(7)Java数据结构--集合map,set,list详解
2017-07-19 08:55
771 查看
MAP,SET,LIST,等JAVA中集合解析(了解) - clam_clam的专栏 - CSDN博---有颜色,
http://blog.csdn.net/clam_clam/article/details/6645021
JAVA中集合map,set,list详解 - jzhf2012的专栏 - CSDN博客
http://blog.csdn.net/jzhf2012/article/details/8465742
Java中Map,List和Set的集合 - 毛毛虫的专栏 - CSDN博客--简明扼要-引人深入
http://blog.csdn.net/u013266600/article/details/49783725
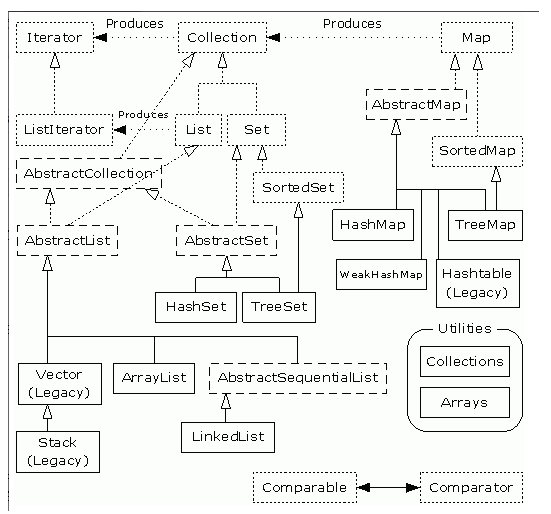
在JAVA的util包中有两个所有集合的父接口Collection和Map,它们的父子关系:
以下对众多接口和类的简单说明:首先不能不先说一下数组(Array)
一、Array , Arrays
Java所有“存储及随机访问一连串对象”的做法,array是最有效率的一种。
1、
效率高,但容量固定且无法动态改变。
array还有一个缺点是,无法判断其中实际存有多少元素,length只是告诉我们array的容量。
2、Java中有一个Arrays类,专门用来操作array。
arrays中拥有一组static函数,
equals():比较两个array是否相等。array拥有相同元素个数,且所有对应元素两两相等。
fill():将值填入array中。
sort():用来对array进行排序。
binarySearch():在排好序的array中寻找元素。
System.arraycopy():array的复制。
二、Collection , Map
若撰写程序时不知道究竟需要多少对象,需要在空间不足时自动扩增容量,则需要使用容器类库,array不适用。
1、Collection 和 Map 的区别
容器内每个为之所存储的元素个数不同。
Collection类型者,每个位置只有一个元素。
Map类型者,持有 key-value
pair,像个小型数据库。
2、Java2容器类类库的用途是“保存对象”,它分为两类,各自旗下的子类关系
Collection
--List:将以特定次序存储元素。所以取出来的顺序可能和放入顺序不同。
--ArrayList / LinkedList / Vector
--Set : 不能含有重复的元素
--HashSet /TreeSet
Map
--HashMap
--HashTable
--TreeMap
Map----一组成对的“键值对”对象,即其元素是成对的对象,最典型的应用就是数据字典,并且还有其它广泛的应用。另外,Map可以返回其所有键组成的Set和其所有值组成的Collection,或其键值对组成的Set,并且还可以像数组一样扩展多维Map,只要让Map中键值对的每个“值”是一个Map即可。
Collection下 1.迭代器
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
Java中的Iterator功能比较简单,并且只能单向移动:
(1)
使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
2.List的功能方法
List(interface):
次序是List最重要的特点;它确保维护元素特定的顺序。List为Collection添加了许多方法,使得能够向List中间插入与移除元素(只推荐LinkedList使用)。一个List可以生成ListIterator,使用它可以从两个方向遍历List,也可以从List中间插入和删除元素。
ArrayList:
由数组实现的List。它允许对元素进行快速随机访问,但是向List中间插入与移除元素的速度很慢。ListIterator只应该用来由后向前遍历ArrayList,而不是用来插入和删除元素,因为这比LinkedList开销要大很多。
LinkedList:
由列表实现的List。对顺序访问进行了优化,向List中间插入与删除得开销不大,随机访问则相对较慢(可用ArrayList代替)。它具有方法addFirst()、addLast()、getFirst()、getLast()、removeFirst()、removeLast(),这些方法(没有在任何接口或基类中定义过)使得LinkedList可以当作堆栈、队列和双向队列使用。
3.Set的功能方法
Set(interface):
存入Set的每个元素必须是唯一的,这也是与List不同的,因为Set不保存重复元素。加入Set的Object必须定义equals()方法以确保对象的唯一性。Set与Collection有完全一样的接口。Set接口不保证维护元素的次序。
HashSet: HashSet能快速定位一个元素,存入HashSet的对象必须定义hashCode()。
