Python爬虫-爬取猫眼电影Top100榜单
2017-06-23 07:44
716 查看
猫眼电影的网站html组成十分简单。
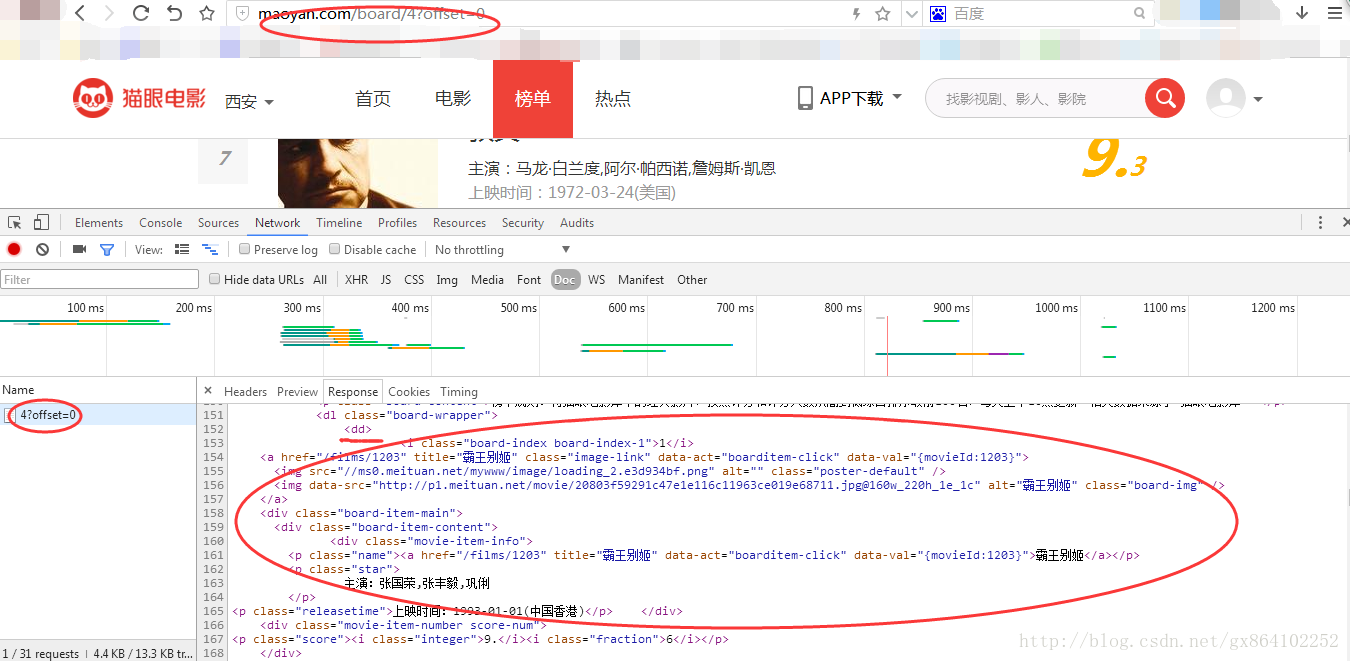
地址就是很简单的offset=x 这个x参数更改即可翻页。
下面的信息使用正则表达式很快就可以得出结果。
直接放代码:
单页的url信息获取之后,更改为多进程方式获取全部!
测试单进程2.3s,多进程只需要1s。
地址就是很简单的offset=x 这个x参数更改即可翻页。
下面的信息使用正则表达式很快就可以得出结果。
直接放代码:
import json
import re
import requests
from requests.exceptions import RequestException
#获取一个url下的html文件
def get_one_page(url):
try:
res = requests.get(url)
if res.status_code == 200:
print('请求成功')
return res.text
print('请求失败')
return None
except RequestException:
return None
#解析html文件 其中使用了正则匹配
def parse_one_page(html):
#如果不加re.S(任意匹配) .就不会匹配换行符!
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)" alt="(.*?)" class="board-img" />.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
for item in items: #构造一个生成器可以使用 for遍历
#生成一个字典
yield{
'index' : item[0],
'image': item[1],
'title': item[2],
#strip()去除空格和\n 切片去除 主演:
'actor': item[3].strip()[3:],
'time' : item[4].strip()[5:],
'score' : item[5]+item[6]
}
#写入文件 使用json加载字典
def write_to_file(content):
#加上encoding='utf-8' 和 ensure_ascii=False显示汉字
with open('result.txt', 'a', encoding='utf-8') as f:
#字典转换成 字符串
f.write(json.dumps(content, ensure_ascii=False) + '\n')
f.close()
#主函数运行
def main():
html = get_one_page('http://maoyan.com/board/4?')
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
main()单页的url信息获取之后,更改为多进程方式获取全部!
def main(offset):
url = 'http://maoyan.com/board/4?offset={}'.format(offset)
html = get_one_page(url)
# total = []
for item in parse_one_page(html):
print(item)
# total.extend(item)
write_to_file(item)
# save_to_pandas(total)
if __name__ == '__main__':
import time
time1 = time.time()
pool = Pool()
pool.map(main, [i*10 for i in range(10)])
# for i in range(10): 单进程
# main(i*10)
time2 = time.time()
print(time2-time1)测试单进程2.3s,多进程只需要1s。

相关文章推荐
- python 爬虫抓取猫眼电影 top100 源码
- python爬虫实战:抓取猫眼电影TOP100存放到MongoDB中
- Python爬虫之三:抓取猫眼电影TOP100
- Python学习记录-爬取猫眼电影top100榜单
- python爬虫爬取猫眼电影top100
- 【爬虫】爬取猫眼电影top100
- 利用requests和正则爬取猫眼电影top100榜单
- 爬取猫眼电影榜单Top100
- 【Python简单爬虫设计】对豆瓣TOP100的电影名及简要的爬取
- Python爬虫,用于抓取豆瓣电影Top前100的电影的名称
- 一个简单的python爬虫程序 爬取豆瓣热度Top100以内的电影信息
- Python爬取猫眼电影TOP100
- python正则表达式爬取猫眼电影top100
- [原创] Python3.6+request+beautiful 半次元Top100 爬虫实战,将小姐姐的cos美图获得
- python3 爬取猫眼榜单top100(requests+beautifulsoup)
- python 爬虫项目-爬取猫眼top100电影
- 今天写的一个用爬虫爬猫眼电影top100的完整代码
- Python实战---抓取猫眼电影TOP100
- python抓取猫眼电影top100
- python正则表达式简单爬虫入门+案例(爬取猫眼电影TOP榜)