Mybatis源码解析 —— Sql解析详解
2017-06-04 12:55
513 查看
引言
Sql解析架构
从注解xml 定义到MappedStatement
从MappedStatement到可执行的Sql
结语
Mybatis框架极大地简化了ORM,让使用者自定义sql语句,再将查询结果映射到Java类中,其中很关键的一部分就是,将用户写的sql语句(以xml或者注解形式)解析成数据库可执行的sql语句。
本文将会介绍这整个的解析过程。
Sql解析其实分成了两部分,第一部分是将注解/xml中定义的sql语句转化成内存中的MappedStatement,也就是将script部分转化成内存中的MappedStatement,这部分发生在Mybatis初始化的时候,第二部分则是根据MappedStatement以及传入的参数,生成可以直接执行的sql语句,这部分发生在mapper函数被调用的时候。
可以说,MappedStatement里面包含了Mybatis有关Sql执行的所有特性,在这里我们能够找到Mybatis在Sql执行层面支持哪些特性,比如说可以支持定制化的数据库列到Java属性的映射,定制化的主键生成器。
对MappedStatement有一定的了解之后,我们就可以接着看整个的处理流程了。
处理流程如下图所示:
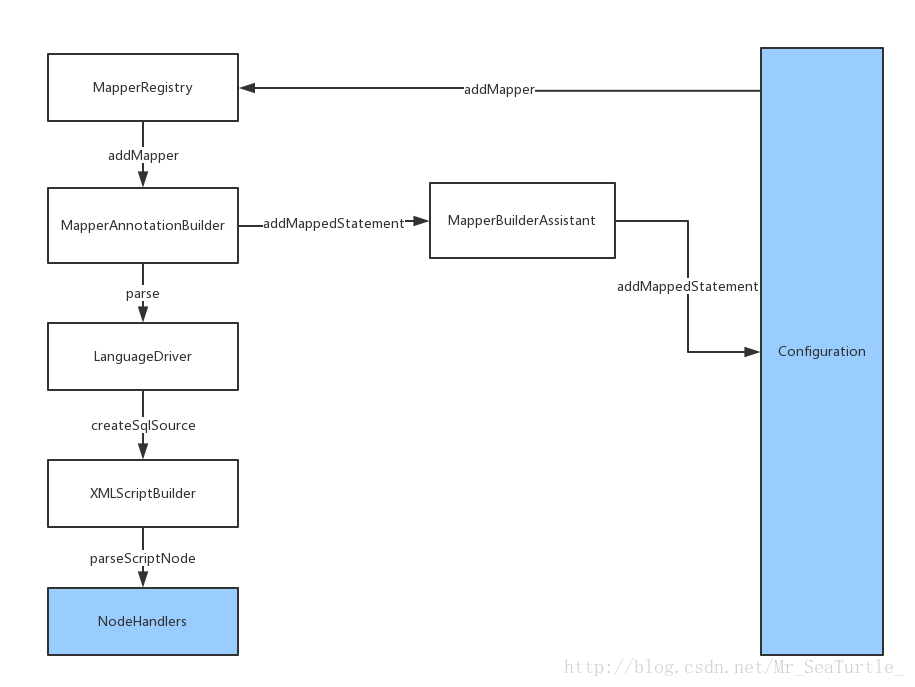
在这里,我们能够看到清晰的分层结构,从Configuration到具体的NodeHandlers,其实解析的任务一层层分解下来了。另外,最后解析生成的MappedStatement也会注册到Configuration中,保证了Configuration持有对所有MappedStatement的引用。
接下来,我们看一些具体的处理逻辑,也是比较有意思的部分。
在
而最后生成的SqlSource也分成了两个种,分别为RawSqlSource以及DynamicSqlSource。这样做的好处是,RawSqlSource可以在参数替换完成后直接执行,更加简单高效。
接下来再来看看解析具体Node的方法,
所以,由上可知,最后我们写在Sql定义中的
以上,就是从我们的定义,到MappedStatement的整个过程,在这个过程里面,结构化的XML语言被转化成了具体内存里面的一个个SqlNode,而像
接下来,我们将会使用MappedStatement,进行可执行的Sql生成。
Mybatis中Sql的执行是由
而在
在这里,我们能够看到之前由XMLNode转化而成的SqlNode起作用了,通过其中的Apply方法,会根据参数的长度来添加动态的
而返回的StaticSqlSource将会交由Executor进行包含参数设定,执行结构映射成Java实例在内的一系列操作,这个将会在后续的文章中继续解析。
这里面,我们能看到Mybatis框架的几个优点:
将Sql语句的动态部分与静态部分分隔开来
在启动时就提前解析XML文件/注解为MappedStatement,提高了效率(不需要执行一次解析一次)
通过标签使得Mybatis的动态Sql具有更加强大的扩展性,也体现了开闭原则。
通过这篇文章,我们能够学习一个Sql生成器的构建思路。也能够更加全面的了解到Mybatis Sql解析所支持的功能。
Sql解析架构
从注解xml 定义到MappedStatement
从MappedStatement到可执行的Sql
结语
引言
在Java Server理解与实践 ——Spring集成Mybatis中,笔者简要地介绍了Mybatis框架。Mybatis框架极大地简化了ORM,让使用者自定义sql语句,再将查询结果映射到Java类中,其中很关键的一部分就是,将用户写的sql语句(以xml或者注解形式)解析成数据库可执行的sql语句。
本文将会介绍这整个的解析过程。
Sql解析架构
本文将以一下的注解定义为例,剖析整个解析过程。@Select({"<script>",
"SELECT account",
"FROM user",
"WHERE id IN",
"<foreach item='item' index='index' collection='list'",
"open='(' separator=',' close=')'>",
"#{item}",
"</foreach>",
"</script>"})
List<String> selectAccountsByIds(@Param("list") int[] ids);Sql解析其实分成了两部分,第一部分是将注解/xml中定义的sql语句转化成内存中的MappedStatement,也就是将script部分转化成内存中的MappedStatement,这部分发生在Mybatis初始化的时候,第二部分则是根据MappedStatement以及传入的参数,生成可以直接执行的sql语句,这部分发生在mapper函数被调用的时候。
从注解/xml 定义到MappedStatement
首先,我们要明白什么是MappedStatement,先来看看MappedStatment的类定义。public final class MappedStatement {
private String resource; //来源,一般为文件名或者是注解的类名
private Configuration configuration; //Mybatis的全局唯一Configuration
private String id; //标志符,可以用于缓存
private Integer fetchSize; //每次需要查询的行数(可选)
private Integer timeout;//超时时间
private StatementType statementType;//语句类型,决定最后将使用Statement, PreparedStatement还是CallableStatement进行查询
private ResultSetType resultSetType;//结果集的读取类型,与java.sql.ResultSet中的类型对应。
