Spark SQL笔记——技术点汇总
2017-07-31 23:17
549 查看
http://www.cnblogs.com/netoxi/p/7223413.html
· 原理
· 组成
· 执行流程
· 性能
· API
· 应用程序模板
· 通用读写方法
· RDD转为DataFrame
· Parquet文件数据源
· JSON文件数据源
· Hive数据源
· 数据库JDBC数据源
· DataFrame Operation
· 性能调优
· 缓存数据
· 参数调优
· 案例
· 数据准备
· 查询部门职工数
· 查询各部门职工工资总数,并排序
· 查询各部门职工考勤信息
2. Spark SQL特点
a) 数据兼容:可从Hive表、外部数据库(JDBC)、RDD、Parquet文件、JSON文件获取数据,可通过Scala方法或SQL方式操作这些数据,并把结果转回RDD。
b) 组件扩展:SQL语法解析器、分析器、优化器均可重新定义。
c) 性能优化:内存列存储、动态字节码生成等优化技术,内存缓存数据。
d) 多语言支持:Scala、Java、Python、R。
2. Spark SQL内核:处理数据的输入输出,从不同数据源(结构化数据Parquet文件JSON文件、Hive表、外部数据库、已有RDD)获取数据,执行查询(expression of queries),并将查询结果输出成DataFrame。
3. Hive支持:对Hive数据的处理,主要包括HiveQL、MetaStore、SerDes、UDFs等。

1. SqlParser对SQL语句解析,生成Unresolved逻辑计划(未提取Schema信息);
2. Catalyst分析器结合数据字典(catalog)进行绑定,生成Analyzed逻辑计划,过程中Schema Catalog要提取Schema信息;
3. Catalyst优化器对Analyzed逻辑计划优化,按照优化规则得到Optimized逻辑计划;
4. 与Spark Planner交互,应用策略(strategy)到plan,使用Spark Planner将逻辑计划转换成物理计划,然后调用next函数,生成可执行物理计划。
2. 动态代码和字节码生成技术:提升重复表达式求值查询的速率。
3. Tungsten优化:
a) 由Spark自己管理内存而不是JVM,避免了JVM GC带来的性能损失。
b) 内存中Java对象被存储成Spark自己的二进制格式,直接在二进制格式上计算,省去序列化和反序列化时间;此格式更紧凑,节省内存空间。
2. 保存模式:
3. 读写文件代码(统一使用sqlContext.read和dataFrame.write)模板:
a) 方法:使用反射机制推断RDD Schema。
b) 场景:运行前知道Schema。
c) 特点:代码简洁。
d) 示例:
2. 方法2
a) 方法:以编程方式定义RDD Schema。
b) 场景:运行前不知道Schema。
c) 示例:
a) 高效、Parquet采用列式存储避免读入不需要的数据,具有极好的性能和GC;
b) 方便的压缩和解压缩,并具有极好的压缩比例;
c) 可直接读写Parquet文件,比磁盘更好的缓存效果。
2. Spark SQL支持根据Parquet文件自描述自动推断Schema,生成DataFrame。
3. 编程示例:
4. 分区发现(partition discovery)
a) 与Hive分区表类似,通过分区列的值对表设置分区目录,加载Parquet数据源可自动发现和推断分区信息。
b) 示例:有一个分区列为gender和country的分区表,加载路径“/path/to/table”可自动提取分区信息
创建的DataFrame的Schema:
c) 分区列数据类型:支持numeric和string类型的自动推断,通过“spark.sql.sources.partitionColumnTypeInference.enabled”配置开启或关闭(默认开启),关闭后分区列全为string类型。
2. 示例:
a) 操作Hive数据源须创建SQLContext的子类HiveContext对象。
b) Standalone集群:添加hive-site.xml到$SPARK_HOME/conf目录。
c) YARN集群:添加hive-site.xml到$YARN_CONF_DIR目录;添加Hive元数据库JDBC驱动jar文件到$HADOOP_HOME/lib目录。
d) 最简单方法:通过spark-submit命令参数--file和--jar参数分别指定hive-site.xml和Hive元数据库JDBC驱动jar文件。
e) 未找到hive-site.xml:当前目录下自动创建metastore_db和warehouse目录。
f) 模板:
2. 使用HiveQL
a) “spark.sql.dialect”配置:SQLContext仅sql,HiveContext支持sql、hiveql(默认)。
b) 模板:
3. 支持Hive特性
a) Hive查询语句,包括select、group by、order by、cluster by、sort by;
b) Hive运算符,包括:关系运算符(=、⇔、==、<>、<、>、>=、<=等)、算术运算符(+、-、*、/、%等)、逻辑运算符(and、&&、or、||等)、复杂类型构造函数、数据函数(sign、ln、cos等)、字符串函数(instr、length、printf);
c) 用户自定义函数(UDF);
d) 用户自定义聚合函数(UDAF);
e) 用户自定义序列化格式(SerDes);
f) 连接操作,包括join、{left | right | full} outer join、left semi join、cross join;
g) 联合操作(union);
h) 子查询:select col from (select a + b as col from t1) t2;
i) 抽样(Sampling);
j) 解释(Explain);
k) 分区表(Partitioned table);
