文本挖掘--数据文本处理-java
2017-08-08 22:15
344 查看
文本挖掘是一个对具有丰富语义的文本进行分析,从而理解其所包含的内容和意义的过程。文本挖掘包含分词、文本表示、文本特征选择、文本分类、文本聚类、文档自动摘要等方面的内容。文本挖掘的具体流程图可下图所示:
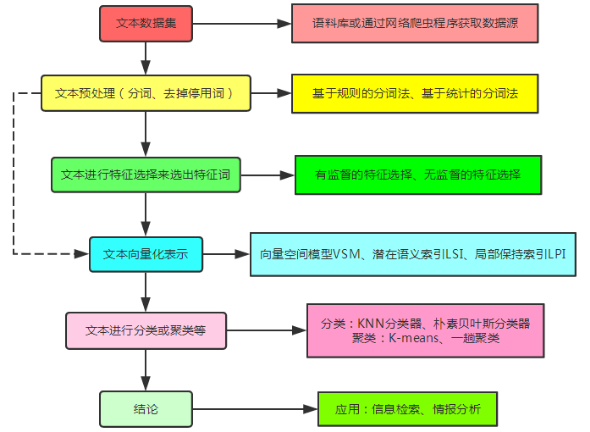
我的项目是以复旦大学中文语料库和路透社英文语料库为数据集的,都是有类别的两层目录文本集。
不管你要做什么,你首先都要先读取文本,为了方便后面的操作,我写了几个工具类。
一、文本信息类Text
利用该类来存储文本的文件路径、类别ID、进行分类或聚类后所属的类别ID、文本词向量、文本长度,方便我们设置或获取需要用到的信息。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
二、Map操作类MapUtil
因为在项目中有很多地方,需要对Map进行排序,打印,截取等操作,所以这里把这些操作单独出来,成为这个类。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
三、TXT文本读取类ReadTXT
我们需要读取原始文本内容,读取分词后的文本内容,读取TF集,读取TFIDF集,读取文本集信息。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
四、TXT写入类WriteTXT
我的项目是以复旦大学中文语料库和路透社英文语料库为数据集的,都是有类别的两层目录文本集。
不管你要做什么,你首先都要先读取文本,为了方便后面的操作,我写了几个工具类。
一、文本信息类Text
利用该类来存储文本的文件路径、类别ID、进行分类或聚类后所属的类别ID、文本词向量、文本长度,方便我们设置或获取需要用到的信息。
package util;
import java.util.Map;
/**
* 文本信息类,包含文本的文件路径,类别,词向量等
* @author Angela
*/
public class Text {
/**文本路径**/
private String path;
/**文本类别ID**/
private int originLabelID;
/**文本分类或聚类类别ID**/
private int judegeLabelID;
/**文本词-权重**/
private Map<String,Double> words;
/**文本长度**/
private double length;
/**
* @return the path
*/
public String getPath() {
return path;
}
/**
* @param path the path to set
*/
public void setPath(String path) {
this.path = path;
}
/**
* @return the words
*/
public Map<String,Double> getWords() {
return words;
}
/**
* @param words the words to set
*/
public void setWords(Map<String,Double> words) {
this.words = words;
}
/**
* @return the length
*/
public double getLength() {
return length;
}
/**
* @param length the length to set
*/
public void setLength(double length) {
this.length = length;
}
/**
* @return the originLabelID
*/
public int getOriginLabelID() {
return originLabelID;
}
/**
* @param originLabelID the originLabelID to set
*/
public void setOriginLabelID(int originLabelID) {
this.originLabelID = originLabelID;
}
/**
* @return the judegeLabelID
*/
public int getJudegeLabelID() {
return judegeLabelID;
}
/**
* @param judegeLabelID the judegeLabelID to set
*/
public void setJudegeLabelID(int judegeLabelID) {
this.judegeLabelID = judegeLabelID;
}
}12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
二、Map操作类MapUtil
因为在项目中有很多地方,需要对Map进行排序,打印,截取等操作,所以这里把这些操作单独出来,成为这个类。
package util;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.LinkedList;
import java.util.Map;
import java.util.Set;
/**
* Map操作类,包括排序,打印,截取
* @author Angela
*/
public class MapUtil {
/**对Map按键值升序排序**/
public static <K, V extends Comparable<? super V>>
Map<K, V> asc( Map<K, V> map){
//将map.entrySet()转换成list
LinkedList<Map.Entry<K, V>> list =
new LinkedList<Map.Entry<K, V>>( map.entrySet() );
//然后通过比较器来实现排序
Collections.sort( list, new Comparator<Map.Entry<K, V>>() {
//升序排序
public int compare( Map.Entry<K, V> o1, Map.Entry<K, V> o2 ){
return (o1.getValue()).compareTo( o2.getValue() );
}
} );
Map<K, V> result = new LinkedHashMap<K, V>();
for (Map.Entry<K, V> entry : list) {
result.put( entry.getKey(), entry.getValue() );
}
return result;
}
/**对Map按键值降序排序**/
public static <K, V extends Comparable<? super V>>
Map<K, V> desc( Map<K, V> map){
//将map.entrySet()转换成list
LinkedList<Map.Entry<K, V>> list =
new LinkedList<Map.Entry<K, V>>( map.entrySet() );
