Java 图像智能字符识别技术——【专题一】
2017-07-27 00:00
169 查看
摘要: 该片文章解决电话号码保存为图片时的爬虫抓取,解答汉王是如何实现文字识别的,解答PDF该如何转换为word?
早在60、70年代,世界各国就开始有OCR的研究,而研究的初期,多以文字的识别方法研究为主,且识别的文字仅为0至9的数字。20世纪70年代初,日本的学者开始研究汉字识别,并做了大量的工作。1986年以后我国的OCR研究有了很大进展,在汉字建模和识别方法上都有所创新,在系统研制和开发应用中都取得了丰硕的成果,不少单位相继推出了中文OCR产品。
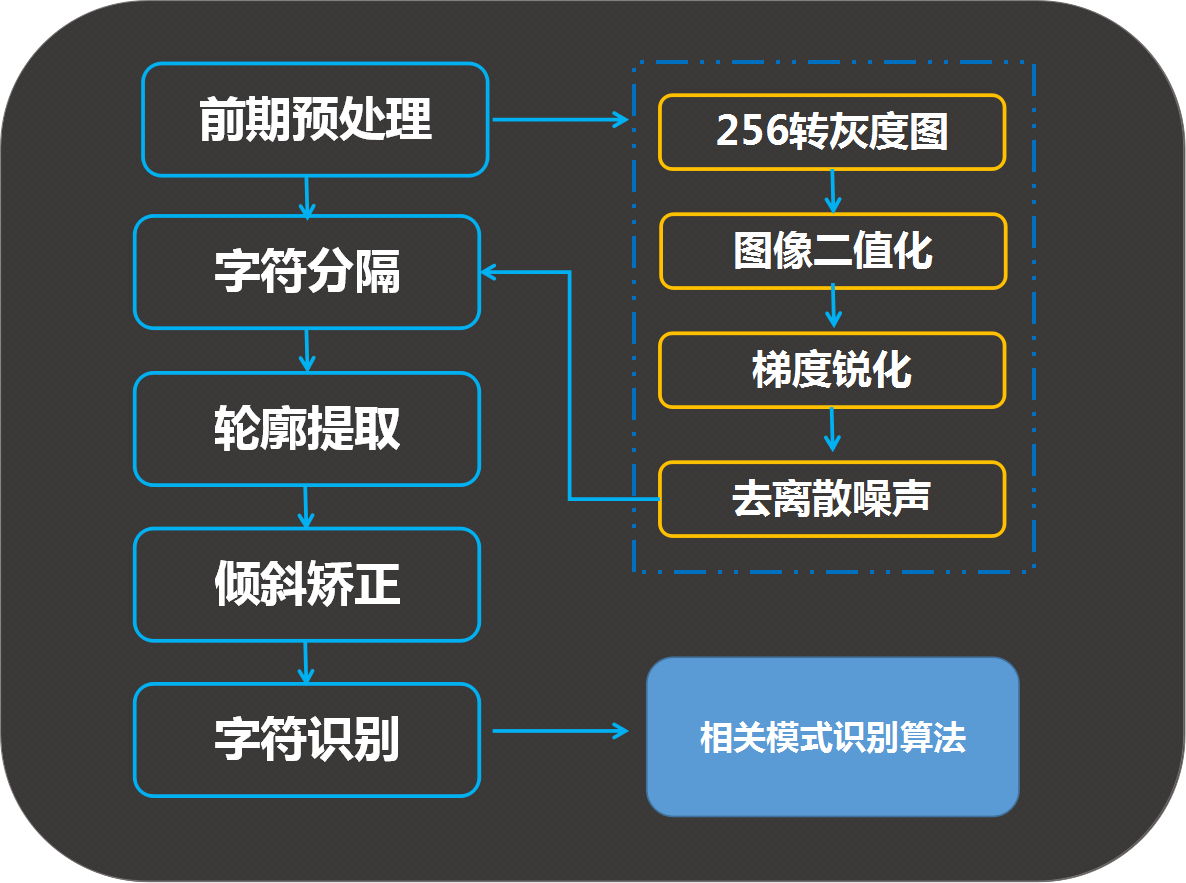
1、图像输入、预处理:
图像输入:对于不同的图像格式,有着不同的存储格式,不同的压缩方式。预处理:主要包括二值化(图像的二值化,就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的只有黑和白的视觉效果),噪声去除,倾斜较正等
2、二值化:
对摄像头拍摄的图片,大多数是彩色图像,彩色图像所含信息量巨大,对于图片的内容,我们可以简单的分为前景与背景,为了让计算机更快的,更好的识别文字,我们需要先对彩色图进行处理,使图片只前景信息与背景信息,可以简单的定义前景信息为黑色,背景信息为白色,这就是二值化图了。
3、噪声去除:
对于不同的文档,我们对噪声的定义可以不同,根据噪声的特征进行去噪,就叫做噪声去除
4、倾斜较正:
由于一般用户,在拍照文档时,都比较随意,因此拍照出来的图片不可避免的产生倾斜,这就需要进行较正。
版面分析:
5、将文档图片分段落,分行的过程就叫做版面分析,由于实际文档的多样性,复杂性,因此,目前还没有一个固定的,最优的切割模型。
6、字符切割:
由于拍照条件的限制,经常造成字符粘连,断笔,因此极大限制了识别系统的性能,这就需要文字识别软件有字符切割功能。
7、字符识别:
这一研究,已经是很早的事情了,比较早有模板匹配,后来以特征提取为主,由于文字的位移,笔画的粗细,断笔,粘连,旋转等因素的影响,极大影响特征的提取的难度。
8、版面恢复:
人们希望识别后的文字,仍然像原文档图片那样排列着,段落不变,位置不变,顺序不变,的输出到word文档,pdf文档等,这一过程就叫做版面恢复。
9、后处理、校对:
根据特定的语言上下文的关系,对识别结果进行较正,就是后处理。
如果开发一个OCR文字识别软件系统,这些都是我们需要处理的,我们的目的很简单,只是要把影像作一个转换,使影像内的图形继续保存、有表格则表格内资料及影像内的文字,一律变成计算机文字,使能达到影像资料的储存量减少、识别出的文字可再使用及分析,当然也可节省因键盘输入的人力与时间。
从影像到结果输出,须经过影像输入、影像前处理、文字特征抽取、比对识别、最后经人工校正将认错的文字更正,将结果输出。
