SQL Server 索引的自动维护 <第十三篇>
2017-07-13 14:09
344 查看
在有大量事务的数据库中,表和索引随着时间的推移而碎片化。因此,为了增进性能,应该定期检查表和索引的碎片,并对具有大量碎片的进行整理。
1、确定当前数据库中所有需要分析碎片的表。
2、确定所有表和索引的碎片。
3、考虑一下因素以确定需要进行碎片整理的表和索引。
高的碎片水平-avg_fragmentation_in_percent大于20%;
不是非常小的表或索引-也就是page_count大于8的;
4、整理具有大量碎片的表和索引;
这里给出一个样板SQL存储过程,它执行以下操作;
遍历系统上的所有数据库并确认符合碎片条件的每个数据库中表上的索引,并将它们保存到一个临时表中;
根据碎片水平,重新整理碎片较少的索引并重建碎片很多的索引。
为了自动化碎片分析过程,可以从SQL Server企业管理器中用以下简单的步骤创建一个SQL Server任务。
1、开启SQL Server代理;
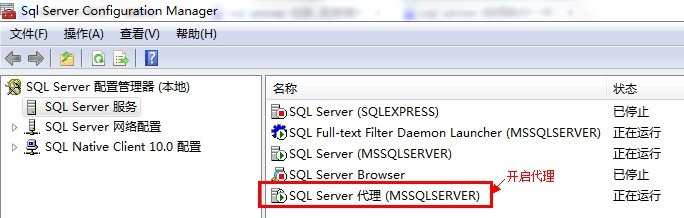
2、打开Management Studio,右键单击,选择新建=》任务;
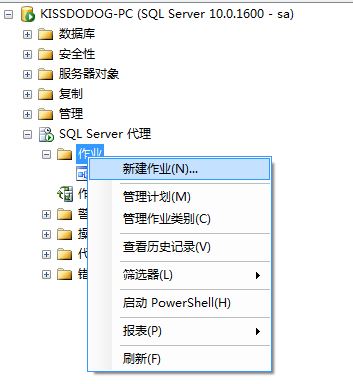
3、在新建任务对话框的“常规”页面中,输入任务名称和其他细节:

4、在新建任务对话框的“步骤”页面中,单击“新建”并输入用户数据库的SQL命令。

5、在新建任务步骤对话框“高级”页面上,输入报告碎片分析结果的输出文件名称:

6、单击“确定”按钮,返回新建作业对话框;
7、在新建任务对话框“计划”页面,单击“新建计划”,并输入运行SQL Server任务的合适计划:
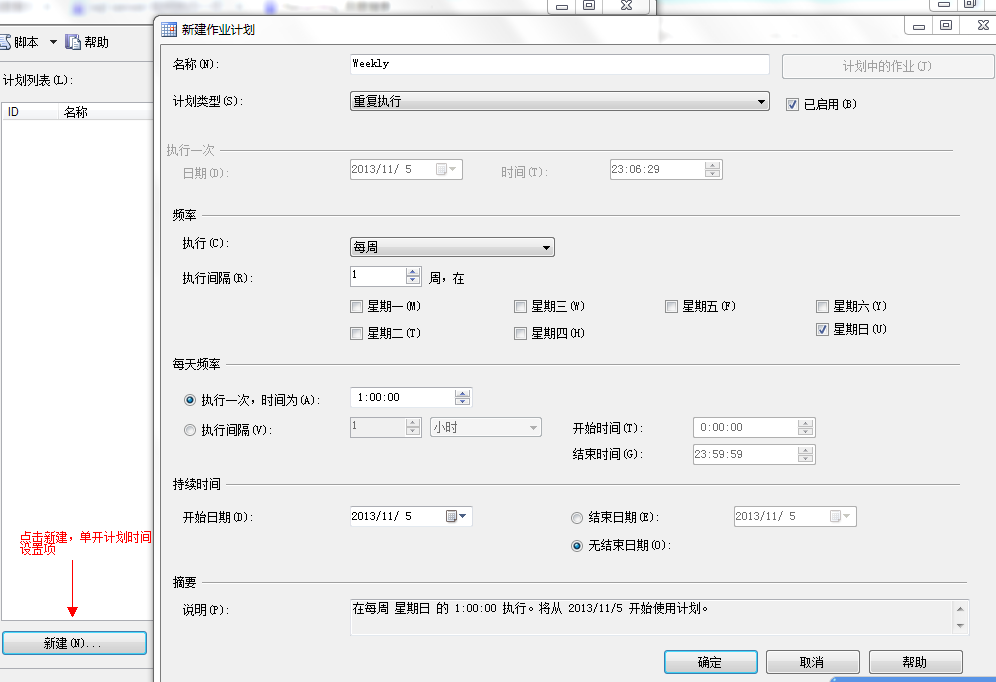
安排这个存储过程在非高峰执行。为了确定数据库的数据库模式,记录整天的SQL Server:SQL Statistics\Batch Requests/sec性能计数器,它将展示数据库负载的波动。
8、单击“确定”按钮,返回新建任务对话框。
9、输入所有信息后,单击新建任务对话框中的“确定”按钮创建SQL Server任务。创建计划在一个固定时间间隔(每周)运行sp_indexDefrag存储过程的SQL Server任务。
10、确保SQL Server代理运行,这样SQL Server任务将自动根据设置的计划运行。
这个SQL任务将在每个星期天的凌晨1点分析每个数据库并且进行碎片整理。
1、确定当前数据库中所有需要分析碎片的表。
2、确定所有表和索引的碎片。
3、考虑一下因素以确定需要进行碎片整理的表和索引。
高的碎片水平-avg_fragmentation_in_percent大于20%;
不是非常小的表或索引-也就是page_count大于8的;
4、整理具有大量碎片的表和索引;
这里给出一个样板SQL存储过程,它执行以下操作;
遍历系统上的所有数据库并确认符合碎片条件的每个数据库中表上的索引,并将它们保存到一个临时表中;
根据碎片水平,重新整理碎片较少的索引并重建碎片很多的索引。
CREATE PROCEDURE IndexDefrag
AS
DECLARE @DBName NVARCHAR(255)
,@TableName NVARCHAR(255)
,@SchemaName NVARCHAR(255)
,@IndexName NVARCHAR(255)
,@PctFrag DECIMAL
