MapReduce编程模型及优化技巧
2017-08-02 13:50
295 查看
(一)MapReduce 编程模型
(备注:如果你已经了解MapReduce 编程模型请直接进入第二部分MapReduce 的优化讲解) 在学习MapReduce 优化之前我们先来了解一下MapReduce 编程模型是怎样的? 下图中红色的标注表示没有加入Combiner和Partitioner来进行优化。
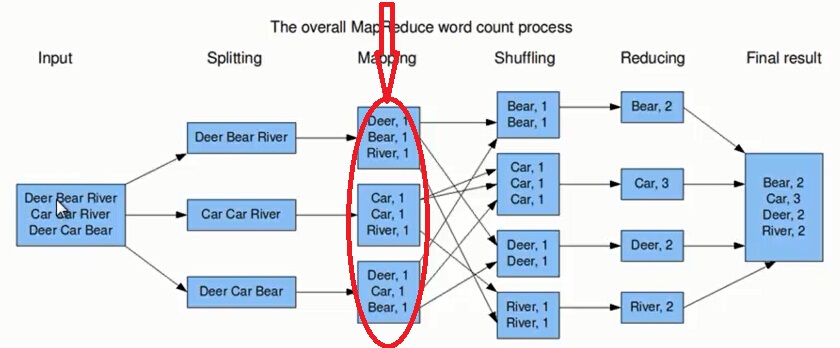
上图的流程大概分为以下几步。
第一步:假设一个文件有三行英文单词作为 MapReduce 的Input(输入),这里经过 Splitting 过程把文件分割为3块。分割后的3块数据就可以并行处理,每一块交给一个 map 线程处理。
第二步:每个 map 线程中,以每个单词为key,以1作为词频数value,然后输出。
第三步:每个 map 的输出要经过 shuffling(混洗),将相同的单词key放在一个桶里面,然后交给 reduce 处理。
第四步:reduce 接受到 shuffling 后的数据, 会将相同的单词进行合并,得到每个单词的词频数,最后将统计好的每个单词的词频数作为输出结果。
上述就是 MapReduce 的大致流程,前两步可以看做 map 阶段,后两步可以看做 reduce 阶段。下面我们来看看 MapReduce 大致实现。
1、Input:首先 MapReduce 输入的是一系列key/value对。key表示每行偏移量,value代表每行输入的单词。
2、用户提供了 map 函数和 reduce 函数的实现:
map(k,v) ——> list(k1,v1) reduce(k1,list(v1)) ——>(k2,v2)1
2
1
2
map 函数将每个单词转化为key/value对输出,这里key为每个单词,value为词频1。(k1,v1)是 map 输出的中间key/value结果对。reduce 将相同单词的所有词频进行合并,比如将单词k1,词频为list(v1),合并为(k2,v2)。reduce 合并完之后,最终输出一系列(k2,v2)键值对。
下面我们来看一下 MapReduce 的伪代码。
map(key,value)://map 函数,key代表偏移量,value代表每行单词 for each word w in value: //循环每行数据,输出每个单词和词频的键值对(w,1) emit(w,1) reduce(key,values)://reduce 函数,key代表一个单词,value代表这个单词的所有词频数集合 result=0 for each count v in values: //循环词频集合,求出该单词的总词频数,然后输出(key,result) result+=v emit(key,result)1
2
3
4
5
6
7
8
1
2
3
4
5
6
7
8
讲到这里,我们可以对 MapReduce 做一个总结。MapReduce 将 作业的整个运行过程分为两个阶段:Map 阶段和Reduce 阶段。
1、Map 阶段
Map 阶段是由一定数量的 Map Task 组成。这些 Map Task 可以同时运行,每个 Map Task又是由以下三个部分组成。
1) 对输入数据格式进行解析的一个组件:InputFormat。因为不同的数据可能存储的数据格式不一样,这就需要有一个 InputFormat 组件来解析这些数据的存放格式。默认情况下,它提供了一个 TextInputFormat 来解释数据格式。TextInputFormat 就是我们前面提到的文本文件输入格式,它会将文件的每一行解释成(key,value),key代表每行偏移量,value代表每行数据内容。 通常情况我们不需要自定义 InputFormat,因为 MapReduce 提供了很多种InputFormat的实现,我们根据不同的数据格式,选择不同的
InputFormat 来解释就可以了。这一点我们后面会讲到。
2)输入数据处理:Mapper。这个 Mapper 是必须要实现的,因为根据不同的业务对数据有不同的处理。