l) 所有Hive DDL操作函数,包括create table、create table as select、alter table;
m) 大多数Hive数据类型tinyint、smallint、int、bigint、boolean、float、double、string、binary、timestamp、date、array<>、map<>、struct<>。
2. 模板(注意:需要相关JDBC驱动jar文件)
3. JDBC参数
a) DataFrameAction
b) 基础DataFrame函数(basic DataFrame functions)
c) 集成语言查询(language integrated queries)
d) 输出操作
e) RDD Operation
DataFrame本质是一个拥有多个分区的RDD,支持RDD Operation:coalesce、flatMap、foreach、foreachPartition、javaRDD、map、mapPartitions、repartition、toJSON、toJavaRDD等。
2. 相关配置:
3. 缓存/移除缓存代码模板:
a) 职工基本信息(people)
b) 部门基本信息(department)
c) 职工考勤信息(attendance)
d) 职工工资清单(salary)
2. 建库、建表(spark-shell方式)
3. 测试数据
a) 职工基本信息(people.csv)
b) 部门基本信息(department.csv)
c) 职工考勤信息(attendance.csv)
d) 职工工资清单(salary.csv)
4. 上传数据文件至HDFS
2. Scala方式
3. 结果
2. Scala方式
3. 结果

2. Scala方式
3. 结果
目录
· 概述· 原理
· 组成
· 执行流程
· 性能
· API
· 应用程序模板
· 通用读写方法
· RDD转为DataFrame
· Parquet文件数据源
· JSON文件数据源
· Hive数据源
· 数据库JDBC数据源
· DataFrame Operation
· 性能调优
· 缓存数据
· 参数调优
· 案例
· 数据准备
· 查询部门职工数
· 查询各部门职工工资总数,并排序
· 查询各部门职工考勤信息
概述
1. Spark SQL是Spark的结构化数据处理模块。2. Spark SQL特点
a) 数据兼容:可从Hive表、外部数据库(JDBC)、RDD、Parquet文件、JSON文件获取数据,可通过Scala方法或SQL方式操作这些数据,并把结果转回RDD。
b) 组件扩展:SQL语法解析器、分析器、优化器均可重新定义。
c) 性能优化:内存列存储、动态字节码生成等优化技术,内存缓存数据。
d) 多语言支持:Scala、Java、Python、R。
原理
组成
1. Catalyst优化:优化处理查询语句的整个过程,包括解析、绑定、优化、物理计划等,主要由关系代数(relation algebra)、表达式(expression)以及查询优化(query optimization)组成。2. Spark SQL内核:处理数据的输入输出,从不同数据源(结构化数据Parquet文件JSON文件、Hive表、外部数据库、已有RDD)获取数据,执行查询(expression of queries),并将查询结果输出成DataFrame。
3. Hive支持:对Hive数据的处理,主要包括HiveQL、MetaStore、SerDes、UDFs等。
执行流程
1. SqlParser对SQL语句解析,生成Unresolved逻辑计划(未提取Schema信息);
2. Catalyst分析器结合数据字典(catalog)进行绑定,生成Analyzed逻辑计划,过程中Schema Catalog要提取Schema信息;
3. Catalyst优化器对Analyzed逻辑计划优化,按照优化规则得到Optimized逻辑计划;
4. 与Spark Planner交互,应用策略(strategy)到plan,使用Spark Planner将逻辑计划转换成物理计划,然后调用next函数,生成可执行物理计划。
性能
1. 内存列式缓存:内存列式(in-memory columnar format)缓存(再次执行时无需重复读取),仅扫描需要的列,并自动调整压缩比使内存使用率和GC压力最小化。2. 动态代码和字节码生成技术:提升重复表达式求值查询的速率。
3. Tungsten优化:
a) 由Spark自己管理内存而不是JVM,避免了JVM GC带来的性能损失。
b) 内存中Java对象被存储成Spark自己的二进制格式,直接在二进制格式上计算,省去序列化和反序列化时间;此格式更紧凑,节省内存空间。
API
应用程序模板
1 import org.apache.spark.SparkConf
2 import org.apache.spark.SparkContext
3 import org.apache.spark.sql.SQLContext
4 import org.apache.spark.sql.hive.HiveContext
5
6 object Test {
7 def main(args: Array[String]): Unit = {
8 val conf = new SparkConf().setAppName("Test")
9 val sc = new SparkContext(conf)
10 val sqlContext = new HiveContext(sc)
11
12 // ...
13 }
14 }通用读写方法
1. Spark SQL内置数据源短名称有json、parquet、jdbc,默认parquet(通过“spark.sql.sources.default”配置)。2. 保存模式:
| Scala/Java | Python | 说明 |
| SaveMode.ErrorIfExists | "error" | 默认,如果数据库已经存在,抛出异常 |
| SaveMode.Append | "append" | 如果数据库已经存在,追加DataFrame数据 |
