/generated/numpy.array.html
np.array().T
返回矩阵的转置,即行列互换。如果只有一行,则返回本身
参考:https://docs.scipy.org/doc/numpy/reference/generated/numpy.ndarray.T.html
np.unpackbits()
将八位无符号整数以二进制形式表示,返回一个矩阵
参考:https://docs.scipy.org/doc/numpy/reference/generated/numpy.unpackbits.html
np.zeros_like([[]])
返回形状一样,值都为0的矩阵
参考:https://docs.scipy.org/doc/numpy/reference/generated/numpy.zeros_like.html
np.atleast_2d
把一个数或一维数组以二维数组形式返回
参考:https://docs.scipy.org/doc/numpy/reference/generated/numpy.atleast_2d.html

相关文章推荐
- 基于循环神经网络(RNN)的古诗生成器
- 深度学习笔记(四):循环神经网络的概念,结构和代码注释
- 循环神经网络(Recurrent Neural Network, RNN)与LSTM
- 循环神经网络RNN
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)
- TensorFlow-RNN循环神经网络 Example 1:预测Sin函数
- 双向长短时记忆循环神经网络详解(Bi-directional LSTM RNN)
- 循环神经网络教程-第一部分 RNN介绍
- 循环神经网络(RNN)模型与前向反向传播算法
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- RNN(循环神经网络)详解
- 循环神经网络RNN(Recurrent Neural Network)
- 大话循环神经网络(RNN)
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构的区别
- RNN-循环神经网络和LSTM_01基础
- 理解CNN、DNN、RNN(递归神经网络以及循环神经网络)以及LSTM网络结构笔记
- 循环神经网络教程4-用Python和Theano实现GRU/LSTM RNN, Part 4 – Implementing a GRU/LSTM RNN with Python and Theano
- 循环神经网络(Recurrent Neural Networks, RNN)介绍
- 初探循环神经网络 RNN 及 TensorFlow 实现
- 机器学习之循环神经网络(RNN)入门