Redis 哨兵模式实现主从故障互切换
2017-07-14 10:51
781 查看
http://www.cnblogs.com/chenmh/p/5578376.html
Redis Sentinel 是一个分布式系统, 你可以在一个架构中运行多个 Sentinel 进程(progress), 这些进程使用流言协议(gossip protocols)来接收关于主服务器是否下线的信息, 并使用投票协议(agreement protocols)来决定是否执行自动故障迁移, 以及选择哪个从服务器作为新的主服务器。
虽然 Redis Sentinel 释出为一个单独的可执行文件 redis-sentinel , 但实际上它只是一个运行在特殊模式下的 Redis 服务器, 你可以在启动一个普通 Redis 服务器时通过给定 --sentinel 选项来启动 Redis Sentinel 。
Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务:
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
redis版本:3.0.7
主:6379 ,sentinel:26379
从:6380 ,sentinel:26380
配置
本章主要介绍怎样搭建自动故障转移的reids群集,当主宕机了从接替主成为新的主,宕机的主启动后自动变成了从,其实它和Mysql的双主模式是一样的互为主从;redis群集需要用到redis-sentinel程序和sentinel.conf配置文件。
主配置
vim redis.conf
vim sentinel.conf
群集文件配置
从配置
vim redis.conf
vim sentinel.conf
启动redis
主从都要启动
启动群集监控
主从都要启动
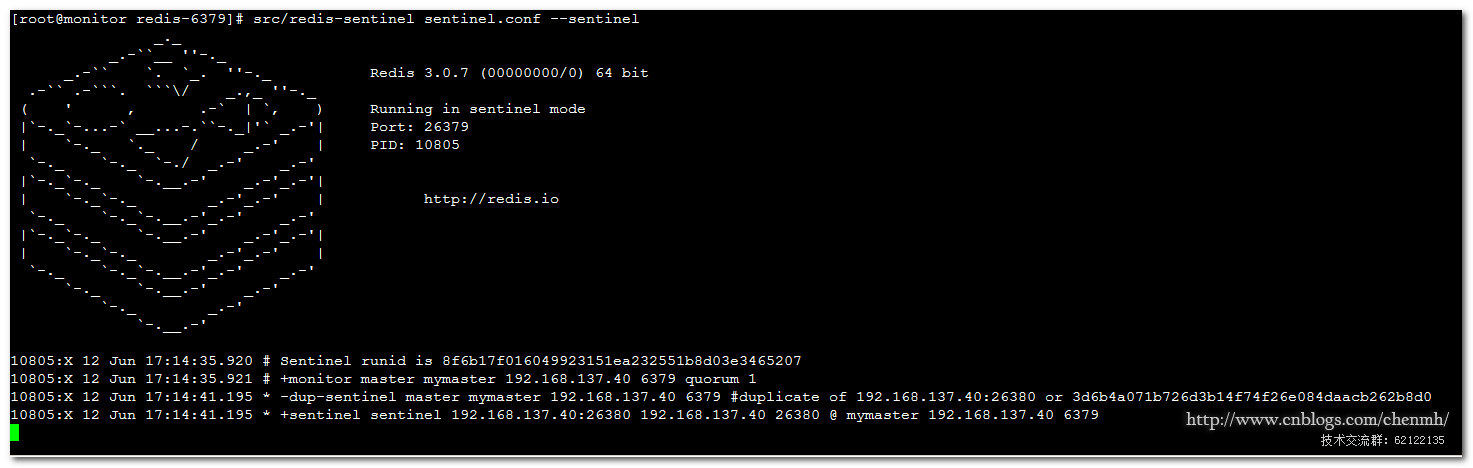

启动报错处理
错误1:
WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
错误2:
WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
错误3:
16433:X 12 Jun 14:52:37.734 * Increased maximum number of open files to 10032 (it was originally set to 1024).