3)数据分组:Partitioner。Mapper 数据处理之后输出之前,输出key会经过 Partitioner 分组或者分桶选择不同的reduce。默认的情况下,Partitioner 会对 map 输出的key进行hash取模,比如有6个Reduce Task,它就是模(mod)6,如果key的hash值为0,就选择第0个 Reduce Task,如果key的hash值为1,就选择第一个 Reduce Task。这样不同的 map 对相同单词key,它的 hash 值取模是一样的,所以会交给同一个
reduce 来处理。
2、Reduce 阶段
1) 数据运程拷贝。Reduce Task 要运程拷贝每个 map 处理的结果,从每个 map 中读取一部分结果。每个 Reduce Task 拷贝哪些数据,是由上面 Partitioner 决定的。
2) 数据按照key排序。Reduce Task 读取完数据后,要按照key进行排序。按照key排序后,相同的key被分到一组,交给同一个 Reduce Task 处理。
3) 数据处理:Reducer。以WordCount为例,相同的单词key分到一组,交个同一个Reducer处理,这样就实现了对每个单词的词频统计。
4) 数据输出格式:OutputFormat。Reducer 统计的结果,将按照 OutputFormat 格式输出。默认情况下的输出格式为 TextOutputFormat,以WordCount为例,这里的key为单词,value为词频数。
从上图以及MapReduce 的作业的整个运行过程我们可以看出存在以下问题:
1)Map Task输出的数据量(即磁盘IO)大。Map Task 将输出的数据写到本地磁盘,它输出的数据量越多,它写入磁盘的数据量就越大,那么开销就越大,速度就越慢。
2)Reduce-Map网络传输的数据量(网络IO)大,浪费了大量的网络资源。
3)容易造成负载不均。
(二)MapReduce的优化技巧
Combiner和Partitioner是用来优化MapReduce的,可以提高MapReduce的运行效率。下面我们来具体学习这两个组件。Combiner
首先通过下面的示意图直观的了解一下Combiner的位置和作用。
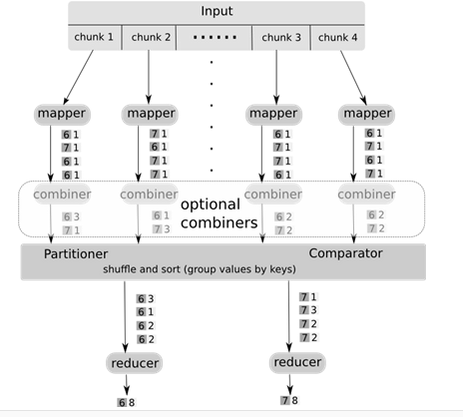
从上图可以看出,Combiner介于 Mapper和Reducer之间,combine作为 Map任务的一部分,执行完 map 函数后紧接着执行combine,而reduce 必须在所有的 Map 任务完成后才能进行。 而且还可以看出combine的过程与reduce的过程类似,都是对相同的单词key合并其词频,很多情况下可以直接使用reduce函数来完成Combiner过程。
1、通过上面的分析,下面我们将深入理解 Combiner组件。
1)Combiner可以看做局部的Reducer(local reducer)。
2)Combiner作用是合并相同的key对应的value。
3)在Mapper阶段,不管Combiner被调用多少次,都不应改变 Reduce的输出结果。
4)Combiner通常与Reducer的逻辑是一样的,一般情况下不需要单独编写Combiner,直接使用Reducer的实现就可以了。
5)Combiner在Job中是如下设置的。
job.setCombinerClass(Reducer.class);//Combiner一般情况下,默认使用Reducer的实现1
1
2、Combiner的优点
1)能够减少Map Task输出的数据量(即磁盘IO)。
2)能够减少Reduce-Map网络传输的数据量(网络IO)。这个很好理解,Map Task 输出越少,Reduce从Map结果中拉取的数据量就越少,自然就减少了网络传输的数据量。
3、Combiner 的使用场景
1)并不是所有的场景都可以使用Combiner,必须满足结果可以累加。
2)适合于Sum()求和,并不适合Average()求平均数。例如,求0、20、10、25和15的平均数,直接使用Reduce求平均数Average(0,20,10,25,15),得到的结果是14, 如果先使用Combiner分别对不同Mapper结果求平均数,Average(0,20,10)=10,Average(25,15)=20,再使用Reducer求平均数Average(10,20),得到的结果为15,很明显求平均数并不适合使用Combiner。
