面试干货!21个必知数据科学面试题和答案
2017-06-28 17:21
621 查看
最近KDnuggets上发的“20个问题来分辨真假数据科学家”这篇文章非常热门,获得了一月的阅读量排行首位。
但是这些问题并没有提供答案,所以KDnuggets的小编们聚在一起写出了这些问题的答案。我还加了一个特别提问——第21问,是20个问题里没有的。
下面是答案。
Q1.解释什么是正则化,以及它为什么有用。
回答者:Matthew Mayo
正则化是添加一个调优参数的过程模型来引导平滑以防止过拟合。(参加KDnuggets文章《过拟合》)
这通常是通过添加一个常数到现有的权向量。这个常数通常要么是L1(Lasso)要么是L2(ridge),但实际上可以是任何标准。该模型的测算结果的下一步应该是将正则化训练集计算的损失函数的均值最小化。
Xavier Amatriain在这里向那些感兴趣的人清楚的展示了L1和L2正则化之间的比较。
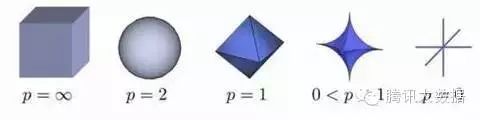
图1.Lp球:p的值减少,相应的L-p空间的大小也会减少。
Q2.你最崇拜哪些数据科学家和创业公司?
回答者:Gregory Piatetsky
这个问题没有标准答案,下面是我个人最崇拜的12名数据科学家,排名不分先后。

Geoff Hinton, Yann LeCun, 和 Yoshua Bengio-因他们对神经网络的坚持不懈的研究,和开启了当前深度学习的革命。
Demis Hassabis,因他在DeepMind的杰出表现——在Atari游戏中实现了人或超人的表现和最近Go的表现。
来自datakind的Jake Porway和芝加哥大学DSSG的Rayid Ghani因他们让数据科学对社会产生贡献。
DJ Patil,美国第一首席数据科学家,利用数据科学使美国政府工作效率更高。
Kirk D. Borne,因其在大众传媒中的影响力和领导力。
Claudia Perlich,因其在广告生态系统的贡献,和作为kdd-2014的领头人。
Hilary Mason在Bitly杰出的工作,和作为一个大数据的明星激发他人。
Usama Fayyad,展示了其领导力,为KDD和数据科学设立了高目标,这帮助我和成千上万的人不断激励自己做到最好。
Hadley Wickham,因他在数据科学和数据可视化方面的出色的成果,包括dplyr,ggplot2,和RStudio。
数据科学领域里有太多优秀的创业公司,但我不会在这里列出它们,以避免利益冲突。
Q3.如何验证一个用多元回归生成的对定量结果变量的预测模型。
回答者:Matthew Mayo
模型验证方法:
如果模型预测的值远远超出响应变量范围,这将立即显示较差的估计或模型不准确。
如果值看似是合理的,检查参数;下列情况表示较差估计或多重共线性:预期相反的迹象,不寻常的或大或小的值,或添加新数据时观察到不一致。
利用该模型预测新的数据,并使用计算的系数(平方)作为模型的有效性措施。
使用数据拆分,以形成一个单独的数据集,用于估计模型参数,另一个用于验证预测。
如果数据集包含一个实例的较小数字,用对折重新采样,测量效度与R平方和均方误差(MSE)。
Q4.解释准确率和召回率。它们和ROC曲线有什么关系?
回答者:Gregory Piatetsky
这是kdnuggets常见问题的答案:精度和召回
计算精度和召回其实相当容易。想象一下10000例中有100例负数。你想预测哪一个是积极的,你选择200个以更好的机会来捕捉100个积极的案例。你记录下你预测的ID,当你得到实际结果时,你总结你是对的或错的。以下是正确或错误的四种可能:
TN/真阴性:例阴性且预测阴性
TP/真阳性:例阳性且预测阳性
FN/假阴性:例阳性而预测阴性
FP/假阳性:例阴性而预测阳性
意义何在?现在你要计算10000个例子中有多少进入了每一个bucket:

现在,你的雇主会问你三个问题:
1.你的预测正确率有几成?