故障切换机制
1. 启动群集后,群集程序默认会在从库的redis文件中加入连接主的配置
2.启动群集之后,群集程序默认会在主从的sentinel.conf文件中加入群集信息
主:
从:
模拟主故障

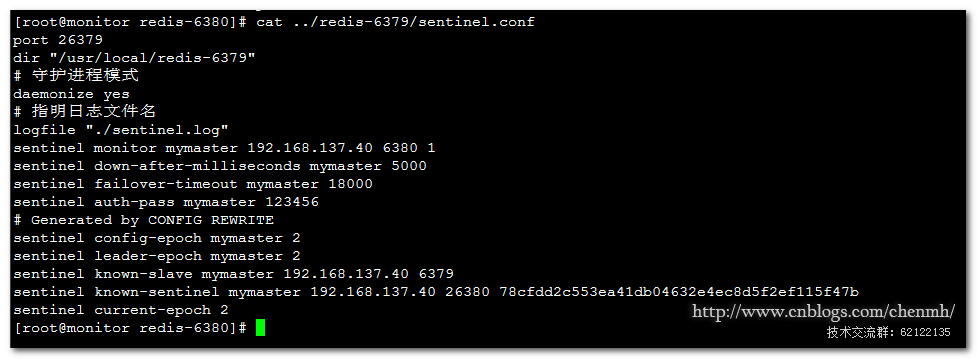
从哨兵配置文件中可以看到当前的主库的已经发生了改变
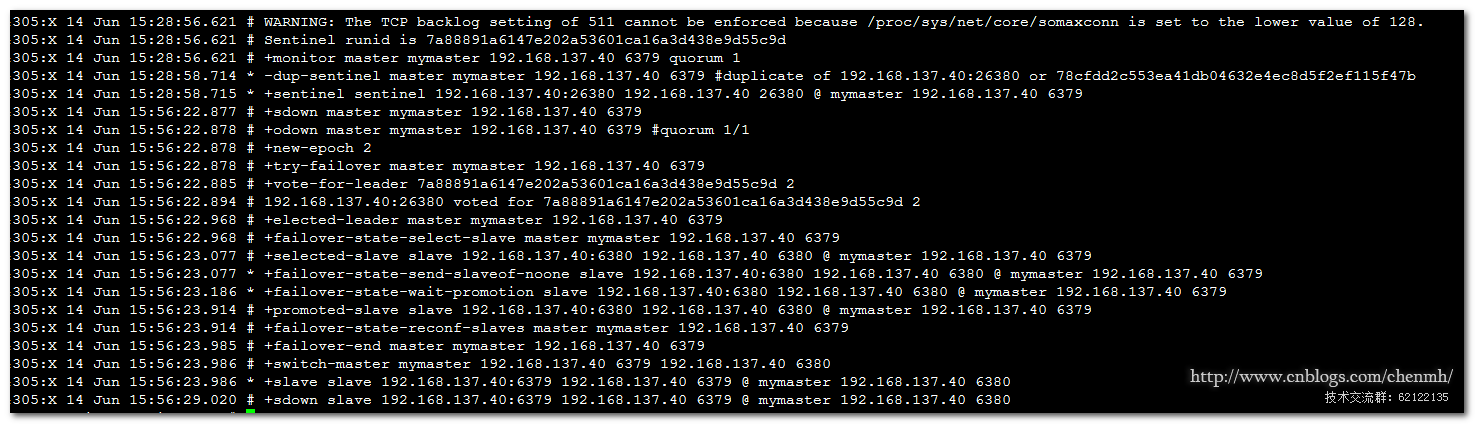
从日志文件也可以看到当前的主已经从6379转换成了6380
redis配置文件官方说明:https://raw.githubusercontent.com/antirez/redis/3.0/redis.conf
redis的哨兵端口26379、26380使用客户端软件无法连接,使用程序可以连接,客户端软件只能直接连接6379和6380端口。使用哨兵监控当主故障后会自动切换从为主,当主启动后就变成了从。有看到别人只配置单哨兵26379的这种情况,这种情况无法保证哨兵程序自身的高可用。
Redis Sentinel 是一个分布式系统, 你可以在一个架构中运行多个 Sentinel 进程(progress), 这些进程使用流言协议(gossip protocols)来接收关于主服务器是否下线的信息, 并使用投票协议(agreement protocols)来决定是否执行自动故障迁移, 以及选择哪个从服务器作为新的主服务器。
虽然 Redis Sentinel 释出为一个单独的可执行文件 redis-sentinel , 但实际上它只是一个运行在特殊模式下的 Redis 服务器, 你可以在启动一个普通 Redis 服务器时通过给定 --sentinel 选项来启动 Redis Sentinel 。
Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务:
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
redis版本:3.0.7
主:6379 ,sentinel:26379
从:6380 ,sentinel:26380
配置
本章主要介绍怎样搭建自动故障转移的reids群集,当主宕机了从接替主成为新的主,宕机的主启动后自动变成了从,其实它和Mysql的双主模式是一样的互为主从;redis群集需要用到redis-sentinel程序和sentinel.conf配置文件。
主配置
vim redis.conf
daemonize yes pidfile /usr/local/redis-6379/run/redis.pid port 6379 tcp-backlog 128 timeout 0 tcp-keepalive 0 loglevel notice logfile "" databases 16 save 900 1 ###save save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes dbfilename dump.rdb ###dbfile dir "/usr/local/redis-6379" masterauth "123456" requirepass "123456" slave-serve-stale-data yes slave-read-only yes repl-diskless-sync no repl-diskless-sync-delay 5 repl-disable-tcp-nodelay no slave-priority 100 appendonly yes appendfilename "appendonly.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes lua-time-limit 5000 slowlog-log-slower-than 10000 slowlog-max-len 128 latency-monitor-threshold 0 notify-keyspace-events "" hash-max-ziplist-entries 512 hash-max-ziplist-value 64 list-max-ziplist-entries 512 list-max-ziplist-value 64 set-max-intset-entries 512 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 hll-sparse-max-bytes 3000 activerehashing yes client-output-buffer-limit normal 0 0 0 client-output-buffer-limit slave 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 hz 10 aof-rewrite-incremental-fsync yes
vim sentinel.conf
群集文件配置