| SaveMode.Overwrite | "overwrite" | 如果数据库已经存在,重写DataFrame数据 |
| SaveMode.Ignore | "ignore" | 如果数据库已经存在,忽略DataFrame数据 |
1 val dataFrame = sqlContext.read.format("数据源名称").load("文件路径")
2 val newDataFrame = dataFrame // 操作数据得到新DataFrame
3 newDataFrame.write.format("数据源名称").save("文件路径")RDD转为DataFrame
1. 方法1a) 方法:使用反射机制推断RDD Schema。
b) 场景:运行前知道Schema。
c) 特点:代码简洁。
d) 示例:
1 import org.apache.spark.SparkConf
2 import org.apache.spark.SparkContext
3 import org.apache.spark.sql.SQLContext
4
5 object Test {
6
7 def main(args: Array[String]): Unit = {
8 val conf = new SparkConf().setAppName("Test")
9 val sc = new SparkContext(conf)
10 val sqlContext = new SQLContext(sc)
11
12 // 将一个RDD隐式转换为一个DataFrame
13 import sqlContext.implicits._
14 // 使用case定义Schema(不能超过22个属性)
15 case class Person(name: String, age: Int)
16 // 读取文件创建MappedRDD,再将数据写入Person类,隐式转换为DataFrame
17 val peopleDF = sc.textFile("/test/people.csv").map(_.split(",")).map(cols => Person(cols(0), cols(1).trim.toInt)).toDF()
18 // DataFrame注册临时表
19 peopleDF.registerTempTable("table_people")
20
21 // SQL
22 val teenagers = sqlContext.sql("select name, age from table_people where age >= 13 and age <= 19")
23 teenagers.collect.foreach(println)
24 }
25
26 }2. 方法2
a) 方法:以编程方式定义RDD Schema。
b) 场景:运行前不知道Schema。
c) 示例:
1 import org.apache.spark.SparkConf
2 import org.apache.spark.SparkContext
3 import org.apache.spark.sql.SQLContext
4 import org.apache.spark.sql.types.StructType
5 import org.apache.spark.sql.types.StringType
6 import org.apache.spark.sql.types.StructField
7 import org.apache.spark.sql.Row
8
9 object Test {
10
11 def main(args: Array[String]): Unit = {
12 val conf = new SparkConf().setAppName("Test")
13 val sc = new SparkContext(conf)
14 val sqlContext = new SQLContext(sc)
15
16 // 将一个RDD隐式转换为一个DataFrame
17 import sqlContext.implicits._
18 // 使用case定义Schema(不能超过22个属性)
19 case class Person(name: String, age: Int)
20 // 读取文件创建MappedRDD
21 val peopleFile = sc.textFile("/test/people.csv")
22 // 运行时从某处获取的Schema结构
23 val schemaArray = Array("name", "age")
24 // 创建Schema
25 val schema = StructType(schemaArray.map(fieldName => StructField(fieldName, StringType, true)))
26 // 将文本转为RDD
27 val rowRDD = peopleFile.map(_.split(",")).map(cols => Row(cols(0), cols(1).trim))
28 // 将Schema应用于RDD
29 val peopleDF = sqlContext.createDataFrame(rowRDD, schema)
30 // DataFrame注册临时表
31 peopleDF.registerTempTable("table_people")
32
33 // SQL
34 val teenagers = sqlContext.sql("select name, age from table_people where age >= 13 and age <= 19")
35 teenagers.collect.foreach(println)
36 }
37
38 }Parquet文件数据源
1. Parquet优点:a) 高效、Parquet采用列式存储避免读入不需要的数据,具有极好的性能和GC;