你回答:确切值是(9760+60)除以10000=98.2%
2.你获得阳性的例子占多少比例?
你回答:召回比例为60除以100=60%
3.正值预测的百分比多少?
你回答:精确值是60除以200=30%
看一个维基上的精度和召回的优秀范例。
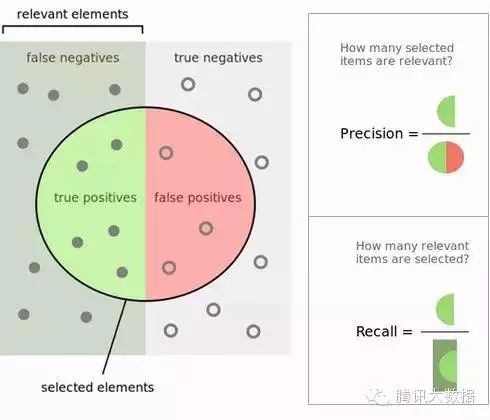
图4.精度和召回
ROC曲线代表了灵敏度(召回)与特异性(不准确)之间的关系,常用来衡量二元分类的性能。然而,在处理高倾斜度的数据集的时候,精度-召回(PR)曲线给出一个更具代表性的表现。见Quora回答:ROC曲线和精度-召回曲线之间的区别是什么?。
Q5.如何证明你对一个算法的改进确实比什么都不做更好?
回答者:Anmol Rajpurohit
我们会在追求快速创新中(又名“快速成名”)经常看到,违反科学方法的原则导致误导性的创新,即有吸引力的观点却没有经过严格的验证。一个这样的场景是,对于一个给定的任务:提高算法,产生更好的结果,你可能会有几个关于潜在的改善想法。
人们通常会产生的一个明显冲动是尽快公布这些想法,并要求尽快实施它们。当被问及支持数据,往往是共享的是有限的结果,这是很有可能受到选择偏差的影响(已知或未知)或一个误导性的全局最小值(由于缺乏各种合适的测试数据)。
数据科学家不让自己的情绪操控自己的逻辑推理。但是确切的方法来证明你对一个算法的改进确实比什么都不做更好将取决于实际情况,有几个共同的指导方针:
确保性能比较的测试数据没有选择偏差
确保测试数据足够,以成为各种真实性的数据的代表(有助于避免过拟合)
确保“受控实验”的原则,即在比较运行的原始算法和新算法的表现的时候,性能、测试环境(硬件等)方面必须是完全相同的。
确保结果是可重复的,当接近类似的结果出现的时候
检查结果是否反映局部极大值/极小值或全局极大值/最小值
来实现上述方针的一种常见的方式是通过A/B测试,这里面两个版本的算法是,在随机分割的两者之间不停地运行在类似的环境中的相当长的时间和输入数据。这种方法是特别常见的网络分析方法。
Q6.什么是根本原因分析?
回答者:Gregory Piatetsky
根据维基百科:
根本原因分析(RCA)是一种用于识别错误或问题的根源的解决方法。一个因素如果从problem-fault-sequence的循环中删除后,阻止了最终的不良事件重复出现,则被认为是其根源;而一个因果因素则影响一个事件的结果,但不其是根本原因。
根本原因分析最初用于分析工业事故,但现在广泛应用于其他领域,如医疗、项目管理、软件测试。
这是一个来自明尼苏达州的实用根本原因分析工具包。
本质上,你可以找到问题的根源和原因的关系反复问“为什么”,直到找到问题的根源。这种技术通常被称为“5个为什么”,当时涉及到的问题可能比5个更少或更多。
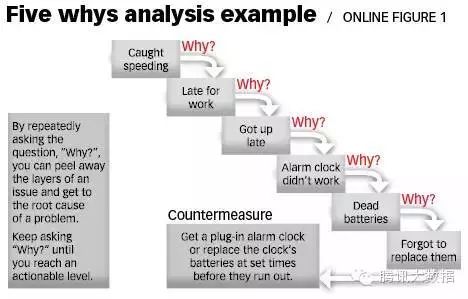
图 “5个为什么”分析实例,来自《根本原因分析的艺术》
Q7.你是否熟悉价格优化、价格弹性、库存管理、竞争情报?举例说明。
回答者:Gregory Piatetsky
这些问题属于经济学范畴,不会经常用于数据科学家面试,但是值得了解。
价格优化是使用数学工具来确定客户会如何应对不同渠道产品和服务的不同价格。
大数据和数据挖掘使得个性化的价格优化成为可能。现在像亚马逊这样的公司甚至可以进一步优化,对不同的游客根据他们的购买历史显示不同的价格,尽管有强烈的争论这否公平。