Partitioner
我们通过如下示意图,很直观的看到 Partitioner 的位置和作用。
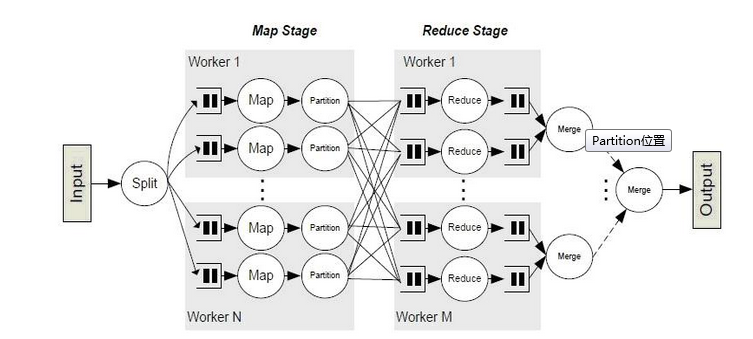
从上图我们可以看出,Partitioner 处于 Mapper阶段,当Mapper处理好数据后,这些数据需要经过Partitioner进行分区,来选择不同的Reducer处理,从而将Mapper的输出结果均匀的分布在Reducer上面执行。
通过上面的分析,下面我们将深入理解 Partitioner组件。
1、Partitioner决定了Map Task 输出的每条数据交给哪个Reduce Task 来处理。Partitioner 有两个功能:
1) 均衡负载。它尽量将工作均匀地分配给不同的 Reduce。
2)效率。它的分配速度一定要非常快。
2、Partitioner 的默认实现:hash(key) mod R,这里的R代表Reduce Task 的数目,意思就是对key进行hash处理然后取模。很多情况下,用户需要自定义 Partitioner,比如“hash(hostname(URL)) mod R”,它确保相同域名下的网页交给同一个 Reduce Task 来处理。 用户自定义Partitioner,需要继承Partitioner类,实现它提供的一个方法。示例代码:
package com.ywendeng.hadoop.flowSort;
import java.util.HashMap;
import org.apache.hadoop.mapreduce.Partitioner;
//对号码进行分组
public class AreaPartitioner<KEY, VALUE> extends Partitioner<KEY, VALUE>{
private static HashMap<String,Integer>map=new HashMap<>();;
static{
//hashMap对应的数据词典 key = 0;
map.put("135", 0);
map.put("136", 1);
map.put("137", 2);
map.put("138", 3);
map.put("139", 4);
}
@Override
public int getPartition(KEY key, VALUE value, int args) {
return map.get(key.toString().substring(0,3)==null?5:key.toString().substring(0,3));
}
}12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
前两个参数分别为Map的key和value。args 为 Reduce 的个数,用户可以自己设置。

相关文章推荐
- Unity 实用技巧 之 C#编程优化——枚举
- MapReduce 编程模型在日志分析方面的应用
- Linux C 编程技巧--利用有限状态机模型编程
- MapReduce 编程模型概述
- Hadoop ->> MapReduce编程模型
- MapReduce 编程模型
- 分布式队列编程:从模型、实战到优化(转)
- MapReduce 编程模型在日志分析方面的应用
- 【编程技巧】——输入输出优化
- Android编程开发之性能优化技巧总结
- 我是菜鸟:MapReduce编程模型
- VR模型优化技巧
- T-SQL 编程规范和优化技巧
- 浅谈C语言编程中程序的一些基本的编写优化技巧
- MAPREDUCE 编程模型理解
- Android 用户界面编程技巧和设计模式(性能优化)
- CS231n 卷积神经网络与计算机视觉 7 神经网络训练技巧汇总 梯度检验 参数更新 超参数优化 模型融合 等
- 理解高并发(7).编程过程中锁的优化技巧
- MapReduce 编程模型概述
- MapReduce编程模型--接口体系结构--架构设计--《hadoop技术内幕》读书笔记