b) 方便的压缩和解压缩,并具有极好的压缩比例;
c) 可直接读写Parquet文件,比磁盘更好的缓存效果。
2. Spark SQL支持根据Parquet文件自描述自动推断Schema,生成DataFrame。
3. 编程示例:
1 // 加载文件创建DataFrame
2 val peopleDF = sqlContext.read.load("/test/people.parquet")
3 peopleDF.printSchema
4 // DataFrame注册临时表
5 peopleDF.registerTempTable("table_people")
6
7 // SQL
8 val teenagers = sqlContext.sql("select name, age from table_people where age >= 13 and age <= 19")
9 teenagers.collect.foreach(println)4. 分区发现(partition discovery)
a) 与Hive分区表类似,通过分区列的值对表设置分区目录,加载Parquet数据源可自动发现和推断分区信息。
b) 示例:有一个分区列为gender和country的分区表,加载路径“/path/to/table”可自动提取分区信息
path └── to └── table ├── gender=male │ ├── ... │ │ │ ├── country=US │ │ └── data.parquet │ ├── country=CN │ │ └── data.parquet │ └── ... └── gender=female ├── ... │ ├── country=US │ └── data.parquet ├── country=CN │ └── data.parquet └── ...
创建的DataFrame的Schema:
root |-- name: string (nullable = true) |-- age: long (nullable = true) |-- gender: string (nullable = true) |-- country: string (nullable = true)
c) 分区列数据类型:支持numeric和string类型的自动推断,通过“spark.sql.sources.partitionColumnTypeInference.enabled”配置开启或关闭(默认开启),关闭后分区列全为string类型。
JSON文件数据源
1. Spark SQL支持根据JSON文件自描述自动推断Schema,生成DataFrame。2. 示例:
1 // 加载文件创建DataFrame(JSON文件自描述Schema)
2 val peopleDF = sqlContext.read.format("json").load("/test/people.json")
3 peopleDF.printSchema
4 // DataFrame注册临时表
5 peopleDF.registerTempTable("table_people")
6
7 // SQL
8 val teenagers = sqlContext.sql("select name, age from table_people where age >= 13 and age <= 19")
9 teenagers.collect.foreach(println)Hive数据源
1. HiveContexta) 操作Hive数据源须创建SQLContext的子类HiveContext对象。
b) Standalone集群:添加hive-site.xml到$SPARK_HOME/conf目录。
c) YARN集群:添加hive-site.xml到$YARN_CONF_DIR目录;添加Hive元数据库JDBC驱动jar文件到$HADOOP_HOME/lib目录。
d) 最简单方法:通过spark-submit命令参数--file和--jar参数分别指定hive-site.xml和Hive元数据库JDBC驱动jar文件。
e) 未找到hive-site.xml:当前目录下自动创建metastore_db和warehouse目录。
f) 模板:
val sqlContext = new HiveContext(sc)
2. 使用HiveQL
a) “spark.sql.dialect”配置:SQLContext仅sql,HiveContext支持sql、hiveql(默认)。
b) 模板:
sqlContext.sql("HiveQL")3. 支持Hive特性
a) Hive查询语句,包括select、group by、order by、cluster by、sort by;
b) Hive运算符,包括:关系运算符(=、⇔、==、<>、<、>、>=、<=等)、算术运算符(+、-、*、/、%等)、逻辑运算符(and、&&、or、||等)、复杂类型构造函数、数据函数(sign、ln、cos等)、字符串函数(instr、length、printf);
c) 用户自定义函数(UDF);
d) 用户自定义聚合函数(UDAF);
e) 用户自定义序列化格式(SerDes);
f) 连接操作,包括join、{left | right | full} outer join、left semi join、cross join;
g) 联合操作(union);
h) 子查询:select col from (select a + b as col from t1) t2;
i) 抽样(Sampling);
j) 解释(Explain);
k) 分区表(Partitioned table);
l) 所有Hive DDL操作函数,包括create table、create table as select、alter table;
m) 大多数Hive数据类型tinyint、smallint、int、bigint、boolean、float、double、string、binary、timestamp、date、array<>、map<>、struct<>。