通常所说的价格弹性是指需求的价格弹性,是对价格敏感性的衡量。它的计算方法是:
需求的价格弹性=需求量变动%÷价格变动%。
同样,供应的价格弹性是一个经济衡量标准,显示了产品或服务的变化如何响应价格变化。
库存管理是一个企业在生产过程中使用的产品的订购、储存和使用的监督和控制,它将销售的产品和销售的成品数量进行监督和控制。
维基百科定义:
竞争情报:定义、收集、分析和分发有关产品、客户、竞争对手和所需环境的任何方面的情报,以支持管理人员和管理者为组织做出战略决策的环境。
像Google Trends, Alexa, Compete这样的工具可以用来确定趋势和分析你的竞争对手的网站。
下面是一些有用的资源:
竞争情报的报告指标by Avinash Kaushik
37款监视你的竞争对手的最好的营销工具from KISSmetrics
来自10位专家的10款最佳竞争情报工具
Q8.什么是统计检定力?
回答者:Gregory Piatetsky
维基百科定义二元假设检验的统计检定力或灵敏度为测试正确率拒绝零假设的概率(H0)在备择假设(H1)是真的。
换句话说,统计检定力是一种可能性研究,研究将检测到的效果时效果为本。统计能力越高,你就越不可能犯第二类错误(结论是没有效果的,然而事实上有)。
这里有一些工具来计算统计检定力。
Q9.解释什么是重抽样方法和它们为什么有用。并说明它们的局限。
回答者:Gregory Piatetsky
经典的统计参数检验比较理论抽样分布。重采样的数据驱动的,而不是理论驱动的方法,这是基于相同的样本内重复采样。
重采样指的是这样做的方法之一
估计样本统计精度(中位数、方差、百分位数)利用可用数据的子集(折叠)或随机抽取的一组数据点置换(引导)
在进行意义测试时,在数据点上交换标签(置换测试),也叫做精确测试,随机测试,或是再随机测试)
利用随机子集验证模型(引导,交叉验证)
维基百科里关于bootstrapping, jackknifing。
见How to Check Hypotheses with Bootstrap and Apache Spark

这里是一个很好重采样统计的概述。
Q10.有太多假阳性或太多假阴性哪个相比之下更好?说明原因。
回答者:Devendra Desale
这取决于问题本身以及我们正在试图解决的问题领域。
在医学检验中,假阴性可能会给病人和医生提供一个虚假的安慰,表面上看它不存在的时候,它实际上是存在的。这有时会导致不恰当的或不充分的治疗病人和他们的疾病。因此,人们会希望有很多假阳性。
对于垃圾邮件过滤,当垃圾邮件过滤或垃圾邮件拦截技术错误地将一个合法的电子邮件信息归类为垃圾邮件,并影响其投递结果时,会出现假阳性。虽然大多数反垃圾邮件策略阻止和过滤垃圾邮件的比例很高,排除没有意义假阳性结果是一个更艰巨的任务。所以,我们更倾向于假阴性而不是假阳性。
Q11.什么是选择偏差,为什么它是重要的,你如何避免它?
回答者:Matthew Mayo
选择偏差,一般而言,是由于一个非随机群体样本造成的问题。例如,如果一个给定的样本的100个测试案例是一个60 / 20/ 15/ 5的4个类,实际上发生在在群体中相对相等的数字,那么一个给定的模型可能会造成错误的假设,概率可能取决于预测因素。避免非随机样本是处理选择偏差最好的方式,但是这是不切实际的。可以引入技术,如重新采样,和提高权重的策略,以帮助解决问题。
Q12. 举例说明如何使用实验设计回答有关用户行为的问题。
回答者:Bhavya Geethika.