TreeSet: 保持次序的Set,底层为树结构。使用它可以从Set中提取有序的序列。
LinkedHashSet:
具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序)。于是在使用迭代器遍历Set时,结果会按元素插入的次序显示。
HashSet采用散列函数对元素进行排序,这是专门为快速查询而设计的;TreeSet采用红黑树的数据结构进行排序元素;LinkedHashSet内部使用散列以加快查询速度,同时使用链表维护元素的次序,使得看起来元素是以插入的顺序保存的。需要注意的是,生成自己的类时,Set需要维护元素的存储顺序,因此要实现Comparable接口并定义compareTo()方法。
3、其他特征
* List,Set,Map将持有对象一律视为Object型别。
*
Collection、List、Set、Map都是接口,不能实例化。
继承自它们的 ArrayList, Vector, HashTable,
HashMap是具象class,这些才可被实例化。
* vector容器确切知道它所持有的对象隶属什么型别。vector不进行边界检查。
三、Collections
Collections是针对集合类的一个帮助类。提供了一系列静态方法实现对各种集合的搜索、排序、线程完全化等操作。
相当于对Array进行类似操作的类——Arrays。
如,Collections.max(Collection
coll); 取coll中最大的元素。
Collections.sort(List list); 对list中元素排序
四、如何选择?
1、容器类和Array的区别、择取
*
容器类仅能持有对象引用(指向对象的指针),而不是将对象信息copy一份至数列某位置。
*
一旦将对象置入容器内,便损失了该对象的型别信息。
2、
*
在各种Lists中,最好的做法是以ArrayList作为缺省选择。当插入、删除频繁时,使用LinkedList();
Vector总是比ArrayList慢,所以要尽量避免使用。
*
在各种Sets中,HashSet通常优于HashTree(插入、查找)。只有当需要产生一个经过排序的序列,才用TreeSet。
HashTree存在的唯一理由:能够维护其内元素的排序状态。
* 在各种Maps中
HashMap用于快速查找。
* 当元素个数固定,用Array,因为Array效率是最高的。
结论:最常用的是ArrayList,HashSet,HashMap,Array。而且,我们也会发现一个规律,用TreeXXX都是排序的。
下面代码附上以供参考
java如何遍历map
注意:
1、Collection没有get()方法来取得某个元素。只能通过iterator()遍历元素。
2、Set和Collection拥有一模一样的接口。
3、List,可以通过get()方法来一次取出一个元素。使用数字来选择一堆对象中的一个,get(0)...。(add/get)
4、一般使用ArrayList。用LinkedList构造堆栈stack、队列queue。
5、Map用 put(k,v) /
get(k),还可以使用containsKey()/containsValue()来检查其中是否含有某个key/value。
HashMap会利用对象的hashCode来快速找到key。
*
hashing
哈希码就是将对象的信息经过一些转变形成一个独一无二的int值,这个值存储在一个array中。
我们都知道所有存储结构中,array查找速度是最快的。所以,可以加速查找。
发生碰撞时,让array指向多个values。即,数组每个位置上又生成一个梿表。
6、Map中元素,可以将key序列、value序列单独抽取出来。
使用keySet()抽取key序列,将map中的所有keys生成一个Set。
使用values()抽取value序列,将map中的所有values生成一个Collection。
为什么一个生成Set,一个生成Collection?那是因为,key总是独一无二的,value允许重复。
Collection List Set Map 区别记忆
这些都代表了Java中的集合,这里主要从其元素是否有序,是否可重复来进行区别记忆,以便恰当地使用,当然还存在同步方面的差异。
有序否 允许元素重复否
Collection 否 是
List 是 是
AbstractSet 否
否
HashSet 否 否
TreeSet 是(用二叉树排序) 否
AbstractMap 否
使用key-value来映射和存储数据,Key必须惟一,value可以重复
HashMap 否
使用key-value来映射和存储数据,Key必须惟一,value可以重复
TreeMap 是(用二叉树排序)
使用key-value来映射和存储数据,Key必须惟一,value可以重复
List
接口对Collection进行了简单的扩充,它的具体实现类常用的有ArrayList和LinkedList。你可以将任何东西放到一个List容器
中,并在需要时从中取出。ArrayList从其命名中可以看出它是一种类似数组的形式进行存储,因此它的随机访问速度极快,而LinkedList的内