private SqlSource sqlSource;//Mybatis中的sqlSource,保存了初次解析的结果
private Cache cache;//缓存空间
private ParameterMap parameterMap;//保存了方法参数与sql语句中的参数对应关系
private List<ResultMap> resultMaps;//可选,定义结果集与Java类型中的字段映射关系
private boolean flushCacheRequired;//是否立即写入
private boolean useCache;//是否使用缓存
private boolean resultOrdered;//可选,默认为false
private SqlCommandType sqlCommandType;//Sql执行类型(增、删、改、查)
private KeyGenerator keyGenerator;//可选,键生成器
private String[] keyProperties;//可选,作为键的属性
c059
private String[] keyColumns;//可选,键的列
private boolean hasNestedResultMaps;//是否有嵌套的映射关系
private String databaseId;//数据库的id
private Log statementLog;//logger
private LanguageDriver lang;//解析器
private String[] resultSets;//可选,数据集的名称
}可以说,MappedStatement里面包含了Mybatis有关Sql执行的所有特性,在这里我们能够找到Mybatis在Sql执行层面支持哪些特性,比如说可以支持定制化的数据库列到Java属性的映射,定制化的主键生成器。
对MappedStatement有一定的了解之后,我们就可以接着看整个的处理流程了。
处理流程如下图所示:
在这里,我们能够看到清晰的分层结构,从Configuration到具体的NodeHandlers,其实解析的任务一层层分解下来了。另外,最后解析生成的MappedStatement也会注册到Configuration中,保证了Configuration持有对所有MappedStatement的引用。
接下来,我们看一些具体的处理逻辑,也是比较有意思的部分。
XMLLanguageDriver
@Override
public SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType) {
// issue #3
if (script.startsWith("<script>")) {
XPathParser parser = new XPathParser(script, false, configuration.getVariables(), new XMLMapperEntityResolver());
return createSqlSource(configuration, parser.evalNode("/script"), parameterType);
} else {
// issue #127
script = PropertyParser.parse(script, configuration.getVariables());
TextSqlNode textSqlNode = new TextSqlNode(script);
if (textSqlNode.isDynamic()) {
return new DynamicSqlSource(configuration, textSqlNode);
} else {
return new RawSqlSource(configuration, script, parameterType);
}
}
}在
XMLLanguageDriver中,真正发生了解析我们定义在XML/注解中的语句,这里的解析分成了两部分,第一部分,初始化一个Parser,第二部分,对Parser解析出来的节点再进行下一步解析。
而最后生成的SqlSource也分成了两个种,分别为RawSqlSource以及DynamicSqlSource。这样做的好处是,RawSqlSource可以在参数替换完成后直接执行,更加简单高效。
接下来再来看看解析具体Node的方法,
XMLScriptBuilder
List<SqlNode> parseDynamicTags(XNode node) {
List<SqlNode> contents = new ArrayList<SqlNode>();
NodeList children = node.getNode().getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
XNode child = node.newXNode(children.item(i));
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
String data = child.getStringBody("");
TextSqlNode textSqlNode = new TextSqlNode(data);
if (textSqlNode.isDynamic()) {
contents.add(textSqlNode);
isDynamic = true;
} else {
contents.add(new StaticTextSqlNode(data));
}
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
String nodeName = child.getNode().getNodeName();
//使用具体的Handler进行处理
NodeHandler handler = nodeHandlers(nodeName);
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