port 26379 dir "/usr/local/redis-6379" # 守护进程模式 daemonize yes # 指明日志文件名 logfile "./sentinel.log" sentinel monitor mymaster 192.168.137.40 6379 1 sentinel down-after-milliseconds mymaster 5000 sentinel failover-timeout mymaster 18000 sentinel auth-pass mymaster 123456
从配置
vim redis.conf
daemonize yes pidfile "/usr/local/redis-6380/run/redis.pid" port 6380 tcp-backlog 128 timeout 0 tcp-keepalive 0 loglevel notice logfile "" databases 16 save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes dbfilename "dump.rdb" dir "/usr/local/redis-6380" masterauth "123456" requirepass "123456" slave-serve-stale-data yes slave-read-only yes repl-diskless-sync no repl-diskless-sync-delay 5 repl-disable-tcp-nodelay no slave-priority 100 appendonly yes appendfilename "appendonly.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes lua-time-limit 5000 slowlog-log-slower-than 10000 slowlog-max-len 128 latency-monitor-threshold 0 notify-keyspace-events "" hash-max-ziplist-entries 512 hash-max-ziplist-value 64 list-max-ziplist-entries 512 list-max-ziplist-value 64 set-max-intset-entries 512 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 hll-sparse-max-bytes 3000 activerehashing yes client-output-buffer-limit normal 0 0 0 client-output-buffer-limit slave 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 hz 10 aof-rewrite-incremental-fsync yes
vim sentinel.conf
#sentinel端口 port 26380 #工作路径,注意路径不要和主重复 dir "/usr/local/redis-6380" # 守护进程模式 daemonize yes # 指明日志文件名 logfile "./sentinel.log" #哨兵监控的master,主从配置一样, sentinel monitor mymaster 192.168.137.40 6379 1 # master或slave多长时间(默认30秒)不能使用后标记为s_down状态。 sentinel down-after-milliseconds mymaster 5000 #若sentinel在该配置值内未能完成failover操作(即故障时master/slave自动切换),则认为本次failover失败。 sentinel failover-timeout mymaster 18000 #设置master和slaves验证密码 sentinel auth-pass mymaster 123456
启动redis
主从都要启动
src/redis-server redis.conf
启动群集监控
主从都要启动
src/redis-sentinel sentinel.conf --sentinel
启动报错处理
错误1:
WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
两个解决方法(overcommit_memory) 1. echo "vm.overcommit_memory=1" > /etc/sysctl.conf 或 vi /etcsysctl.conf , 然后reboot重启机器 2. echo 1 > /proc/sys/vm/overcommit_memory 不需要启机器就生效