部实现是链表,它适合于在链表中间需要频繁进行插入和删除操作。在具体应用时可以根据需要自由选择。前面说的Iterator只能对容器进行向前遍历,而
ListIterator则继承了Iterator的思想,并提供了对List进行双向遍历的方法。
Set接口也是
Collection的一种扩展,而与List不同的时,在Set中的对象元素不能重复,也就是说你不能把同样的东西两次放入同一个Set容器中。它的常
用具体实现有HashSet和TreeSet类。HashSet能快速定位一个元素,但是你放到HashSet中的对象需要实现hashCode()方
法,它使用了前面说过的哈希码的算法。而TreeSet则将放入其中的元素按序存放,这就要求你放入其中的对象是可排序的,这就用到了集合框架提供的另外
两个实用类Comparable和Comparator。一个类是可排序的,它就应该实现Comparable接口。有时多个类具有相同的排序算法,那就
不需要在每分别重复定义相同的排序算法,只要实现Comparator接口即可。集合框架中还有两个很实用的公用类:Collections和
Arrays。Collections提供了对一个Collection容器进行诸如排序、复制、查找和填充等一些非常有用的方法,Arrays则是对一
个数组进行类似的操作。
Map是一种把键对象和值对象进行关联的容器,而一个值对象又可以是一个Map,依次类推,这样就可
形成一个多级映射。对于键对象来说,像Set一样,一个Map容器中的键对象不允许重复,这是为了保持查找结果的一致性;如果有两个键对象一样,那你想得
到那个键对象所对应的值对象时就有问题了,可能你得到的并不是你想的那个值对象,结果会造成混乱,所以键的唯一性很重要,也是符合集合的性质的。当然在使
用过程中,某个键所对应的值对象可能会发生变化,这时会按照最后一次修改的值对象与键对应。对于值对象则没有唯一性的要求。你可以将任意多个键都映射到一
个值对象上,这不会发生任何问题(不过对你的使用却可能会造成不便,你不知道你得到的到底是那一个键所对应的值对象)。Map有两种比较常用的实现:
HashMap和TreeMap。HashMap也用到了哈希码的算法,以便快速查找一个键,TreeMap则是对键按序存放,因此它便有一些扩展的方
法,比如firstKey(),lastKey()等,你还可以从TreeMap中指定一个范围以取得其子Map。键和值的关联很简单,用pub (Object
key,Object value)方法即可将一个键与一个值对象相关联。用get(Object key)可得到与此key对象所对应的值对象
============================
Set(集)
List(列表)
Map(映射)
要深入理解集合首先要了解下我们熟悉的数组:
数组是大小固定的,并且同一个数组只能存放类型一样的数据(基本类型/引用类型),而JAVA集合可以存储和操作数目不固定的一组数据。
所有的JAVA集合都位于 java.util包中! JAVA集合只能存放引用类型的的数据,不能存放基本数据类型。
简单说下集合和数组的区别:(参考文章:《Thinking In Algorithm》03.数据结构之数组)
http://blog.csdn.net/clam_clam/article/details/6645021
JAVA中集合map,set,list详解 - jzhf2012的专栏 - CSDN博客
http://blog.csdn.net/jzhf2012/article/details/8465742
Java中Map,List和Set的集合 - 毛毛虫的专栏 - CSDN博客--简明扼要-引人深入
http://blog.csdn.net/u013266600/article/details/49783725
在JAVA的util包中有两个所有集合的父接口Collection和Map,它们的父子关系:
java.util +Collection 这个接口extends自 --java.lang.Iterable接口 +List 接口 -ArrayList 类 -LinkedList 类 -Vector 类 此类是实现同步的 +Queue 接口 +不常用,在此不表. +Set 接口 +SortedSet 接口 -TreeSet 类 -HashSet +Map 接口 -HashMap 类 (除了不同步和允许使用 null 键/值之外,与 Hashtable 大致相同.) -Hashtable 类 此类是实现同步的,不允许使用 null 键值 +SortedMap 接口 -TreeMap 类
以下对众多接口和类的简单说明:首先不能不先说一下数组(Array)
一、Array , Arrays
Java所有“存储及随机访问一连串对象”的做法,array是最有效率的一种。
1、
效率高,但容量固定且无法动态改变。
array还有一个缺点是,无法判断其中实际存有多少元素,length只是告诉我们array的容量。
2、Java中有一个Arrays类,专门用来操作array。
arrays中拥有一组static函数,
