java多线程(十) 之 构建高效且可伸缩的结果缓存
2017-05-28 14:54
543 查看
几乎所有的服务器应用程序都会使用某种形式的缓存,重用之前的计算结果能降低延迟,提高吞吐量,但却需要消耗更多的内存.
本节,我们将开发一个高效且可伸缩的缓存,用于改进一个高计算开销的函数.
我们首先从简单的HashMap开始,然后分析它的并发性缺陷,并讨论如何修复它们.
这种方法虽然保证了线程的安全性,却带来了一个明显的可伸缩性问题: 每次只有一个线程能够执行compute.
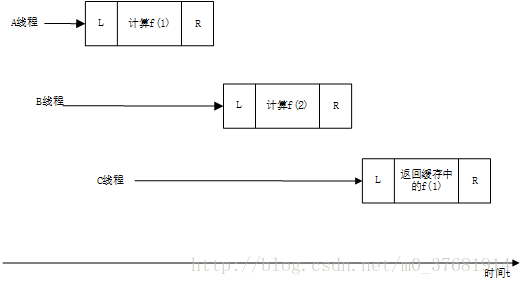
从上图可以看出,当A线程计算出f(1)时,C线程还不能直接得到f(1),需要等待B线程,假如很多线程进行compute方法的调用,可能导致后面的线程严重阻塞.
但是Memoizer2仍然存在一些不足,当两个线程调用compute时,可能会导致重复计算.
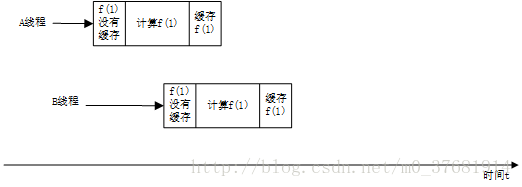
Memoizer2的主要问题在于,如果f(n)中间的计算开销很大的话,而其他线程并不知道这个计算正在进行,那么很可能会重复这个计算.
Memoizer3的实现几乎是完美的,它表现了非常好的并发性,若结果已经计算出来了,那么将立即返回.
如果其他线程正在计算该结果,那么新到的线程将一直等待这个结果被计算出来.
它只有一个缺陷,即仍然存在两个线程计算出相同的值的漏洞,这个漏洞的发生概率要远小于Memoizer2.
这个缺陷原因在于,if中的代码块,仍然是非原子的.
仍然存在的问题:
由于缓存的是Future而不是值,将导致缓存污染.
例如: 当某个future计算失败的时候,Map中依然存储着该future,没有被移除.
最终版本:
本节,我们将开发一个高效且可伸缩的缓存,用于改进一个高计算开销的函数.
我们首先从简单的HashMap开始,然后分析它的并发性缺陷,并讨论如何修复它们.
public interface Computable<A, V> {
V compute(A arg) throws InterruptedException;
}import java.math.BigInteger;
public class ExpensiveFunction implements Computable<String,BigInteger>{
@Override
public BigInteger compute(String arg) throws InterruptedException {
//假设经过长时间计算arg
return new BigInteger(arg);
}
}一. 使用HashMap和同步机制来初始化缓存
import java.util.HashMap;
import java.util.Map;
public class Memoizer1<A, V> implements Computable<A,V>{
private final Map<A,V> cache = new HashMap<A,V>();
private final Computable<A,V> c;
public Memoizer1(Computable<A,V> c) {
this.c = c;
}
@Override
public synchronized V compute(A arg) throws InterruptedException {
V result = cache.get(arg);
if(result == null){
result = c.compute(arg);
4000
cache.put(arg, result);
}
return result;
}
}这种方法虽然保证了线程的安全性,却带来了一个明显的可伸缩性问题: 每次只有一个线程能够执行compute.
从上图可以看出,当A线程计算出f(1)时,C线程还不能直接得到f(1),需要等待B线程,假如很多线程进行compute方法的调用,可能导致后面的线程严重阻塞.
二. 使用ConcurrentHashMap替换HashMap
Memoizer2比Memoizer1有着更好的并发行为,多线程可以并发的使用它.import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class Memoizer2<A, V> implements Computable<A, V>{
private final Map<A,V> cache = new ConcurrentHashMap<>();
private final Computable<A,V> c;
public Memoizer2(Computable<A,V> c) {
this.c = c;
}
@Override
public V compute(A arg) throws InterruptedException {
V result = cache.get(arg);
if(result == null){
result = c.compute(arg);
cache.put(arg, result);
}
return result;
}
}但是Memoizer2仍然存在一些不足,当两个线程调用compute时,可能会导致重复计算.
