[Python爬虫] 之二十三:Selenium +phantomjs 利用 pyquery抓取智能电视网数据
2017-06-22 11:20
881 查看
一、介绍
本例子用Selenium +phantomjs爬取智能电视网(http://news.znds.com/article/news/)的资讯信息,输入给定关键字抓取资讯信息。给定关键字:数字;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
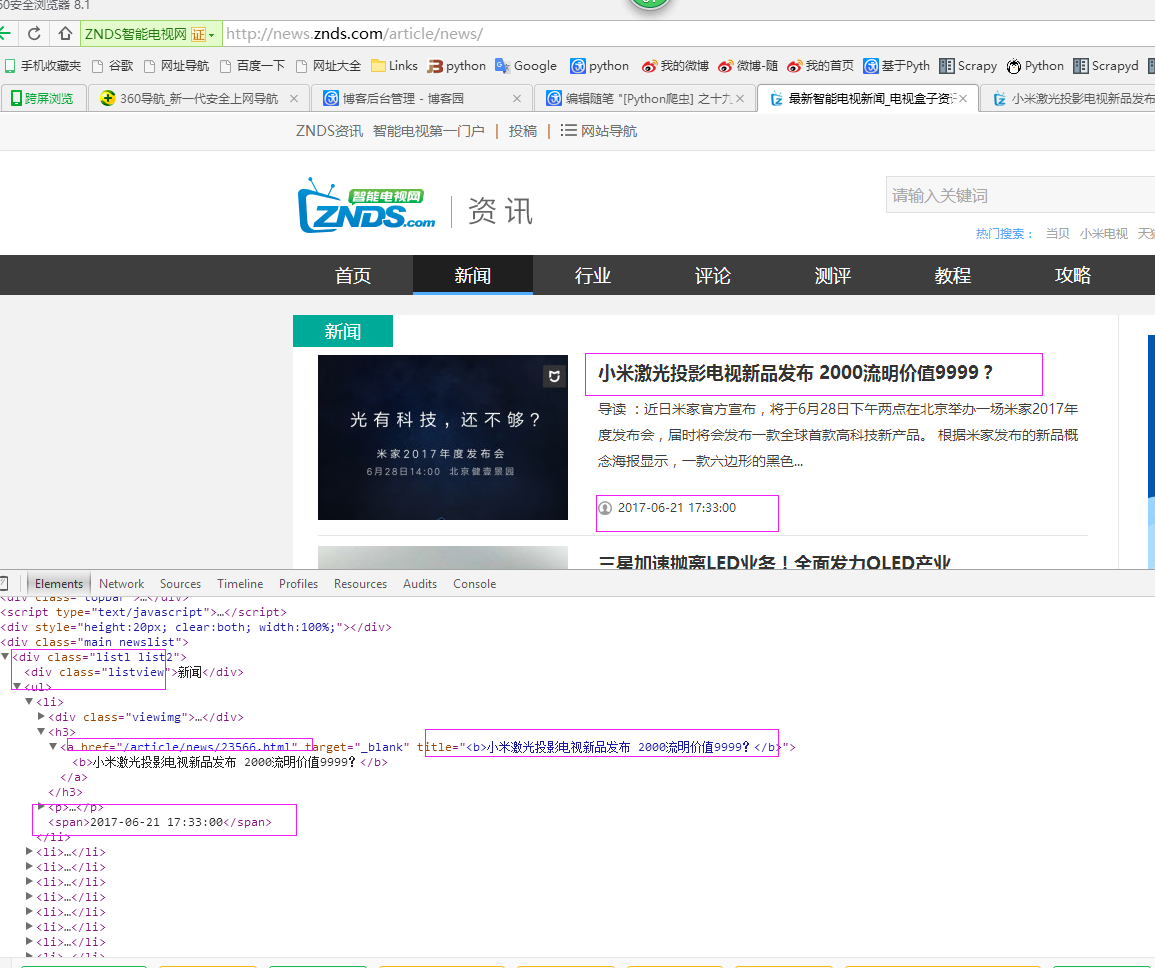
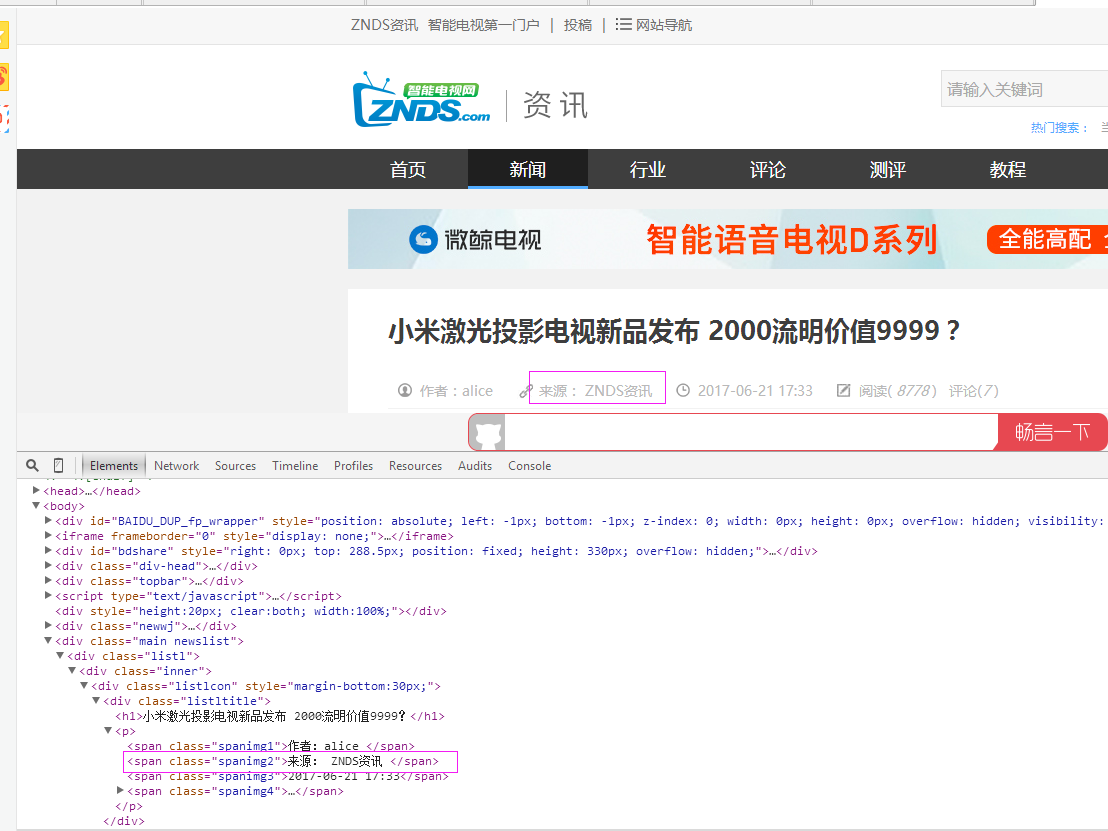
三、数据抓取
针对上面的网站信息,来进行抓取1、首先抓取信息列表
抓取代码:Elements = doc('div[class="listl list2"]').find('ul').find('li')
2、抓取标题
抓取代码:title = element('h3').find('a').attr('title').encode('utf8')
3、抓取链接
抓取代码:url = 'http://news.znds.com' + element('h3').find('a').attr('href')
4、抓取日期
抓取代码:date = element('span').text().encode('utf8')
5、抓取来源
抓取代码:strSource = dochtml('span[class="spanimg2"]').text().encode('utf8').strip()
四、完整代码
# coding=utf-8
import os
import re
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
import time
import datetime
from pyquery import PyQuery as pq
import LogFile
import mongoDB
class zndsSpider(object):
def __init__(self,driver,log,keyword_list,websearch_url,valid,filter):
'''
:param driver: 驱动
:param log: 日志
:param keyword_list: 关键字列表
:param websearch_url: 搜索网址
:param valid: 采集参数 0:采集当天;1:采集昨天
:param filter: 过滤项,下面这些内容如果出现在资讯标题中,那么这些内容不要,过滤掉
'''
self.log = log
self.driver = driver
self.webSearchUrl_list = websearch_url.split(';')
self.keyword_list = keyword_list
self.db = mongoDB.mongoDbBase()
self.valid = valid
self.range =3+valid * 2
self.start_urls = []
# 过滤项
self.filter = filter
for url in self.webSearchUrl_list:
self.start_urls.append(url)
def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result
def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: '2017-06-20 10:22 '
:return: True:合法;False:不合法
'''
currentDate = time.strftime('%Y-%m-%d')
datePattern = re.compile(r'\d{4}-\d{1,2}-\d{1,2}')
strDate = re.findall(datePattern, strDateText)
if len(strDate) == 1:
if self.valid == 0 and self.Comapre_to_days(currentDate, strDate[0]) == 0:
return True, currentDate
elif self.valid == 1 and self.Comapre_to_days(currentDate, strDate[0]) == 1:
return True, str(datetime.datetime.now() - datetime.timedelta(days=1))[0:10]
elif self.valid == 2 and self.Comapre_to_days(currentDate, strDate[0]) == 2:
return True, str(datetime.datetime.now() - datetime.timedelta(days=2))[0:10]
return False, ''
def log_print(self, msg):
'''
# 日志函数
# :param msg: 日志信息
# :return:
# '''
print '%s: %s' % (time.strftime('%Y-%m-%d %H-%M-%S'), msg)
def scrapy_date(self):
try:
strsplit = '------------------------------------------------------------------------------------'
for link in self.start_urls:
try:
self.driver.get(link)
except TimeoutException:
self.log.WriteLog('time out after %d seconds when loading page' % 10)
self.driver.execute_script('window.stop()')
continue
move_element = self.driver.find_element_by_xpath("//div[@class='button-footer']/span")
for i in xrange(self.range):
move_element.click()
time.sleep(0.2)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
infoList = []
self.log.WriteLog(strsplit)
self.log_print(strsplit)
Elements = doc('div[class="hotbox "]')
for element in Elements.items():
date = element('span').text().encode('utf8')
flag, strDate = self.date_isValid(date)
if flag:
title = element('h3').find('a').text().encode('utf8')
if title.find(self.filter)>-1:
continue
for keyword in self.keyword_list:
if title.find(keyword) > -1:
url = 'http://news.znds.com' + element('h3').find('a').attr('href')
dictM = {'title': title, 'date': strDate,
'url': url, 'keyword': keyword, 'introduction': title, 'source': ''}
infoList.append(dictM)
break
if len(infoList) > 0:
for item in infoList:
item['sourceType'] = 1
url = item['url']
try:
self.driver.get(url)
except TimeoutException:
self.log.WriteLog('time out after %d seconds when loading page' % 10)
self.driver.execute_script('window.stop()')
continue