equals():比较两个array是否相等。array拥有相同元素个数,且所有对应元素两两相等。
fill():将值填入array中。
sort():用来对array进行排序。
binarySearch():在排好序的array中寻找元素。
System.arraycopy():array的复制。
二、Collection , Map
若撰写程序时不知道究竟需要多少对象,需要在空间不足时自动扩增容量,则需要使用容器类库,array不适用。
1、Collection 和 Map 的区别
容器内每个为之所存储的元素个数不同。
Collection类型者,每个位置只有一个元素。
Map类型者,持有 key-value
pair,像个小型数据库。
2、Java2容器类类库的用途是“保存对象”,它分为两类,各自旗下的子类关系
Collection
--List:将以特定次序存储元素。所以取出来的顺序可能和放入顺序不同。
--ArrayList / LinkedList / Vector
--Set : 不能含有重复的元素
--HashSet /TreeSet
Map
--HashMap
--HashTable
--TreeMap
Map----一组成对的“键值对”对象,即其元素是成对的对象,最典型的应用就是数据字典,并且还有其它广泛的应用。另外,Map可以返回其所有键组成的Set和其所有值组成的Collection,或其键值对组成的Set,并且还可以像数组一样扩展多维Map,只要让Map中键值对的每个“值”是一个Map即可。
Collection下 1.迭代器
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
Java中的Iterator功能比较简单,并且只能单向移动:
(1)
使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
2.List的功能方法
List(interface):
次序是List最重要的特点;它确保维护元素特定的顺序。List为Collection添加了许多方法,使得能够向List中间插入与移除元素(只推荐LinkedList使用)。一个List可以生成ListIterator,使用它可以从两个方向遍历List,也可以从List中间插入和删除元素。
ArrayList:
由数组实现的List。它允许对元素进行快速随机访问,但是向List中间插入与移除元素的速度很慢。ListIterator只应该用来由后向前遍历ArrayList,而不是用来插入和删除元素,因为这比LinkedList开销要大很多。
LinkedList:
由列表实现的List。对顺序访问进行了优化,向List中间插入与删除得开销不大,随机访问则相对较慢(可用ArrayList代替)。它具有方法addFirst()、addLast()、getFirst()、getLast()、removeFirst()、removeLast(),这些方法(没有在任何接口或基类中定义过)使得LinkedList可以当作堆栈、队列和双向队列使用。
3.Set的功能方法
Set(interface):
存入Set的每个元素必须是唯一的,这也是与List不同的,因为Set不保存重复元素。加入Set的Object必须定义equals()方法以确保对象的唯一性。Set与Collection有完全一样的接口。Set接口不保证维护元素的次序。
HashSet: HashSet能快速定位一个元素,存入HashSet的对象必须定义hashCode()。
TreeSet: 保持次序的Set,底层为树结构。使用它可以从Set中提取有序的序列。
LinkedHashSet:
具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序)。于是在使用迭代器遍历Set时,结果会按元素插入的次序显示。
HashSet采用散列函数对元素进行排序,这是专门为快速查询而设计的;TreeSet采用红黑树的数据结构进行排序元素;LinkedHashSet内部使用散列以加快查询速度,同时使用链表维护元素的次序,使得看起来元素是以插入的顺序保存的。需要注意的是,生成自己的类时,Set需要维护元素的存储顺序,因此要实现Comparable接口并定义compareTo()方法。
3、其他特征
* List,Set,Map将持有对象一律视为Object型别。
*
Collection、List、Set、Map都是接口,不能实例化。
继承自它们的 ArrayList, Vector, HashTable,
HashMap是具象class,这些才可被实例化。
* vector容器确切知道它所持有的对象隶属什么型别。vector不进行边界检查。
三、Collections
Collections是针对集合类的一个帮助类。提供了一系列静态方法实现对各种集合的搜索、排序、线程完全化等操作。
相当于对Array进行类似操作的类——Arrays。
如,Collections.max(Collection
coll); 取coll中最大的元素。
Collections.sort(List list); 对list中元素排序
四、如何选择?