DECLARE @Defrag NVARCHAR(MAX)
IF EXISTS (SELECT * FROM sys.objects WHERE OBJECT_ID = OBJECT_ID(N'#Frag'))
DROP TABLE #Frag
CREATE TABLE #Frag
(DBName NVARCHAR(255)
,TableName NVARCHAR(255)
,SchemaName NVARCHAR(255)
,IndexName NVARCHAR(255)
,AvgFragment DECIMAL)
EXEC sp_msforeachdb 'INSERT INTO #Frag (
DBName,
TableName,
SchemaName,
IndexName,
AvgFragment
) SELECT ''?'' AS DBName
,t.Name AS TableName
,sc.Name AS SchemaName
,i.name AS IndexName
,s.avg_fragmentation_in_percent
FROM ?.sys.dm_db_index_physical_stats(DB_ID(''?''), NULL, NULL,
NULL, ''Sampled'') AS s
JOIN ?.sys.indexes i
ON s.Object_Id = i.Object_id
AND s.Index_id = i.Index_id
JOIN ?.sys.tables t
ON i.Object_id = t.Object_Id
JOIN ?.sys.schemas sc
ON t.schema_id = sc.SCHEMA_ID
WHERE s.avg_fragmentation_in_percent > 20
AND t.TYPE = ''U''
AND s.page_count > 8
ORDER BY TableName,IndexName'
DECLARE cList CURSOR
FOR SELECT * FROM #Frag
OPEN cList
FETCH NEXT FROM cList
INTO @DBName, @TableName,@SchemaName,@IndexName,@PctFrag
WHILE @@FETCH_STATUS = 0
BEGIN
IF @PctFrag BETWEEN 20.0 AND 40.0
BEGIN
SET @Defrag = N'ALTER INDEX ' + @IndexName + ' ON ' + @DBName + '.' + @SchemaName + '.' + @TableName + ' REORGANIZE'
EXEC sp_executesql @Defrag
PRINT 'Reorganize index: ' + @DBName + '.' + @SchemaName + '.' + @TableName +'.' + @IndexName
END
ELSE IF @PctFrag > 40.0
BEGIN
SET @Defrag = N'ALTER INDEX ' + @IndexName + ' ON ' + @DBName + '.' + @SchemaName + '.' + @TableName + ' REBUILD'
EXEC sp_executesql @Defrag
