Java机器学习库ML之十模型选择准则AIC和BIC
2017-06-27 16:23
267 查看
学习任务所建立的模型多数是参数估计并采用似然函数作为目标函数,当训练数据足够多时,可以不断提高模型精度,但是以提高模型复杂度为代价的,同时也带来一个机器学习中非常普遍的问题——过拟合。模型选择问题是在模型复杂度与模型对数据集描述能力(即似然函数)之间寻求最佳平衡。
对于过拟合问题,可加入模型复杂度的惩罚项来避免,这里通过ML库代码介绍两个模型选择方法:赤池信息准则(Akaike Information Criterion,AIC)和贝叶斯信息准则(Bayesian Information Criterion,BIC)。
1)AIC是衡量统计模型拟合优良性的一种标准,由日本统计学家赤池弘次在1974年提出,它建立在熵的概念上,提供了权衡估计模型复杂度和拟合数据优良性的标准。
通常情况下,AIC定义为:
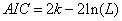
其中k是模型参数个数,L是似然函数。从一组可供选择的模型中选择最佳模型时,通常选择AIC最小的模型。
当两个模型之间存在较大差异时,差异主要体现在似然函数项,当似然函数差异不显著时,上式第一项,即模型复杂度则起作用,从而参数个数少的模型是较好的选择。
一般而言,当模型复杂度提高(k增大)时,似然函数L也会增大,从而使AIC变小,但是k过大时,似然函数增速减缓,导致AIC增大,模型过于复杂容易造成过拟合现象。目标是选取AIC最小的模型,AIC不仅要提高模型拟合度(极大似然),而且引入了惩罚项,使模型参数尽可能少,有助于降低过拟合的可能性。
2)BIC(Bayesian InformationCriterion)贝叶斯信息准则与AIC相似,用于模型选择,1978年由Schwarz提出。训练模型时,增加参数数量,也就是增加模型复杂度,会增大似然函数,但是也会导致过拟合现象,针对该问题,AIC和BIC均引入了与模型参数个数相关的惩罚项,BIC的惩罚项比AIC的大,考虑了样本数量,样本数量过多时,可有效防止模型精度过高造成的模型复杂度过高。
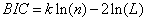
其中,k为模型参数个数,n为样本数量,L为似然函数。kln(n)惩罚项在维数过大且训练样本数据相对较少的情况下,可以有效避免出现维度灾难现象。
ML库对聚类方法进行模型选择的示例代码如下:
/**
* This file is part of the Java Machine Learning Library
*
* The Java Machine Learning Library is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation; either version 2 of the License, or
* (at your option) any later version.
*
* The Java Machine Learning Library is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with the Java Machine Learning Library; if not, write to the Free Software
* Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA
*
* Copyright (c) 2006-2012, Thomas Abeel
*
* Project: http://java-ml.sourceforge.net/ *
*/
package com.gddx;
import java.io.File;
import net.sf.javaml.clustering.Clusterer;
import net.sf.javaml.clustering.KMeans;
import net.sf.javaml.clustering.evaluation.AICScore;
import net.sf.javaml.clustering.evaluation.BICScore;
import net.sf.javaml.clustering.evaluation.ClusterEvaluation;
import net.sf.javaml.clustering.evaluation.SumOfSquaredErrors;
import net.sf.javaml.core.Dataset;
import net.sf.javaml.tools.data.FileHandler;
/**
* Shows how to use the different cluster evaluation measure that are
* implemented in Java-ML.
*
* @see net.sf.javaml.clustering.evaluation.*
*
* @author Thomas Abeel
*
*/
public class TutorialClusterEvaluation {
public static void main(String[] args) throws Exception {
/* Load a dataset */
Dataset data = FileHandler.loadDataset(new File("D:\\tmp\\javaml-0.1.7-src\\UCI-small\\iris\\iris.data"), 4, ",");
/*
* Create a new instance of the KMeans algorithm that will create 3
* clusters and create one that will make 4 clusters.
*/
Clusterer km3 = new KMeans(3);
Clusterer km4 = new KMeans(4);
/*
* Cluster the data, we will create 3 and 4 clusters.