//然后通过比较器来实现排序
Collections.sort( list, new Comparator<Map.Entry<K, V>>() {
//降序排序
public int compare( Map.Entry<K, V> o1, Map.Entry<K, V> o2 ){
return (o2.getValue()).compareTo( o1.getValue() );
}
} );
Map<K, V> result = new LinkedHashMap<K, V>();
for (Map.Entry<K, V> entry : list) {
result.put( entry.getKey(), entry.getValue() );
}
return result;
}
/**
* 取键值大于最小阈值并且小于最大阈值的map子集
* @param map
* @param minThreshold 最小阈值
* @param maxThreshold 最大阈值
* @return
*/
public static <K, V extends Comparable<? super V>> Map<K,V> between(
Map<K,V> map,V minThreshold,V maxThreshold){
Map<K,V> temp=new HashMap<K,V>();
for(Map.Entry<K, V> me: map.entrySet()){
V value=me.getValue();
if(value.compareTo(minThreshold)>=0
&&value.compareTo(maxThreshold)<=0){
temp.put(me.getKey(), value);
}
}
return temp;
}
/**
* 返回键值大于最小阈值的map子集
* @param map
* @param minThreshold 最小阈值
* @return
*/
public static <K, V extends Comparable<? super V>> Map<K,V> range(
Map<K,V> map,V minThreshold){
Map<K,V> temp=new HashMap<K,V>();
for(Map.Entry<K, V> me: map.entrySet()){
V value=me.getValue();
if(value.compareTo(minThreshold)>=0){
temp.put(me.getKey(), value);
}
}
return temp;
}
/**
* 选前num的特征集合
* @param map 特征-权重集
* @param num 个数
* @return 前num的特征子集
*/
public static <K, V extends Comparable<? super V>> Map<K,V> sub(
Map<K,V> map,int num){
Map<K,V> temp=new HashMap<K,V>();
Set<Map.Entry<K,V>> set = map.entrySet();
Iterator<Map.Entry<K,V>> it = set.iterator();
int count=0;
while(count<num&&it.hasNext()){
Map.Entry<K,V> me = it.next();
V value=me.getValue();
temp.put(me.getKey(), value);
count++;
}
return temp;
}
/**
* 打印map的前num个数据
* @param map 特征-权重集
* @param num 个数
*/
public static <K, V extends Comparable<? super V>>
void print(Map<K,V> map,int num){
Set<Map.Entry<K,V>> set = map.entrySet();
Iterator<Map.Entry<K,V>> it = set.iterator();
int count=0;
while(it.hasNext()&&count<num){
Map.Entry<K,V> me = it.next();
System.out.println(me.getKey()+" "+me.getValue());
count++;
}
}
/**
* 打印map
* @param map 特征-权重集
*/
public static <K, V extends Comparable<? super V>> void print(Map<K,V> map){
for(Map.Entry<K, V> me: map.entrySet()){
System.out.println(me.getKey()+" "+me.getValue());
}
}
}12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
三、TXT文本读取类ReadTXT
我们需要读取原始文本内容,读取分词后的文本内容,读取TF集,读取TFIDF集,读取文本集信息。
package util;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.logging.Level;
import java.util.logging.Logger;
/**
* TXT读取类
* @author Angela
*/
public class ReadTXT {
/**
* 获取一篇文本的编码格式,注:所有文本的默认编码是“utf-8”
* @param filePath文本文件路径
* @return 文本文件的编码格式
*/
public static String getCharset(String filePath){
String charset = null;
try{
BufferedInputStream bin = new BufferedInputStream(
new FileInputStream(filePath));
int p = (bin.read() << 8) + bin.read();
switch (p) {
case 0xefbb:
charset = "UTF-8";
break;
case 0xfffe:
charset = "Unicode";
break;
case 0xfeff:
charset = "UTF-16BE";
break;
default:
charset = "GBK";
}
} catch (FileNotFoundException ex) {
Logger.getLogger(ReadTXT.class.getName()).log(Level.SEVERE, null, ex);
} catch (IOException ex) {
Logger.getLogger(ReadTXT.class.getName()).log(Level.SEVERE, null, ex);
}
return charset;
}
/**
* 读取一篇文本的全部内容
* @param filePath 还未分词的文本
