小说生成对抗网络GANs
2017-07-14 11:57
567 查看
1.前言
机器学习可以分为两类模型,一种是判别模型(discrimination model),给定一个输入,通过模型判别输入的类别。另一种是生成模型(generative model),给定输入,通过模型从而逼近数据的原始概率分布。 目前,比较有名的生成模型有:Deep RBM 和VAE
然而,不管是RBM还是VAE,他们本身要么是通过复杂的马尔科夫链进行逼近(RBM通过马尔科夫链来避免explain away),而VAE则是通过复杂的变分推断从而逼近变分下界。他们的计算都过于麻烦。而生成对抗网络最大的优点,就是避免了复杂的马尔科夫过程。
自从 Ian Goodfellow 在2014 年发表 论文 Generative Adversarial Nets 以来,生成式对抗网络 GAN 广受关注,加上学界大牛 Yann Lecun 在 Quora 答疑时曾说,他最激动的深度学习进展是生成式对抗网络,这使得 GAN 成为近两年来在机器学习领域的新宠,在深度学习领域和图像处理方面更是有着独特的优势。可以说,研究深度学习的人,不懂
GAN,简直就是还没入门。
2. 生成对抗网络
对抗网络是一种深度学习的算法构架,和之前很火的对抗样本是两码事。 生成对抗网络采用了真实样本与生成器之间相互博弈,达到均衡的目的来训练生成网络。整个网络包含两部分,生成器Generative,简称G,和判别网络Discrimination,简称D。
给定数据x,设生成器的概率分布为pg,通过一个噪声的pz(z)进行控制。这样就可以通过生成器G,将z映射到一个生成的样本x,之后将生成的样本和真实图像输入判别模型D。其整个网络结构如下图所示。

其目标函数为:
minGmaxDV(D,G)=Epdata[logD(x)]+Epz[log(1−D(G(z)))]
在文中可以证明:
当
pg=pdata
整个算法收敛于最优解。整个优化的过程可以看做下图:

当训练完成后,整个判别器对于输入的样本的是否属于生成模型生成的结果的概率停留在50%。这也就达到了博弈的均衡点
下面我们来简单介绍一下生成式对抗网络,主要通过三篇具有标志性的论文:1)Generative Adversarial Networks;2)Conditional Generative Adversarial Nets;3)Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks来介绍。
首先来看下第一篇论文,了解一下 GAN 的过程和原理:
GAN 启发自博弈论中的二人零和博弈(two-player game),GAN 模型中的两位博弈方分别由生成式模型(generative model)和判别式模型(discriminative model)充当。生成模型 G 捕捉样本数据的分布,用服从某一分布(均匀分布,高斯分布等)的噪声 z 生成一个类似真实训练数据的样本,追求的效果是越像真实样本越好;判别模型
D 是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率,如果样本来自于真实的训练数据,D 输出大概率,否则,D 输出小概率。可以做如下类比:生成网络 G 好比假币制造团伙,专门制造假币,判别网络 D 好比警察,专门检测使用的货币是真币还是假币,G 的目标是想方设法生成和真币一样的货币,使得 D 判别不出来,D 的目标是想方设法检测出来 G 生成的假币。如图所示:
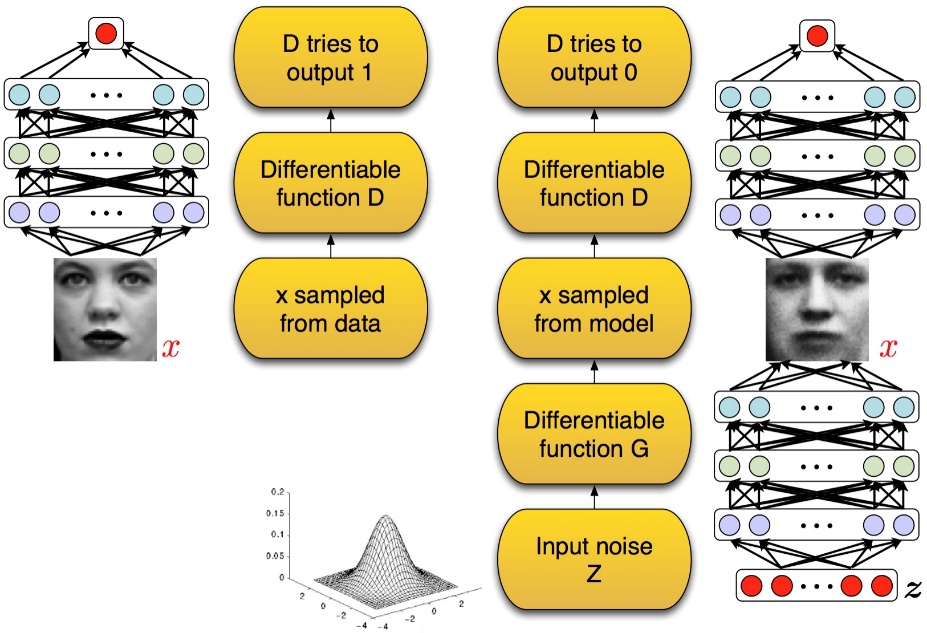
在训练的过程中固定一方,更新另一方的网络权重,交替迭代,在这个过程中,双方都极力优化自己的网络,从而形成竞争对抗,直到双方达到一个动态的平衡(纳什均衡),此时生成模型 G 恢复了训练数据的分布(造出了和真实数据一模一样的样本),判别模型再也判别不出来结果,准确率为 50%,约等于乱猜。
上述过程可以表述为如下公式:
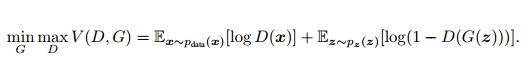
当固定生成网络 G 的时候,对于判别网络 D 的优化,可以这样理解:输入来自于真实数据,D 优化网络结构使自己输出值接近1;当输入的内容来源于生成数据时,D 优化网络结构使自己的输出 接近于0。当固定判别网络 D 的时候,G 优化自己的网络使自己输出尽可能和真实数据一样的样本,并且使得生成的样本经过 D 的判别之后,D 输出高概率。
第一篇文章,在 MNIST 手写数据集上生成的结果如下图:

最右边的一列是真实样本的图像,前面五列是生成网络生成的样本图像,可以看到生成的样本还是很像真实样本的,只是和真实样本属于不同的类,类别是随机的。
第二篇文章想法很简单,就是给 GAN 加上条件,让生成的样本符合我们的预期,这个条件可以是类别标签(例如 MNIST 手写数据集的类别标签),也可以是其他的多模态信息(例如对图像的描述语言)等。用公式表示就是:
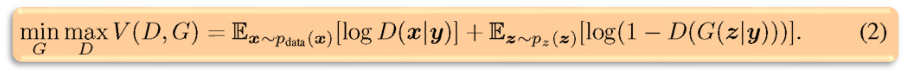
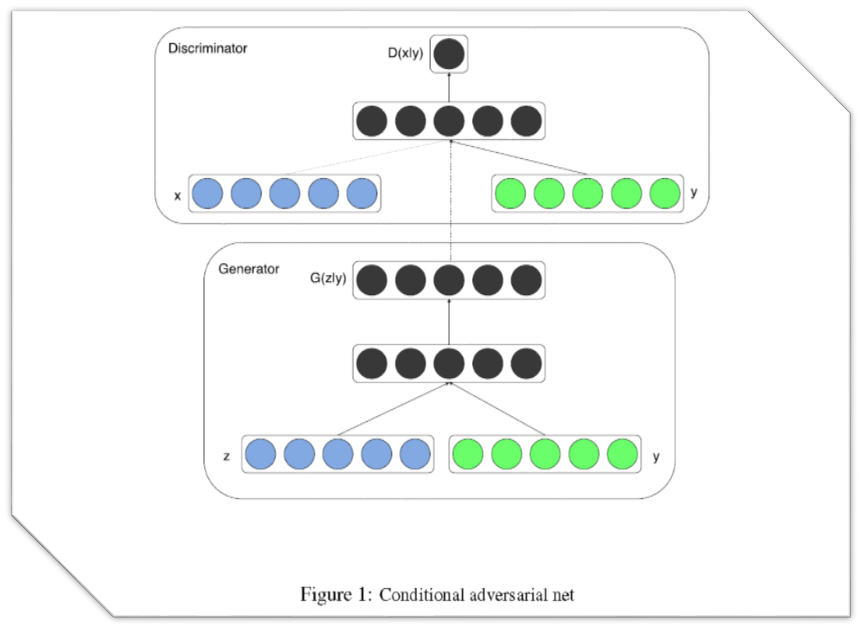
式子中的 y 是所加的条件,结构图如下:
生成结果如下图:

图中所加的条件 y 是类别标签。
第三篇文章,简称(DCGAN),在实际中是代码使用率最高的一篇文章,本系列文的代码也是这篇文章代码的初级版本,它优化了网络结构,加入了 conv,batch_norm 等层,使得网络更容易训练,网络结构如下:
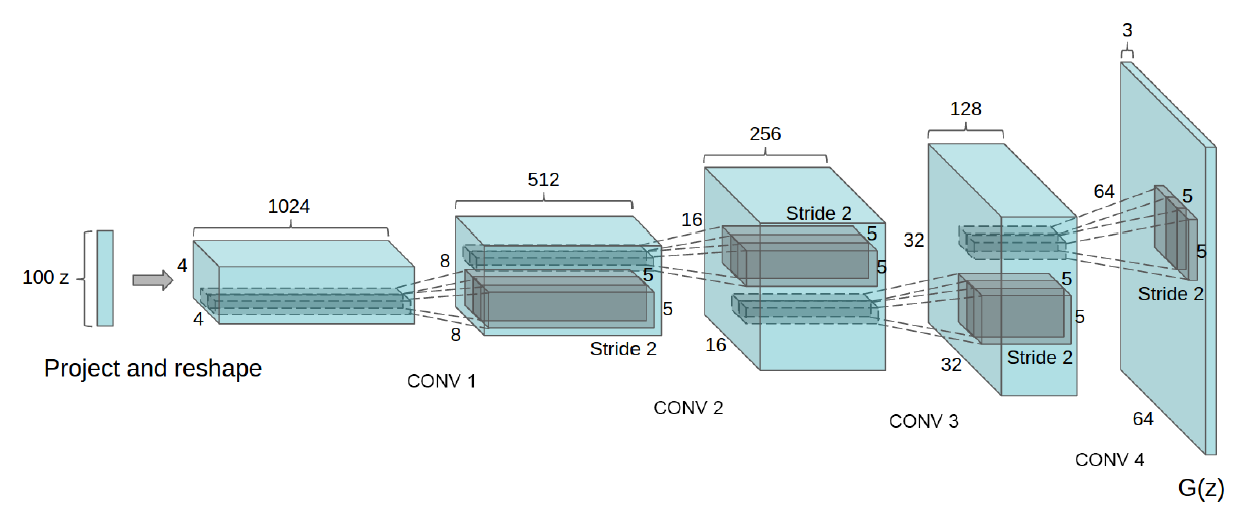
可以有加条件和不加条件两种网络,论文还做了好多试验,展示了这个网络在各种数据集上的结果。有兴趣同学可以去看论文,此文我们只从代码的角度理解去理解它。

相关文章推荐
- 一文读懂生成对抗网络GANs(附学习资源)
- 生成对抗网络GANs理解
- GANs生成对抗网络知识点初探
- Nikolai Yakovenko大佬:深度学习的下一个热点:生成对抗网络(GANs)将改变世界
- “GANs之父”Goodfellow 38分钟视频亲授:如何完善生成对抗网络?(上)
- 生成对抗网络学习笔记2----GANs(Generative Adversarial Nets)总结
- 生成对抗网络GANs
- 生成对抗网络(GANs)最新家谱:为你揭秘GANs的前世今生
- 学习笔记:生成对抗网络GANs原文的理解
- 生成对抗网络(GANs)的资料小结,另附:资源|17类对抗网络经典论文及开源代码(附源码)
- (转)机器学习系列直播--使用对抗神经网络(GANs)生成猫
- GANs-生成对抗网络 (生成明星脸)
- 生成对抗网络GANs理解(附代码)
- 转:生成对抗网络GANs理解(附代码)
- 生成对抗网络GANs理解(附代码)
- 生成对抗网络(GANs)的资料小结,另附:资源|17类对抗网络经典论文及开源代码(附源码)
- GANs(生成对抗网络)初步
- 学习笔记_01生成对抗网络(GANs)
- 机器学习系列直播--使用对抗神经网络(GANs)生成猫
- 生成对抗网络GANs工作原理