步骤1.制定研究问题
页面加载时间对用户满意度评级的影响有哪些?
步骤2.确定变量
我们确定原因和结果。独立变量——页面加载时间,非独立变量——用户满意评级
步骤3.生成假说
减少页面下载时间能够影响到用户对一个网页的满意度评级。在这里,我们分析的因素是页面加载时间。

图12.一个有缺陷的实验设计(漫画)
步骤4.确定实验设计
我们考量实验的复杂性,也就是说改变一个因素或多个因素,同时在这种情况下,我们用阶乘设计(2^k设计)。选择设计也是基于目标的类型(比较、筛选、响应面)和许多其他因素。
在这里我们也确定包含参与者/参与者之间及二者混合模型。如,有两个版本的页面,一个版本的购买按钮(行动呼吁)在左边,另一个版本的在右边。
包含参与者设计——所有用户组看到两个版本
参与者之间设计——一组用户看到版本A,娶她用户组看到版本B。
步骤5.开发实验任务和过程:
详细描述实验的步骤、用于测量用户行为的工具,并制定目标和成功标准。收集有关用户参与度的定性数据,以便统计分析。
步骤6.确定操作步骤和测量标准
操作:一个因素的级别将被控制,其他的将用于操作,我们还要确定行为上的标准:
在提示和行为发生之间的持续时间(用户点击购买了产品花了多长时间)。
频率-行为发生的次数(用户点击次数的一个给定的页面在一个时间)
持续-特定行为持续时间(添加所有产品的时间)
程度-行为发生时的强烈的冲动(用户购买商品有多快)
步骤7:分析结果
识别用户行为数据,假说成立,或根据观察结果反驳例子:用户满意度评级与页面加载时间的比重是多少。
Q13“长”数据和“宽”数据有什么不同之处?
回答者:Gregory Piatetsky
在大多数数据挖掘/数据科学应用记录(行)比特性(列)更多——这些数据有时被称为“高”(或“长”)的数据。
在某些应用程序中,如基因组学和生物信息学,你可能只有一个小数量的记录(病人),如100,或许是20000为每个病人的观察。为了“高”工作数据的标准方法将导致过度拟合数据,所以需要特殊的方法。
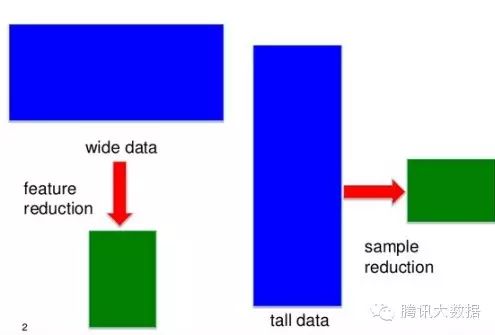
图13.对于高数据和宽数据不同的方法,与表示稀疏筛查确切数据简化,by Jieping Ye。
问题不仅仅是重塑数据(这里是有用的R包),还要避免假阳性,通过减少特征找到最相关的数据。
套索等方法减少特性和稀疏覆盖在统计学习:套索和概括,由Hastie Tibshirani,Wainwright。(你可以免费下载PDF的书)套索等方法减少特性,在“统计学习稀疏”中很好地包含了:《套索和概括》by Hastie, Tibshirani, and Wainwright(你可以免费下载PDF的书)
Q14你用什么方法确定一篇文章(比如报纸上的)中公布的统计数字是错误的或者是为了支持作者观点,而不是关于某主题正确全面的事实信息?