1、容器类和Array的区别、择取
*
容器类仅能持有对象引用(指向对象的指针),而不是将对象信息copy一份至数列某位置。
*
一旦将对象置入容器内,便损失了该对象的型别信息。
2、
*
在各种Lists中,最好的做法是以ArrayList作为缺省选择。当插入、删除频繁时,使用LinkedList();
Vector总是比ArrayList慢,所以要尽量避免使用。
*
在各种Sets中,HashSet通常优于HashTree(插入、查找)。只有当需要产生一个经过排序的序列,才用TreeSet。
HashTree存在的唯一理由:能够维护其内元素的排序状态。
* 在各种Maps中
HashMap用于快速查找。
* 当元素个数固定,用Array,因为Array效率是最高的。
结论:最常用的是ArrayList,HashSet,HashMap,Array。而且,我们也会发现一个规律,用TreeXXX都是排序的。
下面代码附上以供参考
public class TestApp {
public static void main(String[] args) {
//List-->数组
List<String> list = new ArrayList<String>();
list.add("蹇伟");
list.add("Jerval");
list.add("杰威");
Object[] objects = list.toArray();//返回Object数组
System.out.println("objects:"+Arrays.toString(objects));
String[] strings1 = new String[list.size()];
list.toArray(strings1);//将转化后的数组放入已经创建好的对象中
System.out.println("strings1:"+Arrays.toString(strings1));
String[] strings2 = list.toArray(new String[0]);//将转化后的数组赋给新对象
System.out.println("strings2:"+Arrays.toString(strings2));
//数组-->List
String[] ss = {"JJ","KK"};
List<String> list1 = Arrays.asList(ss);
List<String> list2 = Arrays.asList("AAA","BBB");
System.out.println(list1);
System.out.println(list2);
//List-->Set
List<String> list3 = new ArrayList<String>(new HashSet<String>());
//Set-->List
Set<String> set = new HashSet<String>(new ArrayList<String>());
//数组-->Set
String[] strs = {"AA","BB"};
Set<String> set2 = new HashSet<String>(Arrays.asList(strs));
System.out.println(set2);
//Set-->数组
Set<String> set3 = new HashSet<String>(Arrays.asList("PP","OO"));
String[] strSet = new String[set3.size()];
set3.toArray(strSet);
System.out.println(Arrays.toString(strSet));
//Map操作
Map<String, String> map = new HashMap<String, String>();
map.put("YYY", "UUU");
map.put("RRR", "TTT");
// 将键转化为Set
Set<String> mapKeySet = map.keySet();
// 将值转化为Set
Set<String> mapValuesSet = new HashSet<String>(map.values());
// 将值转化为List
List<String> mapValuesList = new ArrayList<String>(map.values());
}
}java如何遍历map
package test;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
public class TestMap {
//循环遍历map的方法
public static void main(String[] args) {
Map<String, Integer> tempMap = new HashMap<String, Integer>();
tempMap.put("a", 1);
tempMap.put("b", 2);
tempMap.put("c", 3);
// JDK1.4中
// 遍历方法一 hashmap entrySet() 遍历
System.out.println("方法一");
Iterator it = tempMap.entrySet().iterator();
while (it.hasNext()) {
Map.Entry entry = (Map.Entry) it.next();
Object key = entry.getKey();
Object value = entry.getValue();
System.out.println("key=" + key + " value=" + value);
}
System.out.println("");
// JDK1.5中,应用新特性For-Each循环
// 遍历方法二