序言
最近公司在做爬虫项目时,遇到一些问题,当抓取某互联网网站时,发现某互联网网站做了反爬虫操作。页面红的电话号码为图片形式,字体为红色,数字之间零间隔或负间隔,无法保存为文本,此时想起以前做人脸识别(OpenCV)时学习的一些图片操作。现在写一些Demo测试一下解决一下该问题。这个市面上有很多成熟的产品,如汉王的图片识别技术、WPS的PDF转换工具等,我们都可以使用OCR来解决。(知只是其中一种解决方案)OCR文字识别
ocr文字识别软件提供图片文字识别服务,是一个带有PDF文件处理功能的OCR软件;具有识别正确率高,识别速度快的特点。有批量处理功能,避免了单页处理的麻烦;支持处理灰度、彩色、黑白三种色彩的BMP、TIF、JPG、PDF多种格式的图像文件;可识别简体、繁体和英文三种语言(中文的可能稍微复杂一些,中文有一些相似、繁体的、复杂的文字这些识别时有些困难);具有简单易用的表格识别功能;具有TXT、RTF、HTM和XLS多种输出格式,并有所见即所得的版面还原功能。新增打开与识别PDF文件功能,支持文字型PDF的直接转换和图像型PDF的OCR识别,既可以采用OCR的方式将PDF文件转换为可编辑文档,也可以采用格式转换的方式直接转换文字型PDF文件为RTF文件或文本文件。历史背景
光学文字识别的概念是在1929年由德国科学家Tausheck最先提出来的,后来美国科学家Handel也提出了利用技术对文字进行识别的想法。早在60、70年代,世界各国就开始有OCR的研究,而研究的初期,多以文字的识别方法研究为主,且识别的文字仅为0至9的数字。20世纪70年代初,日本的学者开始研究汉字识别,并做了大量的工作。1986年以后我国的OCR研究有了很大进展,在汉字建模和识别方法上都有所创新,在系统研制和开发应用中都取得了丰硕的成果,不少单位相继推出了中文OCR产品。
图像识别框架
在使用OCR之前我们先了解一下图片识别框架,图片识别框架主要是由下面几个部分组成。1、图像输入、预处理:
图像输入:对于不同的图像格式,有着不同的存储格式,不同的压缩方式。预处理:主要包括二值化(图像的二值化,就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的只有黑和白的视觉效果),噪声去除,倾斜较正等
2、二值化:
对摄像头拍摄的图片,大多数是彩色图像,彩色图像所含信息量巨大,对于图片的内容,我们可以简单的分为前景与背景,为了让计算机更快的,更好的识别文字,我们需要先对彩色图进行处理,使图片只前景信息与背景信息,可以简单的定义前景信息为黑色,背景信息为白色,这就是二值化图了。
3、噪声去除:
对于不同的文档,我们对噪声的定义可以不同,根据噪声的特征进行去噪,就叫做噪声去除
4、倾斜较正:
由于一般用户,在拍照文档时,都比较随意,因此拍照出来的图片不可避免的产生倾斜,这就需要进行较正。
