lec5 训练神经网络1
2017-06-18 10:56
169 查看
训练网络之前必须知道,训练卷积网络需要一定的数据量。
(可以将卷积层作为提取特征的固定网络,我们只需重新训练分类层就可以了,当然如果有一定的数据量可以训练较多的层)
如下图所示:

准备好数据集,网络模型之后可以开始训练网络。下降策略一般采用SGD(随机梯度下降)
训练步骤:

激活函数:
可以看下面博客的内容
http://blog.csdn.net/fffupeng/article/details/73251059
但是中心化是常常会做的,在alexnet中计算每个像素点的平均值([32,32,3]的数组),然后减去。在vggnet中计算每个通道的平均值(3个数字)。
权重初始化:
可以看下面博客的内容
http://blog.csdn.net/fffupeng/article/details/73251059
论文:understanding the difficulty of training deep feedfroward neuarl networks
总之一句话来说,就是最好保证输入输出同分布。这也是xavier初始化的思想。
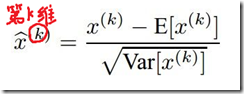

注意BN在训练和测试时的差别:
训练时计算的是每个batch的方差和标准差,在测试时计算的是整个训练集的均值和标准差。
最后的训练细节可以参考:
http://blog.csdn.net/fffupeng/article/details/73251059
finetuning
采用预训练的方式,然后用自己的数据训练网络的最后几层。(可以将卷积层作为提取特征的固定网络,我们只需重新训练分类层就可以了,当然如果有一定的数据量可以训练较多的层)
如下图所示:
准备好数据集,网络模型之后可以开始训练网络。下降策略一般采用SGD(随机梯度下降)
训练步骤:
激活函数:
可以看下面博客的内容
http://blog.csdn.net/fffupeng/article/details/73251059
数据预处理:
1、机器学习中pca和白化都是常见的预处理方式。但是在图像处理中很少用到,因为协方差矩阵过大。但是在数据集扩充中可以使用pca进行图片颜色的增强(alexnet)。但是中心化是常常会做的,在alexnet中计算每个像素点的平均值([32,32,3]的数组),然后减去。在vggnet中计算每个通道的平均值(3个数字)。
权重初始化:
可以看下面博客的内容
http://blog.csdn.net/fffupeng/article/details/73251059
论文:understanding the difficulty of training deep feedfroward neuarl networks
总之一句话来说,就是最好保证输入输出同分布。这也是xavier初始化的思想。
Batch Normalization:
希望每个神经元的输出服从高斯分布,方差不为0.注意BN在训练和测试时的差别:
训练时计算的是每个batch的方差和标准差,在测试时计算的是整个训练集的均值和标准差。
最后的训练细节可以参考:
http://blog.csdn.net/fffupeng/article/details/73251059

相关文章推荐
- 使用反向传播算法(back propagation)训练多层神经网络
- 斯坦福cs231n学习笔记(7)------神经网络训练细节(激活函数)
- caffe下用神经网络 训练自己的模型
- 利用反向传播训练多层神经网络的原理
- 为什么深层神经网络难以训练
- 从零开始教你训练神经网络(附公式&学习资源)
- TensorFlow 入门之第一个神经网络训练 MNIST
- 马里兰大学帕克分校提出对「损失函数」进行「可视化」,以提高神经网络的训练能力
- pybrain学习教程(三):训练神经网络
- 循环神经网络的训练(1)
- Halcon实战之基于MLP多层神经网络的训练学习
- 斯坦福cs231n学习笔记(8)------神经网络训练细节(数据预处理、权重初始化)
- 新版Matlab中神经网络训练函数Newff的使用方法
- tensorflow的基本用法(七)——使用MNIST训练神经网络
- 神经网络训练中的Tricks之高效BP(反向传播算法)
- 斯坦福coursera作业题神经网络训练数字识别Feedforward Propagation and Prediction
- 关于应用gpu训练神经网络的注意事项
- GUI:GUI的方式创建/训练/仿真/预测神经网络—Jason niu
- 【神经网络与深度学习】Caffe Model Zoo许多训练好的caffemodel
- 为什么在训练神经网络时候比较适合使用交叉熵错误率,而不是分类错误率或是均方差