HashMap 多线程下死循环分析及JDK8修复
2017-07-14 00:00
351 查看
摘要: 有无数文章告诫大家HashMap是非线程安全的,多线程的话使用HashTable、ConcurrentHashMap等,但还是有人顶风作案。本文主要分析其如何出现死循环的(JDK<JDK8),以及JDK8对此如何修复的。
以下就是 transfer 代码:
(图片来源:http://www.cnblogs.com/ITtangtang/p/3948406.html)
单线程正常情况 resize 后会变为:
Thread2:
Thread2:
Thread2:
注意:这里B的 next 已经变成 A 了,下面线程2在执行时会取 B.next
Thread2:(没抢到CPU时间没变化)
Thread2:(没抢到CPU时间没变化)
因为 A 已经插入了,B.next = A,再把 A 插入一次,A.next = B,这里产生了循环
Thread2:(没抢到CPU时间没变化)
由于扩容是按两倍进行扩,即 N 扩为 N + N,因此就会存在低位部分 0 - (N-1),以及高位部分 N - (2N-1), 所以这里分为 loHead (low Head) 和 hiHead (high head)。
通过上面的分析,不难发现循环的产生是因为新链表的顺序跟旧的链表是完全相反的,所以只要保证建新链时还是按照原来的顺序的话就不会产生循环。
JDK8是用 head 和 tail 来保证链表的顺序和之前一样,这样就不会产生循环引用。
简介
当HashMap的容量告急时,HashMap会 resize 进行扩容,扩容的过程就是将 table[] 数组放大两倍,然后通过 transfer 方法进行数据转移,从老的 table 转移到新的 table 数组里。以下就是 transfer 代码:
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry e = src[j];
if (e != null) {
src[j] = null;
do {
Entry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}重现
当两个线程同时进行 put 操作时,基本同时会达到 HashMap 的存储阈值,所以也就会并发进行 resize,各自有一个新的 table[] 数组,但是老的数组是同一个。补充HashMap结构
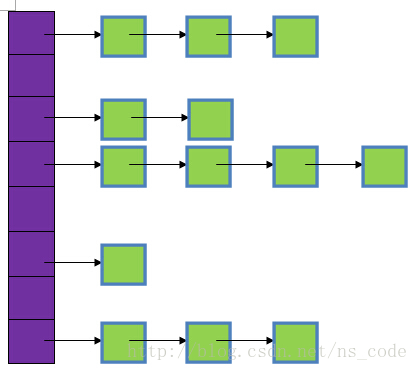
HashMap 是一个数组加链表的结构,一个数据put入 HashMap 先计算它的 hashcode, 然后取模后得到其在 table 数组的下标 index, 再将该数据节点放到 index 处的链表中。(图片来源:http://www.cnblogs.com/ITtangtang/p/3948406.html)
情景假设
现假设 table 某下标 i 处的链表如下:i => A => B => C
单线程正常情况 resize 后会变为:
i => B => A ... j => C
多线程Resize
开始执行 transfer(下面 e 和 next 都是 transfer 中变量)第一步:
Thread1:e = A next = B ========= newtable[i] => null
Thread2:
e = A next = B ========= newtable[i] => null
第二步:
Thread1:(没有抢到CPU时间所以没变化)e = A next = B ========= newtable[i] => null
Thread2:
e = B next = C ========= newtable[i] => A
第三步:
Thread1:(没有抢到CPU时间所以没变化)e = A next = B ========= newtable[i] => null
Thread2:
注意:这里B的 next 已经变成 A 了,下面线程2在执行时会取 B.next
e = C next = null ========= newtable[i] => B => A
第四步:
Thread1:e = B next = A ========= newtable[i] => A
Thread2:(没抢到CPU时间没变化)
e = C next = null ========= newtable[i] => B => A
第五步:
Thread1:e = A next = null ========= newtable[i] => B => A
Thread2:(没抢到CPU时间没变化)
e = C next = null ========= newtable[i] => B => A
第六步:
Thread1:因为 A 已经插入了,B.next = A,再把 A 插入一次,A.next = B,这里产生了循环
e = null next = null ========= newtable[i] => A <=> B
Thread2:(没抢到CPU时间没变化)
e = C next = null ========= newtable[i] => B => A
死循环
当执行 get 时,当key 正好被分到那个 table[i] 上时,遍历链表就会产生循环。JDK8的修复
JDK8 将 HashMap 的结构作了下修改,将原来的链表部分改为数据少时仍然链表,当超过一定数量后变换为红黑树,这里主要讨论在链表时跟之前有什么不同。链表部分
链表部分对应上面 transfer 的代码:Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}由于扩容是按两倍进行扩,即 N 扩为 N + N,因此就会存在低位部分 0 - (N-1),以及高位部分 N - (2N-1), 所以这里分为 loHead (low Head) 和 hiHead (high head)。
通过上面的分析,不难发现循环的产生是因为新链表的顺序跟旧的链表是完全相反的,所以只要保证建新链时还是按照原来的顺序的话就不会产生循环。
JDK8是用 head 和 tail 来保证链表的顺序和之前一样,这样就不会产生循环引用。
树部分
树部分处理基本跟链表一直,先建立新链表,然后使用新链表进行树化。final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
TreeNode<K,V> b = this;
// Relink into lo and hi lists, preserving order
TreeNode<K,V> loHead = null, loTail = null;
TreeNode<K,V> hiHead = null, hiTail = null;
int lc = 0, hc = 0;
for (TreeNode<K,V> e = b, next; e != null; e = next) {
next = (TreeNode<K,V>)e.next;
e.next = null;
if ((e.hash & bit) == 0) {
if ((e.prev = loTail) == null)
loHead = e;
else
loTail.next = e;
loTail = e;
++lc;
}
else {
if ((e.prev = hiTail) == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
++hc;
}
}
============================ 一直到这里逻辑跟链表几乎一样,核心还是保持顺序、分高低位
if (loHead != null) {
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead;
if (hiHead != null) // (else is already treeified)
loHead.treeify(tab); <============= 这里进行树化转化
}
}
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}
}总结:
虽然修复了死循环的BUG,但是HashMap 还是非线程安全类,仍然会产生数据丢失等问题。
相关文章推荐
- HashMap多线程引起的死循环的原因分析
- HashMap因为多线程未同步时导致put进的元素get出来为null的分析(转)
- HashMap多线程调用下的死循环问题
- HashMap多线程并发问题分析
- HashMap多线程并发问题分析
- 4、关于HashMap在多线程下的不安全分析
- HashMap多线程并发问题分析
- HashMap在并发环境下的死循环分析
- HashMap多线程死循环问题
- Java 容器源码分析之HashMap多线程并发问题分析
- 多线程下HashMap的死循环问题
- 分析多线程并发写HashMap线程被hang住的原因
- HashMap 死循环 CPU100%的问题分析
- HashMap死循环的原因分析
- HashMap多线程并发问题分析
- Java HashMap多线程下为什么会死循环?
- 多线程下HashMap的死循环问题
- HashMap多线程并发问题分析
- HashMap多线程并发问题分析
- HashMap多线程并发问题分析(rehash分析)