一个简单的规则,由Zack Lipton建议的:如果一些统计数据发表在报纸上,那么它们是错的。这里有一个更严重的答案,来自Anmol Rajpurohit:每一个媒体组织都有目标受众。这个选择很大地影响着决策,如这篇文章的发布、如何缩写一篇文章,一篇文章强调的哪一部分,如何叙述一个给定的事件等。
确定发表任何文章统计的有效性,第一个步骤是检查出版机构和它的目标受众。即使是相同的新闻涉及的统计数据,你会注意到它的出版非常不同,在福克斯新闻、《华尔街日报》、ACM/IEEE期刊都不一样。因此,数据科学家很聪明的知道在哪里获取消息(以及从来源来判断事件的可信度!)。
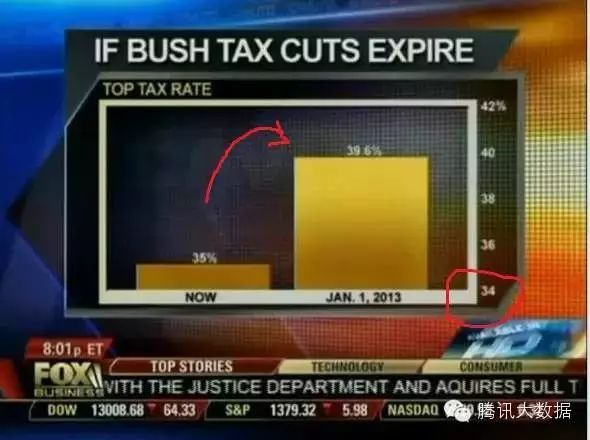
图14a:福克斯新闻上的一个误导性条形图的例子
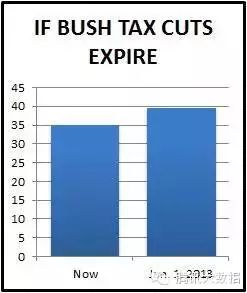
图14b:如何客观地呈现相同的数据 来自5 Ways to Avoid Being Fooled By Statistics
作者经常试图隐藏他们研究中的不足,通过精明的讲故事和省略重要细节,跳到提出诱人的错误见解。因此,用拇指法则确定文章包含误导统计推断,就是检查这篇文章是否包含了统计方法,和统计方法相关的选择上的细节限制。找一些关键词如“样本”“误差”等等。虽然关于什么样的样本大小或误差是合适的没有完美的答案,但这些属性一定要在阅读结果的时候牢记。
首先,一篇可靠的文章必须没有任何未经证实的主张。所有的观点必须有过去的研究的支持。否则,必须明确将其区分为“意见”,而不是一个观点。其次,仅仅因为一篇文章是著名的研究论文,并不意味着它是使用适当的研究方向的论文。这可以通过阅读这些称为研究论文“全部”,和独立判断他们的相关文章来验证。最后,虽然最终结果可能看起来是最有趣的部分,但是通常是致命地跳过了细节研究方法(和发现错误、偏差等)。
理想情况下,我希望所有这类文章都发表他们的基础研究数据方法。这样,文章可以实现真正的可信,每个人都可以自由分析数据和应用研究方法,自己得出结果。
Q15解释Edward Tufte“图表垃圾”的概念。
回答者:Gregory Piatetsky
图标垃圾指的是所有的图表和图形视觉元素没有充分理解表示在图上的信息,或者没有引起观看者对这个信息的注意。
图标垃圾这个术语是由Edward Tufte在他1983年的书《定量信息的视觉显示》里提出的。
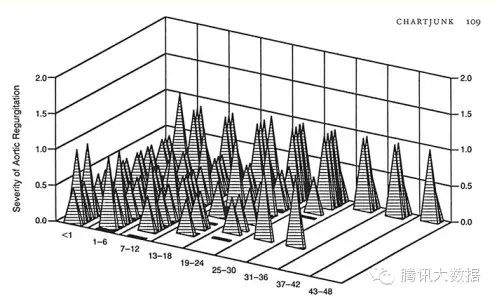
图15所示。Tufte写道:“一种无意的Necker错觉,两个平面翻转到前面。一些金字塔隐藏其他;一个变量(愚蠢的金字塔的堆叠深度)没有标签或规模。”
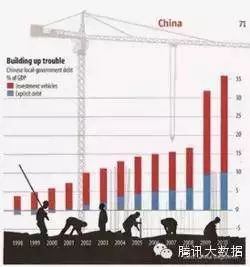
图标垃圾的的这个例子是一个更现代的例子,很难理解excel使用者画出的柱状图,因为“工人”和“起重机”掩盖了他们。
这种装饰的问题是,他们迫使读者更加困难而非必要地去发现数据的含义。
Q16你会如何筛查异常值?如果发现它会怎样处理?