数据库JDBC数据源
1. Spark SQL支持加载数据库表生成DataFrame。2. 模板(注意:需要相关JDBC驱动jar文件)
val jdbcOptions = Map("url" -> "", "driver" -> "", "dbtable" -> "")
sqlContext.read.format("jdbc").options(jdbcOptions).load3. JDBC参数
| 名称 | 说明 |
| url | The JDBC URL to connect to. |
| dbtable | The JDBC table that should be read. Note that anything that is valid in a FROM clause of a SQL query can be used. For example, instead of a full table you could also use a subquery in parentheses. |
| driver | The class name of the JDBC driver to use to connect to this URL. |
| partitionColumn, lowerBound, upperBound, numPartitions | These options must all be specified if any of them is specified. They describe how to partition the table when reading in parallel from multiple workers. partitionColumn must be a numeric column from the table in question. Notice that lowerBound and upperBound are just used to decide the partition stride, not for filtering the rows in table. So all rows in the table will be partitioned and returned. |
| fetchSize | The JDBC fetch size, which determines how many rows to fetch per round trip. This can help performance on JDBC drivers which default to low fetch size (eg. Oracle with 10 rows). |
DataFrame Operation
1. 分类:a) DataFrameAction
| 名称 | 说明 |
| collect: Array[Row] | 以Array形式返回DataFrame的所有Row |
| collectAsList: List[Row] | 以List形式返回DataFrame的所有Row |
| count(): Long | 返回DataFrame的Row数目 |
| first(): Row | 返回第一个Row |
| head(): Row | 返回第一个Row |
| show(): Unit | 以表格形式显示DataFrame的前20个Row |
| take(n: Int): Array[Row] | 返回DataFrame前n个Row |
| 名称 | 说明 |
| cache(): DataFrame.this.type | 缓存DataFrame |
| columns: Array[String] | 以Array形式返回全部的列名 |
| dtypes: Array[(String, String)] | 以Array形式返回全部的列名和数据类型 |
| explain: Unit | 打印physical plan到控制台 |
| isLocal: Boolean | 返回collect和take是否可以本地运行 |
| persist(newLevel: StorageLevel: DataFrame.this.type | 根据StorageLevel持久化 |
| printSchema(): Unit | 以树格式打印Schema |
| registerTempTable(tableName: String): Unit | 使用给定的名字注册DataFrame为临时表 |
| schema: StructType | 返回DataFrame的Schema |
| toDF(colNames: String*): DataFrame | 返回一个重新指定column的DataFrame |
| unpersist(): DataFrame.this.type | 移除持久化 |
| 名称 | 说明 |
| agg(aggExpr: (String, String), aggExpr: (String, String)*): DataFrame agg(exprs: Map[String, String]): DataFrame agg(expr: Column, exprs: Column*): DataFrame | 在整体DataFrame不分组聚合 |
| apply(colName: String): Column | 以Column形式返回列名为colName的列 |
| as(alias: String): DataFrame as(alias: Symbol): DataFrame | 以一个别名集方式返回一个新DataFrame |
| col(colName: String): Column | 同apply |
| cube(col: String, cols: String*): GroupedData | 使用专门的列(以便聚合),给当前DataFrame创建一个多维数据集 |