* @return 无换行的文本内容,读取的内容用于后面的分词
*/
public static String read(String filePath){
StringBuilder sb=new StringBuilder();
String charset=getCharset(filePath);
try{
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(filePath),charset));
String s;
while((s=br.readLine())!=null){
sb.append(s);
}
br.close();
}catch (IOException ex) {
Logger.getLogger(ReadTXT.class.getName()).log(Level.SEVERE, null, ex);
}
return sb.toString();
}
/**
* 一行一个词地读取一篇文本,得到特征集
* @param filePath
* @return 读取分词后的文本,得到出现在文本中的所有不重复的特征Set
*/
public static Set<String> toSet(String filePath){
Set<String> set=new HashSet<String>();
//String charset=getCharset(filePath);
try{
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(filePath),"utf-8"));
String s;
while((s=br.readLine())!=null){
set.add(s);
}
br.close();
}catch (IOException ex) {
Logger.getLogger(ReadTXT.class.getName()).log(Level.SEVERE, null, ex);
}
return set;
}
/**
* 一行一个词地读取一篇文本,得到特征列表,有重复的
* @param filePath
* @return 读取分词后的文本,得到出现在文本中的所有特征(有重复的)List
*/
public static List<String> toList(String filePath){
List<String> list=new ArrayList<String>();
//String charset=getCharset(filePath);
try{
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(filePath),"utf-8"));
String s;
while((s=br.readLine())!=null){
list.add(s);
}
br.close();
}catch (IOException ex) {
Logger.getLogger(ReadTXT.class.getName()).log(Level.SEVERE, null, ex);
}
return list;
}
/**
* 读取文件内容,返回一个特征-权重的Map
* @param filePath
* @return
*/
public static Map<String,Integer> toIntMap(String filePath){
Map<String,Integer> map=new HashMap<String,Integer>();
try{
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(filePath),"utf-8"));
String str;
while((str=br.readLine())!=null){//特征
String[] s=str.split(",");
String key=s[0];//特征
int value=Integer.parseInt(s[1]);//特征值
map.put(key, value);
}
br.close();
}catch (IOException ex) {
Logger.getLogger(ReadTXT.class.getName()).log(Level.SEVERE, null, ex);
}
return map;
}
/**
* 读取文件内容,返回一个特征-权重的Map
* @param filePath
* @return
*/
public static Map<String,Double> toDoubleMap(String filePath){
Map<String,Double> map=new HashMap<String,Double>();
try{
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(filePath),"utf-8"));
String str;
while((str=br.readLine())!=null){//特征
String[] s=str.split(",");
String key=s[0];//特征
double value=Double.parseDouble(s[1]);//特征值
map.put(key, value);
}
br.close();
}catch (IOException ex) {
Logger.getLogger(ReadTXT.class.getName()).log(Level.SEVERE, null, ex);
}
return map;
}
/**
* 获取文本集的TFIDF集
* @param filePath
* @return
*/
public static List<Text> readText(String filePath){
List<Text> textList=new ArrayList<Text>();
File path=new File(filePath);
File[] files=path.listFiles();//类别
int labelID=0;
for(File file: files){
File[] texts=file.listFiles();//文本
for(File text: texts){
String textPath=text.getAbsolutePath();
Text txt=new Text();
txt.setPath(textPath);//文本路径
txt.setOriginLabelID(labelID);//文本类别
txt.setWords(ReadTXT.toDoubleMap(textPath));//文本词向量
textList.add(txt);
}
labelID++;
}
return textList;
}
}12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
四、TXT写入类WriteTXT
/*
* To change this template, choose Tools | Templates
* and open the template in the editor.