回答者:Bhavya Geethika.
筛选异常值的方法有z-scores, modified z-score, box plots, Grubb's test,Tietjen-Moore测试指数平滑法,Kimber测试指数分布和移动窗口滤波算法。然而比较详细的两个方法是:
Inter Quartile Range
An outlier is a point of data that lies over 1.5 IQRs below the first quartile (Q1) or above third quartile (Q3) in a given data set.
High = (Q3) + 1.5 IQR
Low = (Q1) - 1.5 IQR
Tukey Method
It uses interquartile range to filter very large or very small numbers. It is practically the same method as above except that it uses the concept of "fences". The two values of fences are:
Low outliers = Q1 - 1.5(Q3 - Q1) = Q1 - 1.5(IQR)
High outliers = Q3 + 1.5(Q3 - Q1) = Q3 + 1.5(IQR)
在这个区域外的任何值都是异常值
当你发现异常值时,你不应该不对它进行一个定性评估就删除它,因为这样你改变了数据,使其不再纯粹。重要的是要在理解分析的背景下或者说重要的是“为什么的问题——为什么异常值不同于其他数据点?”
这个原因是至关重要的。如果归因于异常值错误,你可能把它排除,但如果他们意味着一种新趋势、模式或显示一个有价值的深度数据,你应该保留它。
Q17如何使用极值理论、蒙特卡洛模拟或其他数学统计(或别的什么)正确估计非常罕见事件的可能性?
回答者:Matthew Mayo.
极值理论(EVT)侧重于罕见的事件和极端,而不是经典的统计方法,集中的平均行为。EVT的州有3种分布模型的极端数据点所需要的一组随机观察一些地理分布:Gumble,f,和威布尔分布,也称为极值分布(EVD)1、2和3分别。
EVT的状态,如果你从一个给定的生成N数据集分布,然后创建一个新的数据集只包含这些N的最大值的数据集,这种新的数据集只会准确地描述了EVD分布之一:耿贝尔,f,或者威布尔。广义极值分布(GEV),然后,一个模型结合3 EVT模型以及EVD模型。
知道模型用于建模数据,我们可以使用模型来适应数据,然后评估。一旦发现最好的拟合模型,分析可以执行,包括计算的可能性。
Q18推荐引擎是什么?它如何工作?
回答者:Gregory Piatetsky
现在我们很熟悉Netflix——“你可能感兴趣的电影”或亚马逊——购买了X产品的客户还购买了Y的推荐。
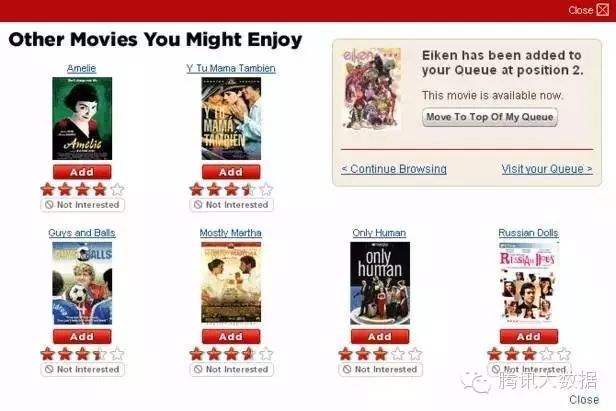
你可能感兴趣的电影
这样的系统被称为推荐引擎或广泛推荐系统。
他们通常以下两种方式之一产生推荐:使用协作或基于内容的过滤。
基于用户的协同过滤方法构建一个模型过去的行为(以前购买物品,电影观看和评级等)并使用当前和其他用户所做的决定。然后使用这个模型来预测(或评级)用户可能感兴趣的项目。
基于内容的过滤方法使用一个项目的特点推荐额外的具有类似属性的物品。这些方法往往结合混合推荐系统。
这是一个比较,当这两种方法用于两个流行音乐推荐系统——Last.fm 和 Pandora Radio。(以系统推荐条目为例)
Last.fm创建一个“站”推荐的歌曲通过观察乐队和个人定期跟踪用户听和比较这些听其他用户的行为。最后一次。fm会跟踪不出现在用户的图书馆,但通常是由其他有相似兴趣的用户。这种方法充分利用了用户的行为,它是一个协同过滤技术。
Pandora用一首歌的属性或艺术家(400年的一个子集属性提供的音乐基因工程)以设定具有类似属性的“站”,播放音乐。用户的反馈用来提炼的结果,排除用户“不喜欢”特定的歌曲的某些属性和强调用户“喜欢”的歌的其他属性。这是一个基于内容的方法。
这里有一些很好的介绍Introduction to Recommendation Engines by Dataconomy 和an overview of building a Collaborative Filtering Recommendation Engine by Toptal。关于推荐系统的最新研究,点击ACM RecSys会议。
Q19解释什么是假阳性和假阴性。为什么区分它们非常重要?
