Python网络爬虫之BeautifulSoup库
2017-07-28 12:00
375 查看
Python网络爬虫之BeautifulSoup库
BeautifulSoup是Python的第三方库,可以对HTML和XML格式的内容进行解析,并且提取其中的相关信息。BS可以对被提供的任何格式的内容进行爬取,并且进行树形解析。1.BeautifulSoup库的安装
它的安装也可以利用pip命令。首先使用管理员权限启动cmd命令台,然后使用以下命令进行安装。pip install beautifulsoup
如果提示安装错误,请检查在Python的安装中是否允许了pip插件,具体内容可以参照这篇关于Python安装的讲解。
2.BeautifulSoup库的基本元素
Beautifulsoup库(bs4库)是维护、遍历、解析HTML标签树的功能库,其中BeautifulSoup类是bs4库中最基本的类。学习bs4库的基本功能前,我们首先要仔细了解BeautifulSoup类的基本元素,方便以后更高效的使用bs4库。
| 名称 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和 </>标明开头和结尾,与HTML内标签对应 |
| Name | 标签的名字,<>……</p>的名字是‘p’,可以用 <tag>.name获取标签名字 |
| Attributes | 标签的属性,字典形式组织,可以用<tag>.attrs获取标签属性 |
| NavigableString | 标签内非属性字符串,<>……</>中字符串,可以用 <tag>.string获取标内字符串 |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
3.网页解析器的种类
网页内容有很多格式,对应也有很多的解析器,对网页内容进行解析。目前通用的有以下这些。| 名称 | 实例 |
|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk,’html.parser’) |
| lxml的HTML解析器 | BaeutifulSoup(mk,’lxml’) |
| lxml的XML解析器 | BeautifulSoup(mk,’xml’) |
| html5lib的解析器 | BeautifulSoup(mk,’html5lib’) |
pip install lxml后使用,最后一项则需要在
pip install html5lib后使用
4.BeautifulSoup库的遍历功能
HTML网页是由标签构成的树形结构,如果需要提取和分析网页的内容,必须要能够对标签树结构进行遍历,这样才能完整获得标签树中的内容。4000
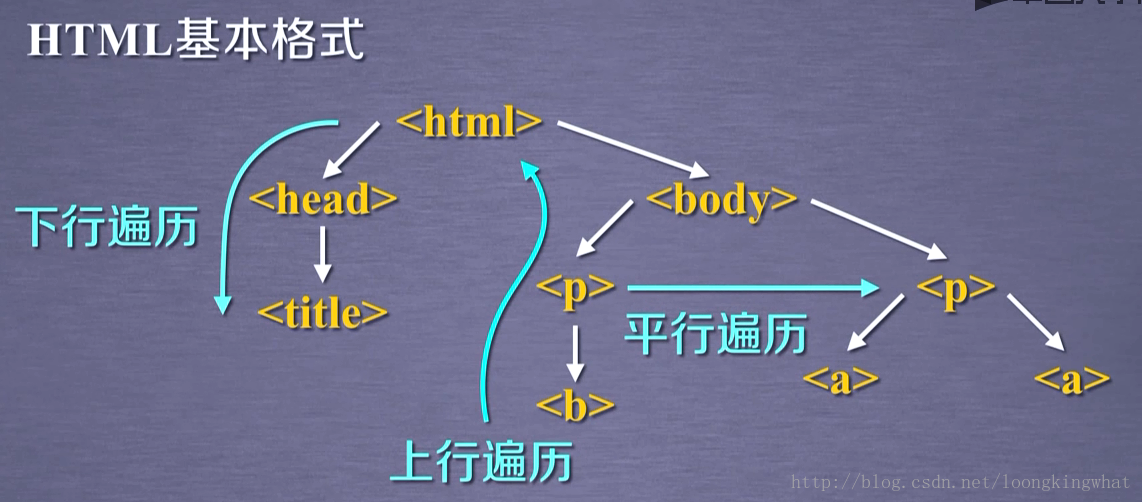
根据HTML标签树的基本格式,如果想遍历所有内容,大致有三种路线:
下行遍历:由父亲节点向儿子节点和子孙节点遍历
上行遍历:由子孙节点向父亲节点遍历
平行遍历:在同一个父亲节点下,向同一级节点遍历
4.1 下行遍历
下行遍历方式中,bs4库提供以下3种属性:| 属性 | 说明 |
|---|---|
<tag>.contents | 子节点的列表,将<tag>所有儿子节点存入列表 |
<tag>.children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
<tag>.descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
4.2 上行遍历
上行遍历方式中,bs4库提供以下2种属性:| 属性 | 说明 |
|---|---|
<tag>.parent | 节点的父亲标签 |
<tag>.parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
4.3平行遍历
平行遍历方式中,bs4库提供以下4种属性:| 属性 | 说明 |
|---|---|
<tag>.parent | 节点的父亲标签 |
<tag>.parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
<tag>.next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
<tag>.previous_siblings | 迭代类型,返回按照HTML文本顺序的前序所有平行节点标签 |
5.基于bs4库的显示和编码
为了让HTML页面的内容更加友好的显示,bs4库提供prettify()方法进行相关的处理,在实际调试中将为用户提供很多方便。
html=requests.get(url) soup=BeautifulSoup(html,'html.parser') print(soup.prettify())
同时,bs4库将所有内容都采用UTF-8编码进行编码,UTF-8可以很好的支持中文等语言显示。

相关文章推荐
- python 网络爬虫学习笔记之beautifulsoup
- 【python爬虫专题】解析方法 <4> BeautifulSoup库学习
- 使用requests+beautifulsoup模块实现python网络爬虫功能
- python网络小爬虫的编写
- Python即时网络爬虫项目启动说明
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
- Python 网络爬虫 006 (编程) 解决下载(或叫:爬取)到的网页乱码问题
- [Python]网络爬虫4
- python网络爬虫基础(2)--Beautiful Soup库
- [Python]网络爬虫(八):糗事百科的网络爬虫(v0.3)源码及解析(简化更新)
- 学习python写网络爬虫(二)
- python实现网络爬虫
- [Python]网络爬虫(九):百度贴吧的网络爬虫(v0.4)源码及解析
- Python-网络爬虫之BeautifulSoup(1)
- Python下基于requests及BeautifulSoup构建网络爬虫
- 读书笔记--用Python写网络爬虫00--建立练习环境
- Python入门网络爬虫之精华版
- 【Python学习系列五】Python网络爬虫框架Scrapy环境搭建
- Python网络爬虫 学习资源----
- 如何用Python网络爬虫爬取网易云音乐歌词