htext = self.driver.execute_script("return document.documentElement.outerHTML")
dochtml = pq(htext)
strSource = dochtml('span[class="spanimg2"]').text().encode('utf8').strip()
item['source'] = strSource
self.log.WriteLog('title:%s' % item['title'])
self.log.WriteLog('url:%s' % item['url'])
self.log.WriteLog('date:%s' % item['date'])
self.log.WriteLog('source:%s' % item['source'])
self.log.WriteLog('kword:%s' % item['keyword'])
self.log.WriteLog(strsplit)
self.log_print('title:%s' % item['title'])
self.log_print('url:%s' % item['url'])
self.log_print('date:%s' % item['date'])
self.log_print('source:%s' % item['source'])
self.log_print('kword:%s' % item['keyword'])
self.log_print(strsplit)
self.db.SaveInformations(infoList)
except Exception, e:
self.log.WriteLog('zndsSpider:' + e.message)
finally:
pass
# obj = zndsSpider()
# obj.scrapy_date()

相关文章推荐
- [Python爬虫] 之十七:Selenium +phantomjs 利用 pyquery抓取梅花网数据
- [Python爬虫] 之二十一:Selenium +phantomjs 利用 pyquery抓取36氪网站数据
- [Python爬虫] 之十八:Selenium +phantomjs 利用 pyquery抓取电视之家网数据
- [Python爬虫] 之十六:Selenium +phantomjs 利用 pyquery抓取一点咨询数据
- [Python爬虫] 之二十二:Selenium +phantomjs 利用 pyquery抓取界面网站数据
- [Python爬虫] 之二十四:Selenium +phantomjs 利用 pyquery抓取中广互联网数据
- [Python爬虫] 之十九:Selenium +phantomjs 利用 pyquery抓取超级TV网数据
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
- [Python爬虫] 之二十六:Selenium +phantomjs 利用 pyquery抓取智能电视网站图片信息
- [Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频
- [Python爬虫] 之二十:Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据
- 直播网站LiveTV Mining,爬虫抓取数据 python3+selenium+phantomjs
- [Python爬虫] 之十四:Selenium +phantomjs抓取媒介360数据
- selenium配合phantomjs实现爬虫功能,并把抓取的数据写入excel
- Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
- Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
- python+selenium+PhantomJS抓取ajax动态网页数据
- Python3 ubuntu16.04 phantomjs 与 selenium 抓取数据
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
- Python selenium爬虫抓取船舶网站数据(动态页面)