回答者:Gregory Piatetsky
在二进制分类(或医疗测试)中,假阳性是当一个算法(或测试)满足的条件,在现实中不满足。假阴性是当一个算法(或测试)表明不满足一个条件,但实际上它是存在的。
在统计中,假设检验出假阳性,也被称为第一类误差和假阴性- II型错误。
区分和治疗不同的假阳性和假阴性显然是非常重要的,因为这些错误的成本不一样。
例如,如果一个测试测出严重疾病是假阳性(测试说有疾病,但人是健康的),然后通过一个额外的测试将会确定正确的诊断。然而,如果测试结果是假阴性(测试说健康,但是人有疾病),然后患者可能会因此死去。
Q20你使用什么工具进行可视化?你对Tableau/R/SAS(用来作图)有何看法?如何有效地在一幅图表(或一个视频)中表示五个维度?
回答者:Gregory Piatetsky
有很多数据可视化的好工具。R,Python,Tableau和Excel数据科学家是最常用的。
这里是有用的KDnuggets资源:
可视化和数据挖掘软件
Python可视化工具的概述
21个基本数据可视化工具
前30名的社交网络分析和可视化工具
标签:数据可视化
有很多方法可以比二维图更好。第三维度可以显示一个三维散点图,可以旋转。您可以操控颜色、材质、形状、大小。动画可以有效地用于显示时间维度(随时间变化)。
这是一个很好的例子。
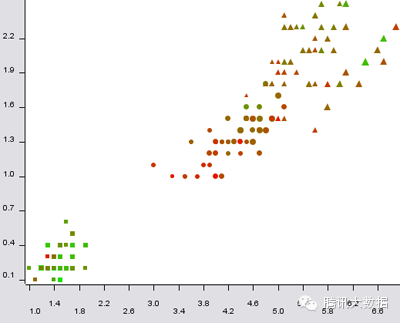
图20:五维虹膜数据的散点图,尺寸:花萼长度;颜色:萼片宽;形状:类;x-column:花瓣长度;y-column:花瓣宽度。
从5个以上的维度,一种方法是平行坐标,由Alfred Inselberg首先提出。
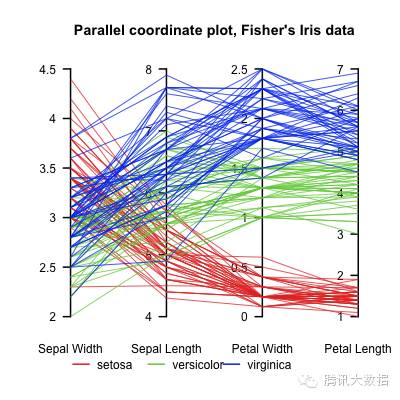
图20 b:平行坐标里的虹膜数据
另请参阅
Quora:高维数据可视化的最好方法是什么?
和
乔治·格林斯和他的同事们在High-Dimensional Visualizations 的开创性工作。
当然,当你有很多的维度的时候,最好是先减少维度或特征。
特别提问:解释什么是过拟合,你如何控制它
这个问题不是20问里面的,但是可能是最关键的一问来帮助你分辨真假数据科学家!