System.out.println("方法二");
for (Map.Entry<String, Integer> entry : tempMap.entrySet()) {
String key = entry.getKey().toString();
String value = entry.getValue().toString();
System.out.println("key=" + key + " value=" + value);
}
System.out.println("");
// 遍历方法三 hashmap keySet() 遍历
System.out.println("方法三");
for (Iterator i = tempMap.keySet().iterator(); i.hasNext();) {
Object obj = i.next();
System.out.println(obj);// 循环输出key
System.out.println("key=" + obj + " value=" + tempMap.get(obj));
}
for (Iterator i = tempMap.values().iterator(); i.hasNext();) {
Object obj = i.next();
System.out.println(obj);// 循环输出value
}
System.out.println("");
// 遍历方法四 treemap keySet()遍历
System.out.println("方法四");
for (Object o : tempMap.keySet()) {
System.out.println("key=" + o + " value=" + tempMap.get(o));
}
System.out.println("11111");
// java如何遍历Map <String, ArrayList> map = new HashMap <String,
// ArrayList>();
System.out
.println("java 遍历Map <String, ArrayList> map = new HashMap <String, ArrayList>();");
Map<String, ArrayList> map = new HashMap<String, ArrayList>();
Set<String> keys = map.keySet();
Iterator<String> iterator = keys.iterator();
while (iterator.hasNext()) {
String key = iterator.next();
ArrayList arrayList = map.get(key);
for (Object o : arrayList) {
System.out.println(o + "遍历过程");
}
}
System.out.println("2222");
Map<String, List> mapList = new HashMap<String, List>();
for (Map.Entry entry : mapList.entrySet()) {
String key = entry.getKey().toString();
List<String> values = (List) entry.getValue();
for (String value : values) {
System.out.println(key + " --> " + value);
}
}
}
}注意:
1、Collection没有get()方法来取得某个元素。只能通过iterator()遍历元素。
2、Set和Collection拥有一模一样的接口。
3、List,可以通过get()方法来一次取出一个元素。使用数字来选择一堆对象中的一个,get(0)...。(add/get)
4、一般使用ArrayList。用LinkedList构造堆栈stack、队列queue。
5、Map用 put(k,v) /
get(k),还可以使用containsKey()/containsValue()来检查其中是否含有某个key/value。
HashMap会利用对象的hashCode来快速找到key。
*
hashing
哈希码就是将对象的信息经过一些转变形成一个独一无二的int值,这个值存储在一个array中。
我们都知道所有存储结构中,array查找速度是最快的。所以,可以加速查找。
发生碰撞时,让array指向多个values。即,数组每个位置上又生成一个梿表。
6、Map中元素,可以将key序列、value序列单独抽取出来。
使用keySet()抽取key序列,将map中的所有keys生成一个Set。
使用values()抽取value序列,将map中的所有values生成一个Collection。
为什么一个生成Set,一个生成Collection?那是因为,key总是独一无二的,value允许重复。
Collection List Set Map 区别记忆
这些都代表了Java中的集合,这里主要从其元素是否有序,是否可重复来进行区别记忆,以便恰当地使用,当然还存在同步方面的差异。
有序否 允许元素重复否
Collection 否 是
List 是 是
AbstractSet 否
否
HashSet 否 否
TreeSet 是(用二叉树排序) 否
AbstractMap 否
使用key-value来映射和存储数据,Key必须惟一,value可以重复
HashMap 否
使用key-value来映射和存储数据,Key必须惟一,value可以重复
TreeMap 是(用二叉树排序)
使用key-value来映射和存储数据,Key必须惟一,value可以重复
List