overcommit_memory参数说明: 设置内存分配策略(可选,根据服务器的实际情况进行设置) /proc/sys/vm/overcommit_memory 可选值:0、1、2。 0, 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。 1, 表示内核允许分配所有的物理内存,而不管当前的内存状态如何。 2, 表示内核允许分配超过所有物理内存和交换空间总和的内存 注意:redis在dump数据的时候,会fork出一个子进程,理论上child进程所占用的内存和parent是一样的,比如parent占用 的内存为8G,这个时候也要同样分配8G的内存给child,如果内存无法负担,往往会造成redis服务器的down机或者IO负载过高,效率下降。所 以这里比较优化的内存分配策略应该设置为 1(表示内核允许分配所有的物理内存,而不管当前的内存状态如何)。 这里又涉及到Overcommit和OOM。 什么是Overcommit和OOM 在Unix中,当一个用户进程使用malloc()函数申请内存时,假如返回值是NULL,则这个进程知道当前没有可用内存空间,就会做相应的处理工作。许多进程会打印错误信息并退出。 Linux使用另外一种处理方式,它对大部分申请内存的请求都回复"yes",以便能跑更多更大的程序。因为申请内存后,并不会马上使用内存。这种技术叫做Overcommit。 当内存不足时,会发生OOM killer(OOM=out-of-memory)。它会选择杀死一些进程(用户态进程,不是内核线程),以便释放内存。 Overcommit的策略 Linux下overcommit有三种策略(Documentation/vm/overcommit-accounting): 0. 启发式策略。合理的overcommit会被接受,不合理的overcommit会被拒绝。 1. 任何overcommit都会被接受。 2. 当系统分配的内存超过swap+N%*物理RAM(N%由vm.overcommit_ratio决定)时,会拒绝commit。 overcommit的策略通过vm.overcommit_memory设置。 overcommit的百分比由vm.overcommit_ratio设置。 # echo 2 > /proc/sys/vm/overcommit_memory # echo 80 > /proc/sys/vm/overcommit_ratio 当oom-killer发生时,linux会选择杀死哪些进程 选择进程的函数是oom_badness函数(在mm/oom_kill.c中),该函数会计算每个进程的点数(0~1000)。 点数越高,这个进程越有可能被杀死。 每个进程的点数跟oom_score_adj有关,而且oom_score_adj可以被设置(-1000最低,1000最高)。
错误2:
WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
echo 511 > /proc/sys/net/core/somaxconn
错误3:
16433:X 12 Jun 14:52:37.734 * Increased maximum number of open files to 10032 (it was originally set to 1024).
新装的linux默认只有1024,当负载较大时,会经常出现error: too many open files ulimit -a:使用可以查看当前系统的所有限制值 vim /etc/security/limits.conf 在文件的末尾加上 * soft nofile 65535 * hard nofile 65535 执行su或者重新关闭连接用户再执行ulimit -a就可以查看修改后的结果。
故障切换机制
1. 启动群集后,群集程序默认会在从库的redis文件中加入连接主的配置
# Generated by CONFIG REWRITE slaveof 192.168.137.40 6379
2.启动群集之后,群集程序默认会在主从的sentinel.conf文件中加入群集信息
主:
port 26379 dir "/usr/local/redis-6379" # 守护进程模式 daemonize yes # 指明日志文件名 logfile "./sentinel.log" sentinel monitor mymaster 192.168.137.40 6379 1 sentinel down-after-milliseconds mymaster 5000 sentinel failover-timeout mymaster 18000 sentinel auth-pass mymaster 123456# Generated by CONFIG REWRITE
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 1
sentinel known-slave mymaster 192.168.137.40 6380
sentinel known-sentinel mymaster 192.168.137.40 26380 c77c5f64aaad0137a228875e531c7127ceeb5c3f
sentinel current-epoch 1
从:
#sentinel端口 port 26380 #工作路径 dir "/usr/local/redis-6380" # 守护进程模式 daemonize yes # 指明日志文件名 logfile "./sentinel.log" #哨兵监控的master,主从配置一样,在进行主从切换时6379会变成当前的master端口, sentinel monitor mymaster 192.168.137.40 6379 1 # master或slave多长时间(默认30秒)不能使用后标记为s_down状态。 sentinel down-after-milliseconds mymaster 5000 #若sentinel在该配置值内未能完成failover操作(即故障时master/slave自动切换),则认为本次failover失败。 sentinel failover-timeout mymaster 18000 #设置master和slaves验证密码 sentinel auth-pass mymaster 123456 #哨兵程序自动添加的部分 # Generated by CONFIG REWRITE sentinel config-epoch mymaster 0 sentinel leader-epoch mymaster 1 ###指明了当前群集的从库的ip和端口,在主从切换时该值会改变 sentinel known-slave mymaster 192.168.137.40 6380 ###除了当前的哨兵还有哪些监控的哨兵 sentinel known-sentinel mymaster 192.168.137.40 26379 7a88891a6147e202a53601ca16a3d438e9d55c9d sentinel current-epoch 1
模拟主故障
[root@monitor redis-6380]# ps -ef|grep redis root 4171 1 0 14:20 ? 00:00:15 /usr/local/redis-6379/src/redis-server *:6379 root 4175 1 0 14:20 ? 00:00:15 /usr/local/redis-6380/src/redis-server *:6380 root 4305 1 0 15:28 ? 00:00:05 /usr/local/redis-6379/src/redis-sentinel *:26379 [sentinel] root 4306 1 0 15:28 ? 00:00:05 /usr/local/redis-6380/src/redis-sentinel *:26380 [sentinel] root 4337 4144 0 15:56 pts/1 00:00:00 grep redis [root@monitor redis-6380]# kill -9 4171 [root@monitor redis-6380]# ps -ef|grep redis root 4175 1 0 14:20 ? 00:00:15 /usr/local/redis-6380/src/redis-server *:6380 root 4305 1 0 15:28 ? 00:00:05 /usr/local/redis-6379/src/redis-sentinel *:26379 [sentinel] root 4306 1 0 15:28 ? 00:00:05 /usr/local/redis-6380/src/redis-sentinel *:26380 [sentinel] root 4339 4144 0 15:56 pts/1 00:00:00 grep redis [root@monitor redis-6380]#
从哨兵配置文件中可以看到当前的主库的已经发生了改变
从日志文件也可以看到当前的主已经从6379转换成了6380
redis配置文件官方说明:https://raw.githubusercontent.com/antirez/redis/3.0/redis.conf
总结
redis的哨兵端口26379、26380使用客户端软件无法连接,使用程序可以连接,客户端软件只能直接连接6379和6380端口。使用哨兵监控当主故障后会自动切换从为主,当主启动后就变成了从。有看到别人只配置单哨兵26379的这种情况,这种情况无法保证哨兵程序自身的高可用。

相关文章推荐
- 三:redis哨兵模式实现主从故障切换2
- Redis 哨兵模式实现主从故障互切换
- 三:redis哨兵模式实现主从故障切换1
- Redis 哨兵模式实现主从故障互切换
- Redis的哨兵模式第一次主从切换成功,再次进行主从切换就不行了,怎么破?
- Redis集群 - redis主从配置初步:简单主从切换(哨兵模式)
- redis主从切换---Sentinel(哨兵模式)
- Redis集群redis主从自动切换Sentinel(哨兵模式)
- Redis实现主从备份和故障切换
- 结合keepalived实现redis群集高可用故障自动切换
- 通过Keepalived实现Redis Failover自动故障切换功能(整理中) .
- redis主从同步配置和哨兵机制监控master主从切换配置
- java使用Redis7--分布式存储并实现sentinel主从自动切换
- redis实现主从复制和高可用(主从切换)
- 通过Keepalived实现Redis Failover自动故障切换功能[实践分享]
- redis 主从备份自动切换+java代码实现类
- java使用Redis6–sentinel单点故障主从自动切换
- Linux下Redis安装使用,主从模式,哨兵模式与PHP扩展(PHP7适用)
- 使用sentinel进行redis主从切换的操作步骤(failOver故障转移)(何志雄)
- redis实现主从复制和高可用(主从切换)