*/
package util;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.logging.Level;
import java.util.logging.Logger;
/**
* 数据写入TXT类
* @author Angela
*/
public class WriteTXT {
/**
* 将字符串写入文本
* @param str 分词字符串
* @param tarPath 保存路径
*/
public static void write(String str,String tarPath){
try{
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(tarPath)));
bw.write(str);
bw.flush();
bw.close();
} catch (IOException ex) {
Logger.getLogger(WriteTXT.class.getName()).log(Level.SEVERE, null, ex);
}
}
/**
* 传入一篇文本分词后的特征表List,将List的内容一行一个特征地写入tarPath文件中(有重复)
* @param list 一篇文本分词后的结果:特征列表List
* @param tarPath 保存路径
*/
public static <K> void writeList(List<K> list,String tarPath){
try{
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(tarPath)));
for(K s: list){
bw.write(s.toString());
bw.newLine();
}
bw.flush();
bw.close();
} catch (IOException ex) {
Logger.getLogger(WriteTXT.class.getName()).log(Level.SEVERE, null, ex);
}
}
/**
* 传入一篇文本分词后的特征集Set,将Set的内容一行一个特征地写入tarPath文件中(无重复的)
* @param set 特征集Set
* @param tarPath 保存路径
*/
public static <K> void writeSet(Set<K> set,String tarPath){
try{
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(tarPath)));
for(K s: set){
bw.write(s.toString());
bw.newLine();
}
bw.flush();
bw.close();
} catch (IOException ex) {
Logger.getLogger(WriteTXT.class.getName()).log(Level.SEVERE, null, ex);
}
}
/**
* 传入一篇文本分词后的特征集Map,将Map的内容一行一个地写入tarPath文件中(无重复的)
* @param map 特征集Map
* @param tarPath 保存路径,将特征-特征值Map内容保存在tarPath文件中
*/
public static <K, V> void writeMap(Map<K, V> map,String tarPath){
try{
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(tarPath)));
for(Map.Entry<K,V> me: map.entrySet()){
//用逗号作为分隔符
bw.write(me.getKey()+","+me.getValue());
bw.newLine();
}
bw.flush();
bw.close();
} catch (IOException ex) {
Logger.getLogger(WriteTXT.class.getName()).log(Level.SEVERE, null, ex);
}
}
/**
* 得到所有数据集中所有不重复特征的文档频,一行一行地将特征-DF结果保存到tarPath中
* @param filePath 数据集路径,包含有所有文本的目录路径
* @param tarPath DF结果的保存路径
* @return 数据集的文本总数
*/
public static int saveDF(String filePath,String tarPath){
int sum=0;
Map<String,Integer> df=new HashMap<String,Integer>();
File dataSet=new File(filePath);
File[] classes=dataSet.listFiles();
for(File c: classes){//类别
File[] files=c.listFiles();
sum+=files.length;
for(File file: files){//文本
Map<String,Integer> tf=ReadTXT.toIntMap(file.getAbsolutePath());
for(Map.Entry<String, Integer> me: tf.entrySet()){
String f=me.getKey();
if(df.containsKey(f)){
df.put(f, df.get(f)+1);
}else{
df.put(f, 1);
}
}
}
}
//保存特征及其DF值
WriteTXT.writeMap(MapUtil.desc(df),tarPath);
return sum;
}
/**
* 读取DF结果文件,计算每个特征的IDF值,保存特征-IDF值到tarPath文件中
* @param filePath DF结果的文件路径
* @param tarPath IDF结果的保存路径
* @param n 总的文本数
*/
public static void saveIDF(String filePath,String tarPath,int n){
Map<String,Integer> df=ReadTXT.toIntMap(filePath);
Map<String,Double> idf=new HashMap<String,Double>();
for(Map.Entry<String, Integer> me: df.entrySet()){
idf.put(me.getKey(), Math.log(n*1.0/me.getValue()));
}
//保存特征及其IDF值
WriteTXT.writeMap(MapUtil.desc(idf),tarPath);
}
/**
* 主函数,保存分词后的DF、IDF结果
* @param args
*/
public static void main(String args[]){
//第一个参数为TF集路径,第二个参数为DF的保存路径,n为文本集文本总数
int n=saveDF("data\\trainTF","data\\trainDF.txt");
//System.out.println(n);
//第一个参数为DF文本,第二个参数为IDF的保存路径,n为文本集文本总数
saveIDF("data\\trainDF.txt","data\\trainIDF.txt",n);
}
}

相关文章推荐
- Python的网页爬虫&文本处理&科学计&机器学习&数据挖掘工具集
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
- Python的网页爬虫&文本处理&科学计&机器学习&数据挖掘工具集
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- 数据挖掘之文本特征提取【理论+部分java代码实现】
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- 字符串处理是许多程序中非常重要的一部分,它们可以用于文本显示,数据表示,查找键和很多目的.在Unix下,用户可以使用正则表达式的强健功能实现这些 目的,从Java1.4起,Java核心API就引入了java.util.regex程序包,它是一种有价值的基础
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱 - 数客
- java处理数据文本时间小函数积累
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱 - 数客
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