*/
Dataset[] clusters3 = km3.cluster(data);
Dataset[] clusters4 = km4.cluster(data);
ClusterEvaluation aic = new AICScore();
ClusterEvaluation bic = new BICScore();
ClusterEvaluation sse = new SumOfSquaredErrors();
double aicScore3 = aic.score(clusters3);
double bicScore3 = bic.score(clusters3);
double sseScore3 = sse.score(clusters3);
double aicScore4 = aic.score(clusters4);
double bicScore4 = bic.score(clusters4);
double sseScore4 = sse.score(clusters4);
System.out.println("AIC score: " + aicScore3+"\t"+aicScore4);
System.out.println("BIC score: " + bicScore3+"\t"+bicScore4);
System.out.println("Sum of squared errors: " + sseScore3+"\t"+sseScore4);
}
}
对于过拟合问题,可加入模型复杂度的惩罚项来避免,这里通过ML库代码介绍两个模型选择方法:赤池信息准则(Akaike Information Criterion,AIC)和贝叶斯信息准则(Bayesian Information Criterion,BIC)。
1)AIC是衡量统计模型拟合优良性的一种标准,由日本统计学家赤池弘次在1974年提出,它建立在熵的概念上,提供了权衡估计模型复杂度和拟合数据优良性的标准。
通常情况下,AIC定义为:
其中k是模型参数个数,L是似然函数。从一组可供选择的模型中选择最佳模型时,通常选择AIC最小的模型。
当两个模型之间存在较大差异时,差异主要体现在似然函数项,当似然函数差异不显著时,上式第一项,即模型复杂度则起作用,从而参数个数少的模型是较好的选择。
一般而言,当模型复杂度提高(k增大)时,似然函数L也会增大,从而使AIC变小,但是k过大时,似然函数增速减缓,导致AIC增大,模型过于复杂容易造成过拟合现象。目标是选取AIC最小的模型,AIC不仅要提高模型拟合度(极大似然),而且引入了惩罚项,使模型参数尽可能少,有助于降低过拟合的可能性。
2)BIC(Bayesian InformationCriterion)贝叶斯信息准则与AIC相似,用于模型选择,1978年由Schwarz提出。训练模型时,增加参数数量,也就是增加模型复杂度,会增大似然函数,但是也会导致过拟合现象,针对该问题,AIC和BIC均引入了与模型参数个数相关的惩罚项,BIC的惩罚项比AIC的大,考虑了样本数量,样本数量过多时,可有效防止模型精度过高造成的模型复杂度过高。
其中,k为模型参数个数,n为样本数量,L为似然函数。kln(n)惩罚项在维数过大且训练样本数据相对较少的情况下,可以有效避免出现维度灾难现象。
ML库对聚类方法进行模型选择的示例代码如下:
/**
* This file is part of the Java Machine Learning Library
*
* The Java Machine Learning Library is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation; either version 2 of the License, or
* (at your option) any later version.
*
* The Java Machine Learning Library is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with the Java Machine Learning Library; if not, write to the Free Software
* Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA
*
* Copyright (c) 2006-2012, Thomas Abeel
*
* Project: http://java-ml.sourceforge.net/ *
*/
package com.gddx;
import java.io.File;
import net.sf.javaml.clustering.Clusterer;
import net.sf.javaml.clustering.KMeans;
import net.sf.javaml.clustering.evaluation.AICScore;
import net.sf.javaml.clustering.evaluation.BICScore;
import net.sf.javaml.clustering.evaluation.ClusterEvaluation;
import net.sf.javaml.clustering.evaluation.SumOfSquaredErrors;
import net.sf.javaml.core.Dataset;
import net.sf.javaml.tools.data.FileHandler;
/**
* Shows how to use the different cluster evaluation measure that are
* implemented in Java-ML.
*
* @see net.sf.javaml.clustering.evaluation.*
*
* @author Thomas Abeel
*
*/
public class TutorialClusterEvaluation {
public static void main(String[] args) throws Exception {
/* Load a dataset */
Dataset data = FileHandler.loadDataset(new File("D:\\tmp\\javaml-0.1.7-src\\UCI-small\\iris\\iris.data"), 4, ",");
/*
* Create a new instance of the KMeans algorithm that will create 3
* clusters and create one that will make 4 clusters.
*/
Clusterer km3 = new KMeans(3);
Clusterer km4 = new KMeans(4);
/*
* Cluster the data, we will create 3 and 4 clusters.
*/
Dataset[] clusters3 = km3.cluster(data);
Dataset[] clusters4 = km4.cluster(data);
ClusterEvaluation aic = new AICScore();
ClusterEvaluation bic = new BICScore();
ClusterEvaluation sse = new SumOfSquaredErrors();
double aicScore3 = aic.score(clusters3);
double bicScore3 = bic.score(clusters3);
double sseScore3 = sse.score(clusters3);
double aicScore4 = aic.score(clusters4);
double bicScore4 = bic.score(clusters4);
double sseScore4 = sse.score(clusters4);
System.out.println("AIC score: " + aicScore3+"\t"+aicScore4);
System.out.println("BIC score: " + bicScore3+"\t"+bicScore4);
System.out.println("Sum of squared errors: " + sseScore3+"\t"+sseScore4);
}
}

相关文章推荐
- 模型选择的几种方法:AIC,BIC,HQ准则
- 模型选择准则之AIC和BIC
- 模型选择准则之AIC和BIC
- 模型选择之AIC与BIC
- [原]模型选择之AIC与BIC
- 模型选择准则
- sklearn GMM BIC 模型选择
- R语言-评分卡模型验证(ROC,KS,AIC,BIC)
- AIC,BIC信息准则
- 安装AIC准则使用前进法后退法和逐步回归法进行变量选择的r语言代码
- 以调整复决定系数和AIC为模型选择标准,建立前进法、后退法、逐步回归法的r语言代码
- Windows操作系统I/O模型—笔记3(事件选择(WSAEventSelect)模型)
- Linux网络编程服务器模型选择之IO复用循环并发服务器
- unity pc端 采用右键选择相机,中键盘移动缩放模型
- 公开课机器学习笔记(17)学习理论二 VC维、ERM总结、模型选择、特征选择
- 模型选择之交叉验证
- 机器学习之模型评估与模型选择(学习笔记)
- 利用数学模型帮助选择中意的电脑型号
- 在实际项目中,如何选择合适的机器学习模型?
- 机器学习(九) - - 模型评估和选择④比较检验