PRINT 'Rebuild index: '+ @DBName + '.' + @SchemaName + '.' + @TableName +'.' + @IndexName
END
FETCH NEXT FROM cList
INTO @DBName, @TableName,@SchemaName,@IndexName,@PctFrag
END
CLOSE cList
DEALLOCATE cList
DROP TABLE #Frag为了自动化碎片分析过程,可以从SQL Server企业管理器中用以下简单的步骤创建一个SQL Server任务。
1、开启SQL Server代理;
2、打开Management Studio,右键单击,选择新建=》任务;
3、在新建任务对话框的“常规”页面中,输入任务名称和其他细节:
4、在新建任务对话框的“步骤”页面中,单击“新建”并输入用户数据库的SQL命令。
5、在新建任务步骤对话框“高级”页面上,输入报告碎片分析结果的输出文件名称:
6、单击“确定”按钮,返回新建作业对话框;
7、在新建任务对话框“计划”页面,单击“新建计划”,并输入运行SQL Server任务的合适计划:
安排这个存储过程在非高峰执行。为了确定数据库的数据库模式,记录整天的SQL Server:SQL Statistics\Batch Requests/sec性能计数器,它将展示数据库负载的波动。
8、单击“确定”按钮,返回新建任务对话框。
9、输入所有信息后,单击新建任务对话框中的“确定”按钮创建SQL Server任务。创建计划在一个固定时间间隔(每周)运行sp_indexDefrag存储过程的SQL Server任务。
10、确保SQL Server代理运行,这样SQL Server任务将自动根据设置的计划运行。
这个SQL任务将在每个星期天的凌晨1点分析每个数据库并且进行碎片整理。

相关文章推荐
- SQL Server 索引的自动维护 <第十三篇>
- SQL Server 索引的自动维护 <第十三篇>
- SQL Server 索引的自动维护 <第十三篇>
- SQL Server索引的维护 - 索引碎片、填充因子 <第三篇>
- SQL Server索引的维护 - 索引碎片、填充因子 <第三篇>
- SQL Server索引的维护 - 索引碎片、填充因子 <第三篇>
- SQL Server索引的维护 - 索引碎片、填充因子 <第三篇>
- SQL Server索引的维护 - 索引碎片、填充因子 <第三篇>
- Hbase 学习笔记(一) Hbase的物理模型 Hbase为每个值维护了一个多级索引,即<key, column family, column name, timestamp>
- SQL Server索引语法 <第四篇>
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>
- SQL Server索引 - 非聚集索引 <第七篇>
- SQL Server - 聚集索引 <第六篇>
- SQL Server索引设计 <第五篇>
- SQL Server索引设计 <第五篇>
- SQL Server 索引 之 书签查找 <第十一篇>
- SQL Server索引 - 非聚集索引 <第七篇>
- SQL Server索引 - 聚集索引、非聚集索引、非聚集唯一索引 <第八篇>
- SQL Server 2012笔记分享-40:自动维护索引
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>