handler.handleNode(child, contents);
isDynamic = true;
}
}
return contents;
}所以,由上可知,最后我们写在Sql定义中的
</foreach>这样的元素,会由实际的handler(
ForEachHandler)来进行处理,并且最后也会生成特定的SqlNode用于动态Sql的生成。这样就确保了Mybatis对于元素可扩展性的支持,同时保证了Sql的动态化。
以上,就是从我们的定义,到MappedStatement的整个过程,在这个过程里面,结构化的XML语言被转化成了具体内存里面的一个个SqlNode,而像
ResultMap这样的注解,则被转化成了MappedStatement里面其它的具体属性。
接下来,我们将会使用MappedStatement,进行可执行的Sql生成。
从MappedStatement到可执行的Sql
从MappedStatement到可执行的Sql部分相对来说就比较简单了,里面只涉及到从RawSqlSource/DynamicSqlSource到StaticSqlSource的转换。Mybatis中Sql的执行是由
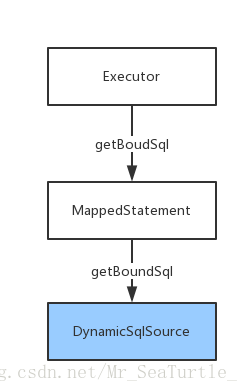
Executor进行的,而在执行之前,获取了MappedStatement之后,
Executor会调用MappedStatement的
getBoundSql方法,具体流程图如下:
而在
DynamicSqlSource中具体代码如下:
@Override
public BoundSql getBoundSql(Object parameterObject) {
DynamicContext context = new DynamicContext(configuration, parameterObject);
//首先,通过node的apply方法,动态生成占位符,以及相应的参数映射关系
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
//然后,再使用SqlSourceBuilder转化成staticSqlSource,这里也会对参数映射关系进行解析
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
//这里的bouldSql中的sql就已经是可执行的sql了
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
for (Map.Entry<String, Object> entry : context.getBindings().entrySet()) {
boundSql.setAdditionalParameter(entry.getKey(), entry.getValue());
}
return boundSql;
}在这里,我们能够看到之前由XMLNode转化而成的SqlNode起作用了,通过其中的Apply方法,会根据参数的长度来添加动态的
?占位符。
而返回的StaticSqlSource将会交由Executor进行包含参数设定,执行结构映射成Java实例在内的一系列操作,这个将会在后续的文章中继续解析。
结语
本文主要介绍了Mybatis中的Sql解析过程,包含两部分,第一部分是从XML标签/注解到内存中的MappedStatement,第二部分则是从MappedStatement到StaticSqlSource。这里面,我们能看到Mybatis框架的几个优点:
将Sql语句的动态部分与静态部分分隔开来
在启动时就提前解析XML文件/注解为MappedStatement,提高了效率(不需要执行一次解析一次)
通过标签使得Mybatis的动态Sql具有更加强大的扩展性,也体现了开闭原则。
通过这篇文章,我们能够学习一个Sql生成器的构建思路。也能够更加全面的了解到Mybatis Sql解析所支持的功能。

相关文章推荐
- Mybatis3源码分析(11)-Sql解析执行-BoundSql的加载-1
- Mybatis3源码分析(16)-Sql解析执行-结果集映射(ResultSetHandler)
- MyBatis-3.4.2-源码分析16:XML解析之SqlSessionFactory|SqlSession
- Mybatis SqlSessionTemplate 源码解析
- 通过源码分析MyBatis的缓存/Mybatis解析动态sql原理分析
- Mybatis3源码分析(12)-Sql解析执行-MetaObject
- mybatis源码解析(二)生成SqlSessionFactory
- MyBatis-3.4.2-源码分析14:XML解析之sqlElement(context.evalNodes("/mapper/sql"))
- Spring mybatis源码篇章-XMLLanguageDriver解析sql包装为SqlSource
- Mybatis源码解析之初始化配置文件封装为Configuration源码详解
- Mybatis3源码分析(14)-Sql解析执行-StatementHandler
- Mybatis实现【4】-查询解析(一次SQL查询的源码分析)
- Mybatis SqlSessionTemplate 源码解析
- Mybatis-Spring SqlSessionTemplate 源码解析
- MyBatis-3.4.2-源码分析18:XML解析之RoleMapper userMapper = sqlSession.getMapper(RoleMapper.class)
- Mybatis3源码分析(15)-Sql解析执行-Statement初始化和参数设置
- (四)MyBatis源码解析之SqlSession
- 47:Spark中的新解析引擎Catalyst源码SqlParser彻底详解
- Mybatis SqlSessionTemplate 源码解析
- Spark源码系列(九)Spark SQL初体验之解析过程详解