| distinct: DataFrame | 对Row去重,返回新DataFrame |
| drop(col: Column): DataFrame | 删除一个列,返回新DataFrame |
| except(other: DataFrame): DataFrame | 集合差,返回新DataFrame |
| filter(conditionExpr: String): DataFrame filter(condition: Column): DataFrame | 使用给定的SQL表达式过滤 |
| groupBy(col: String, cols: String*): GroupedData | 使用给定的列分组DataFrame,以便能够聚合 |
| intersect(other: DataFrame): DataFrame | 交集,返回新DataFrame |
| limit(n: Int): DataFrame | 获取前n行数据,返回新DataFrame |
| join(right: DataFrame):DataFrame join(right: DataFrame, joinExprs: Column):DataFrame join(right: DataFrame, joinExprs: Column, joinType: String):DataFrame | Join,第1个为笛卡尔积(Cross Join),第2个为Inner Join |
| orderBy(col: String, cols: String*): DataFrame orderBy(sortExprs: Columns*): DataFrame | 使用给定表达式排序,返回新DataFrame |
| sample(withReplacement: Boolean, fraction: Double): DataFrame | 使用随机种子,抽样部分行返回新DataFrame |
| select(col: String, cols: String*): DataFrame select(cols: Column*): DataFrame selectExpr(exprs: String*): DataFrame | 选择一个列集合 |
| sort(col: String, cols: String*): DataFrame sort(sortExprs: Column*): DataFrame | 同orderBy |
| unionAll(other: DataFrame): DataFrame | 集合和,返回新DataFrame |
| where(conditionExpr: String): DataFrame where(condition: Column): DataFrame | 同filter |
| withColumn(colName, col: Column) | 添加新列,返回新DataFrame |
| withColumnRenamed(existingName: String, newName: String) | 重命名列,返回新DataFrame |
| 名称 | 说明 |
| write | 保存DataFrame内容到外部文件存储、Hive表: dataFrame.write.save("路径") // 默认Parquet数据源 dataFrame.write.format("数据源名称").save("路径") dataFrame.write.saveAsTable("表名") dataFrame.write.insertInto("表名") |
DataFrame本质是一个拥有多个分区的RDD,支持RDD Operation:coalesce、flatMap、foreach、foreachPartition、javaRDD、map、mapPartitions、repartition、toJSON、toJavaRDD等。
性能调优
缓存数据
1. 内存列式(in-memory columnar format)缓存:Spark SQL仅扫描需要的列,并自动调整压缩比使内存使用率和GC压力最小化。2. 相关配置:
| 名称 | 默认值 | 说明 |
| spark.sql.inMemoryColumnarStorage.compressed | true | true时,Spark SQL基于数据统计为每列自动选择压缩编码 |
| spark.sql.inMemoryColumnarStorage.batchSize | 10000 | 控制内存列式缓存的批处理大小,大批量可提升内存使用率,但会增加内存溢出风险 |
// 缓存方法1(lazy)
sqlContext.cacheTable("表名")
// 缓存方法2(lazy)
dataFrame.cache()
// 移除缓存(eager)
sqlContext.uncacheTable("表名")
// 注意:RDD的cache方法不是列式缓存
rdd.cache()参数调优
| 名称 | 默认值 | 说明 |
| spark.sql.autoBroadcastJoinThreshold | 10485760 (10MB) | 当执行Join时,对一个将要被广播到所有Worker的表配置最大字节,通过设置为-1禁止广播 |
| spark.sql.tungsten.enabled | true | 配置是否开启Tungsten优化,默认开启 |
| spark.sql.shuffle.partitions | 200 | 当执行Join或Aggregation进行Shuffle时,配置可用分区数 |
案例
数据准备
1. 数据结构a) 职工基本信息(people)
| 字段 | 说明 |
| name | 姓名 |
| id | ID |
| gender | 性别 |
| age | 年龄 |
| year | 入职年份 |
| position | 职位 |
| deptid | 所在部门ID |
| 字段 | 说明 |
| name | 名称 |
| deptid | ID |
| 字段 | 说明 |
| id | 职工ID |