接口对Collection进行了简单的扩充,它的具体实现类常用的有ArrayList和LinkedList。你可以将任何东西放到一个List容器
中,并在需要时从中取出。ArrayList从其命名中可以看出它是一种类似数组的形式进行存储,因此它的随机访问速度极快,而LinkedList的内
部实现是链表,它适合于在链表中间需要频繁进行插入和删除操作。在具体应用时可以根据需要自由选择。前面说的Iterator只能对容器进行向前遍历,而
ListIterator则继承了Iterator的思想,并提供了对List进行双向遍历的方法。
Set接口也是
Collection的一种扩展,而与List不同的时,在Set中的对象元素不能重复,也就是说你不能把同样的东西两次放入同一个Set容器中。它的常
用具体实现有HashSet和TreeSet类。HashSet能快速定位一个元素,但是你放到HashSet中的对象需要实现hashCode()方
法,它使用了前面说过的哈希码的算法。而TreeSet则将放入其中的元素按序存放,这就要求你放入其中的对象是可排序的,这就用到了集合框架提供的另外
两个实用类Comparable和Comparator。一个类是可排序的,它就应该实现Comparable接口。有时多个类具有相同的排序算法,那就
不需要在每分别重复定义相同的排序算法,只要实现Comparator接口即可。集合框架中还有两个很实用的公用类:Collections和
Arrays。Collections提供了对一个Collection容器进行诸如排序、复制、查找和填充等一些非常有用的方法,Arrays则是对一
个数组进行类似的操作。
Map是一种把键对象和值对象进行关联的容器,而一个值对象又可以是一个Map,依次类推,这样就可
形成一个多级映射。对于键对象来说,像Set一样,一个Map容器中的键对象不允许重复,这是为了保持查找结果的一致性;如果有两个键对象一样,那你想得
到那个键对象所对应的值对象时就有问题了,可能你得到的并不是你想的那个值对象,结果会造成混乱,所以键的唯一性很重要,也是符合集合的性质的。当然在使
用过程中,某个键所对应的值对象可能会发生变化,这时会按照最后一次修改的值对象与键对应。对于值对象则没有唯一性的要求。你可以将任意多个键都映射到一
个值对象上,这不会发生任何问题(不过对你的使用却可能会造成不便,你不知道你得到的到底是那一个键所对应的值对象)。Map有两种比较常用的实现:
HashMap和TreeMap。HashMap也用到了哈希码的算法,以便快速查找一个键,TreeMap则是对键按序存放,因此它便有一些扩展的方
法,比如firstKey(),lastKey()等,你还可以从TreeMap中指定一个范围以取得其子Map。键和值的关联很简单,用pub (Object
key,Object value)方法即可将一个键与一个值对象相关联。用get(Object key)可得到与此key对象所对应的值对象
============================
Set,List,Map的区别
java集合的主要分为三种类型:Set(集)
List(列表)
Map(映射)
要深入理解集合首先要了解下我们熟悉的数组:
数组是大小固定的,并且同一个数组只能存放类型一样的数据(基本类型/引用类型),而JAVA集合可以存储和操作数目不固定的一组数据。
所有的JAVA集合都位于 java.util包中! JAVA集合只能存放引用类型的的数据,不能存放基本数据类型。
简单说下集合和数组的区别:(参考文章:《Thinking In Algorithm》03.数据结构之数组)
世间上本来没有集合,(只有数组参考C语言)但有人想要,所以有了集合 有人想有可以自动扩展的数组,所以有了List 有的人想有没有重复的数组,所以有了set 有人想有自动排序的组数,所以有了TreeSet,TreeList,Tree** 而几乎有有的集合都是基于数组来实现的. 因为集合是对数组做的封装,所以,数组永远比任何一个集合要快 但任何一个集合,比数组提供的功能要多 一:数组声明了它容纳的元素的类型,而集合不声明。这是由于集合以object形式来存储它们的元素。 二:一个数组实例具有固定的大小,不能伸缩。集合则可根据需要动态改变大小。 三:数组是一种可读/可写数据结构---没有办法创建一个只读数组。然而可以使用集合提供的ReadOnly方法,以只读方式来使用集合。该方法将返回一个集合的只读版本。

相关文章推荐
- 【java】java集合list与set、map集合的区别详解
- Java集合Collection、List、Set、Map使用详解
- JAVA集合LIST MAP SET详解
- JAVA中集合map,set,list详解
- JAVA中集合map,set,list详解
- Java集合排序及java集合类详解--(Collection, List, Set, Map)
- 【java】java集合list与set、map集合的区别、用法详解
- Java集合排序及java集合类详解--(Collection, List, Set, Map)
- JAVA三种集合LIST、SET、MAP ——详解
- java集合map,set,list区别
- Map、Set、Iterator迭代详解与Java平台的集合框架
- map,set,list,等JAVA中集合解析(了解)
- java 中 各种集合(List Set Map) 去除重复项
- (转)map,set,list,等JAVA中集合解析(了解)
- java 集合架构--[Collection] [List] [Set] [Map] [集合工具类]
- 集合映射(set, list, array,bag, map)详解
- 黑马程序员-java的集合概念:Coleection,List,Map,Set之间的关系
- java集合map,set,list区别
- JAVA集合的认识[Set,List,Map]
- java中把对象、对象bean、list集合、对象数组、Map和Set以及字符串转换成Json