Memoizer2的主要问题在于,如果f(n)中间的计算开销很大的话,而其他线程并不知道这个计算正在进行,那么很可能会重复这个计算.
三. 基于FutureTask的Memoizing封装器
import java.util.Map;
import java.util.concurrent.Callable;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import java.util.concurrent.FutureTask;
public class Memoizer3<A, V> implements Computable<A, V>{
private final Map<A,Future<V>> cache = new ConcurrentHashMap<A,Future<V>> ();
private final Computable<A,V> c;
public Memoizer3(Computable<A,V> c) {
this.c = c;
}
@Override
public V compute(A arg) throws InterruptedException {
Future<V> f = cache.get(arg);
if(f==null){
Callable<V> eval = new Callable<V>(){
@Override
public V call() throws Exception {
return c.compute(arg);
}
};
FutureTask<V> ft = new FutureTask<>(eval);
f = ft;
cache.put(arg, ft);
ft.run();
}
try {
return f.get();
} catch (ExecutionException e) {
e.printStackTrace();
}
return null;
}
}Memoizer3的实现几乎是完美的,它表现了非常好的并发性,若结果已经计算出来了,那么将立即返回.
如果其他线程正在计算该结果,那么新到的线程将一直等待这个结果被计算出来.
它只有一个缺陷,即仍然存在两个线程计算出相同的值的漏洞,这个漏洞的发生概率要远小于Memoizer2.
这个缺陷原因在于,if中的代码块,仍然是非原子的.
四. 将添加计算任务FutureTask原子化
import java.util.Map;
import java.util.concurrent.Callable;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import java.util.concurrent.FutureTask;
public class Memoizer4<A, V> implements Computable<A, V>{
private final Map<A,Future<V>> cache = new ConcurrentHashMap<A,Future<V>> ();
private final Computable<A,V> c;
public Memoizer4(Computable<A,V> c) {
this.c = c;
}
@Override
public V compute(A arg) throws InterruptedException {
Future<V> f = cache.get(arg);
if(f==null){
Callable<V> eval = new Callable<V>(){
@Override
public V call() throws Exception {
return c.compute(arg);
}
};
FutureTask<V> ft = new FutureTask<>(eval);
f = cache.putIfAbsent(arg, ft);
if(f==null){
f = ft;
ft.run();
}
}
try {
return f.get();
} catch (ExecutionException e) {
e.printStackTrace();
}
return null;
}
}仍然存在的问题:
由于缓存的是Future而不是值,将导致缓存污染.
例如: 当某个future计算失败的时候,Map中依然存储着该future,没有被移除.
最终版本:
try {
return f.get();
} catch (ExecutionException e) {
cache.remove(arg,f);
}

相关文章推荐
- 【JAVA并发编程实战】5、构建高效且可伸缩的结果缓存
- java并发工具类构建高效且可伸缩的结果缓存
- java并发——构建高效且可伸缩的结果缓存
- Java并发(具体实例)—— 构建高效且可伸缩的结果缓存
- Java并发(具体实例)——构建高效且可伸缩的结果缓存
- 一头扎进多线程-构建高效且可伸缩的结果缓存
- 构建高效且可伸缩的结果缓存
- 《Java并发编程实战》 阅读笔记 构建高效且可伸缩的结果缓存
- java并发编程实战-构建高效且可伸缩的结果缓存
- 【多线程_提高篇】 创建高效且可伸缩的结果缓存
- 构建高效可伸缩的结果缓存
- Java趣谈——如何构建一个高效且可伸缩的缓存
- 构建高效且可伸缩的结果缓存引申的并发测试规范化
- 构建高效且可伸缩的结果缓存
- Java并发编程之为计算结果建立高效、可伸缩的高速缓存
- java并发编程实践学习(5)构建块为计算结果建立高效,可伸缩的高速缓存
- java高效获取多线程执行结果
- 构建高效可申缩的结果缓存
- 构建java高效的缓存
- Java并发编程基础构建模块(06)——高效缓存总结示例