| year | 年 |
| month | 月 |
| overtime | 加班 |
| latetime | 迟到 |
| absenteeism | 旷工 |
| leaveearlytime | 早退小时 |
| 字段 | 说明 |
| id | 职工ID |
| salary | 工资 |
1 sqlContext.sql("create database hrs")
2 sqlContext.sql("use hrs")
3 sqlContext.sql("create external table if not exists people(name string, id int, gender string, age int, year int, position string, deptid int) row format delimited fields terminated by ',' lines terminated by '\n' location '/test/hrs/people'")
4 sqlContext.sql("create external table if not exists department(name string, deptid int) row format delimited fields terminated by ',' lines terminated by '\n' location '/test/hrs/department'")
5 sqlContext.sql("create external table if not exists attendance(id int, year int, month int, overtime int, latetime int, absenteeism int, leaveearlytime int) row format delimited fields terminated by ',' lines terminated by '\n' location '/test/hrs/attendance'")
6 sqlContext.sql("create external table if not exists salary(id int, salary int) row format delimited fields terminated by ',' lines terminated by '\n' location '/test/hrs/salary'")3. 测试数据
a) 职工基本信息(people.csv)
Michael,1,male,37,2001,developer,2 Andy,2,female,33,2003,manager,1 Justin,3,female,23,2013,recruitingspecialist,3 John,4,male,22,2014,developer,2 Herry,5,male,27,2010,developer,1 Brewster,6,male,37,2001,manager,2 Brice,7,female,30,2003,manager,3 Justin,8,male,23,2013,recruitingspecialist,3 John,9,male,22,2014,developer,1 Herry,10,female,27,2010,recruitingspecialist,3
b) 部门基本信息(department.csv)
manager,1 researchhanddevelopment,2 humanresources,3
c) 职工考勤信息(attendance.csv)
1,2015,12,0,2,4,0 2,2015,8,5,0,5,3 3,2015,3,16,4,1,5 4,2015,3,0,0,0,0 5,2015,3,0,3,0,0 6,2015,3,32,0,0,0 7,2015,3,0,16,3,32 8,2015,19,36,0,0,0 9,2015,5,6,30,0,2 10,2015,10,6,56,40,0 1,2014,12,0,2,4,0 2,2014,8,5,0,5,3 3,2014,3,16,4,1,5 4,2014,3,0,0,0,0 5,2014,3,0,3,0,0 6,2014,3,32,0,0,0 7,2014,3,0,16,3,32 8,2014,19,36,0,0,0 9,2014,5,6,30,0,2 10,2014,10,6,56,40,0
d) 职工工资清单(salary.csv)
1,5000 2,10000 3,6000 4,7000 5,5000 6,11000 7,12000 8,5500 9,6500 10,4500
4. 上传数据文件至HDFS
hadoop fs -mkdir /test/hrs/people hadoop fs -mkdir /test/hrs/department hadoop fs -mkdir /test/hrs/attendance hadoop fs -mkdir /test/hrs/salary hadoop fs -put people.csv /test/hrs/people hadoop fs -put department.csv /test/hrs/department hadoop fs -put attendance.csv /test/hrs/attendance hadoop fs -put salary.csv /test/hrs/salary
查询部门职工数
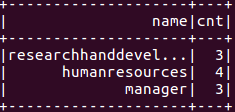
1. HiveQL方式1 sqlContext.sql("select d.name, count(p.id) from people p join department d on p.deptid = d.deptid group by d.name").show2. Scala方式
1 val peopleDF = sqlContext.table("people")