版面分析:
5、将文档图片分段落,分行的过程就叫做版面分析,由于实际文档的多样性,复杂性,因此,目前还没有一个固定的,最优的切割模型。
6、字符切割:
由于拍照条件的限制,经常造成字符粘连,断笔,因此极大限制了识别系统的性能,这就需要文字识别软件有字符切割功能。
7、字符识别:
这一研究,已经是很早的事情了,比较早有模板匹配,后来以特征提取为主,由于文字的位移,笔画的粗细,断笔,粘连,旋转等因素的影响,极大影响特征的提取的难度。
8、版面恢复:
人们希望识别后的文字,仍然像原文档图片那样排列着,段落不变,位置不变,顺序不变,的输出到word文档,pdf文档等,这一过程就叫做版面恢复。
9、后处理、校对:
根据特定的语言上下文的关系,对识别结果进行较正,就是后处理。
如果开发一个OCR文字识别软件系统,这些都是我们需要处理的,我们的目的很简单,只是要把影像作一个转换,使影像内的图形继续保存、有表格则表格内资料及影像内的文字,一律变成计算机文字,使能达到影像资料的储存量减少、识别出的文字可再使用及分析,当然也可节省因键盘输入的人力与时间。
从影像到结果输出,须经过影像输入、影像前处理、文字特征抽取、比对识别、最后经人工校正将认错的文字更正,将结果输出。

相关文章推荐
- Java 图像智能字符识别技术——【专题三】
- java 图像智能字符识别技术——【专题二】
- Java OCR tesseract 图像智能字符识别技术
- java零碎要点---Tesseract 3.0,Java OCR 图像智能字符识别技术,可识别中文
- Java OCR tesseract 图像智能字符识别技术(一)
- Java OCR tesseract 图像智能文字字符识别技术实例代码
- Java OCR tesseract 图像智能字符识别技术
- Java OCR tesseract 图像智能字符识别技术
- Java OCR 图像智能字符识别技术,可识别中文
- Java OCR tesseract 图像智能字符识别技术
- Java OCR tesseract 图像智能字符识别技术
- Java OCR tesseract 图像智能字符识别技术 Java代码实现(二)
- Java OCR tesseract 图像智能字符识别技术 Java代码实现
- Java OCR tesseract 图像智能字符识别技术 Java代码实现
- [转]Java OCR 图像智能字符识别技术,可识别中文
- Java OCR tesseract 图像智能字符识别技术 Java实现
- Java OCR 图像智能字符识别技术,可识别中文
- Java OCR tesseract 图像智能字符识别技术
- Java OCR 图像智能字符识别技术
- Java OCR tesseract 图像智能字符识别技术