回答者:Gregory Piatetsky
过拟合是指(机器)学习到了因偶然造成并且不能被后续研究复制的的虚假结果。
我们经常看到报纸上的报道推翻之前的研究发现,像鸡蛋不再对你的健康有害,或饱和脂肪与心脏病无关。这个问题在我们看来是很多研究人员,特别是社会科学或医学领域的,经常犯下的数据挖掘的基本错误——过度拟合数据。
研究人员了测试太多假设而没有适当的统计控制,所以他们会碰巧发现一些有趣的事情和报告。不足为奇的是,下一次的效果,由于(至少一部分是)偶然原因,将不再明显或不存在。
这些研究实践缺陷被确定,由约翰·p·a·埃尼迪斯的在他的里程碑式的论文《为什么大多数发表的研究成果是错误的》(《公共科学图书馆·医学》杂志,2005年)中发表出来。埃尼迪斯发现,结果往往是被夸大的或不能被复制。在他的论文中,他提出了统计证据,事实上大多数声称的研究成果都是虚假的。
埃尼迪斯指出,为了使研究结果是可靠的,它应该有:
大型的样本和大量的结果
测试关系的数量更多,选择更少
在设计,定义,结果和分析模式几个方面有更大的灵活性
最小化偏差,依资金预算和其他因素考量(包括该科学领域的普及程度)
不幸的是,这些规则常常被违反,导致了很多不能再现的结果。例如,标准普尔500指数被发现与孟加拉国的黄油生产密切相关(从1981年至1993年)(这里是PDF)
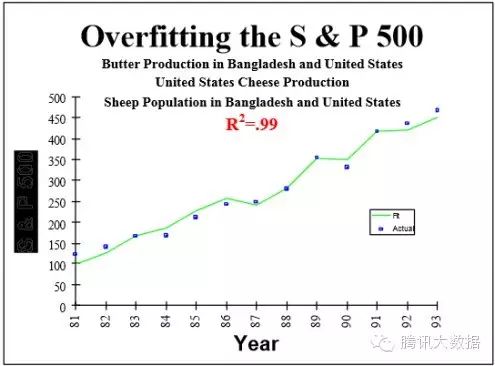
若想看到更多有趣的(包括完全虚假)的结果,您可以使用一些工具,如谷歌的correlate或Tyler Vigen的Spurious correlations。
可以使用几种方法来避免数据过拟合:
试着寻找最简单的假设
正规化(为复杂性添加一种处罚)
随机测试(使变量随机化,在这个数据上试试你的方法——如果它发现完全相同的结果,肯定有哪里出错了)
嵌套交叉验证(在某种程度上做特征选择,然后在交叉验证外层运行整个方法)
调整错误发现率
使用2015年提出的一个突破方法——可重复使用的保持法
好的数据科学是对世界理解的前沿科学,数据科学家的责任是避免过度拟合数据,并教育公众和媒体关于错误数据分析的危险性。

相关文章推荐
- 面试干货!21个必知数据科学面试题和答案part2(12-21)
- 面试干货!21个必知数据科学面试题和答案part1(1-11)
- 面试干货!21个必知数据科学面试题和答案part2(12-21)
- 【转载】面试干货!21个必知数据科学面试题和答案
- 面试干货!21个必知数据科学面试题和答案part1(1-11)
- 21个数据科学家面试必须知道的问题和答案
- net面试题大全(有答案) & asp.net面试集合
- 精选微软等公司数据结构+算法面试100题带答案(1-10)
- 面试-操作系统常见面试题(答案仅供参考)
- 大数据面试-05-大数据工程师面试题
- [面试经验] 阿里巴巴DBA面试题及一份答案
- 超全数据挖掘面试笔试题(附答案)
- 【数据分析面试题】一道 面试题,我的答案
- 干货 | 98道常见Hadoop面试题及答案解析(一)
- 【分享面试题二】Spring,hibernate,struts的面试笔试题(含答案)
- 腾讯大数据面试及参考答案[2017]
- Java核心技术及面试指南 2.3.6 String相关的面试题答案
- 关于机器学习、数据科学面试的准备
- 大数据面试-06-大数据工程师面试题
- 2016年个人面试面试题总结【答案】