2 val departmentDF = sqlContext.table("department")
3 peopleDF.join(departmentDF, peopleDF("deptid") === departmentDF("deptid")).groupBy(departmentDF("name")).agg(count(peopleDF("id")).as("cnt")).select(departmentDF("name"), col("cnt")).show3. 结果
查询各部门职工工资总数,并排序
1. HiveQL方式1 sqlContext.sql("select d.name, sum(s.salary) as salarysum from people p join department d on p.deptid = d.deptid join salary s on p.id = s.id group by d.name order by salarysum").show2. Scala方式
1 val peopleDF = sqlContext.table("people")
2 val departmentDF = sqlContext.table("department")
3 val salaryDF = sqlContext.table("salary")
4 peopleDF.join(departmentDF, peopleDF("deptid") === departmentDF("deptid")).join(salaryDF, peopleDF("id") === salaryDF("id")).groupBy(departmentDF("name")).agg(sum(salaryDF("salary")).as("salarysum")).orderBy("salarysum").select(departmentDF("name"), col("salarysum")).show3. 结果
查询各部门职工考勤信息
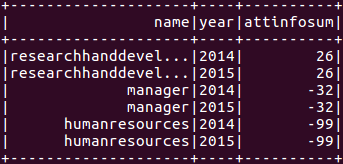
1. HiveQL方式1 sqlContext.sql("select d.name, ai.year, sum(ai.attinfo) from (select p.id, p.deptid, a.year, a.month, (a.overtime - a.latetime - a.absenteeism - a.leaveearlytime) as attinfo from attendance a join people p on a.id = p.id) ai join department d on ai.deptid = d.deptid group by d.name, ai.year").show2. Scala方式
1 val attendanceDF = sqlContext.table("attendance")
2 val peopleDF = sqlContext.table("people")
3 val departmentDF = sqlContext.table("department")
4 val subqueryDF = attendanceDF.join(peopleDF, attendanceDF("id") === peopleDF("id")).select(peopleDF("id"), peopleDF("deptid"), attendanceDF("year"), attendanceDF("month"), (attendanceDF("overtime") - attendanceDF("latetime") - attendanceDF("absenteeism") - attendanceDF("leaveearlytime")).as("attinfo"))
5 subqueryDF.join(departmentDF, subqueryDF("deptid") === departmentDF("deptid")).groupBy(departmentDF("name"), subqueryDF("year")).agg(sum(subqueryDF("attinfo")).as("attinfosum")).select(departmentDF("name"), subqueryDF("year"), col("attinfosum")).show3. 结果

相关文章推荐
- Spark Streaming笔记——技术点汇总
- Spark笔记——技术点汇总
- Spark Streaming笔记——技术点汇总
- 第61课:SparkSQl数据加载和保存内幕深度解密实战学习笔记
- 第62课:SparkSQL下的Parquet使用最佳实践和代码实践学习笔记
- 《Microsoft SQL Server 2005技术内幕》系列资源汇总
- JVM笔记——技术点汇总
- 第69课:SparkSQL通过Hive数据源实战学习笔记
- SQL笔记(9)_第九章 汇总查询得到的数据
- Spark-Sql版本升级对应的新特性汇总
- SQL Server 2008技术内幕:T-SQL语言基础 笔记
- JavaWeb学习笔记之Mybatis实用sql语句汇总
- Spark学习笔记——文本处理技术
- SQL Server 2008技术内幕:T-SQL语言基础 笔记
- Spark SQL Relational Data Processing in Spark (学习笔记)
- 区块链技术,比特币技术的汇总笔记
- spark2.2官方教程笔记-Spark SQL, DataFrames and Datasets向导
- (笔记)《SQL 2005 技术内幕 T-SQL查询》第一章 逻辑查询处理
- 关于mysql的sql语句的汇总(学习笔记)03(mysql高级应用)
- 笔记-Microsoft SQL Server 2008技术内幕:T-SQL语言基础-06 集合运算