解决《用Python写网络爬虫》中示例网站访问不了的问题
2017-05-26 11:27
423 查看
最近在看《用Python写网络爬虫》这本书学习网络爬虫知识,个人感觉从书中使用Python2我个人使用Python3来说这个过程已经有点儿虐了,但是没想到更虐的是从我学习这本书开始书中的示例网站http://example.webscraping.com我就访问不了,试了三天都是502错误,所以今天找了另外的解决办法,分享给遇到同样问题的朋友,希望对你们有所帮助
https://bitbucket.org/wswp/places 在这个网站下载web2py(点击download here下载)并解压
链接:http://pan.baidu.com/s/1sluHThV 密码:wuj0 在百度网盘下载这个
将百度网盘中下载的压缩包解压到web2py_win\web2py\applications目录下(这个目录是自己解压的目录)
返回上级web2py_win\web2py,在这个目录下找到web2py.exe运行
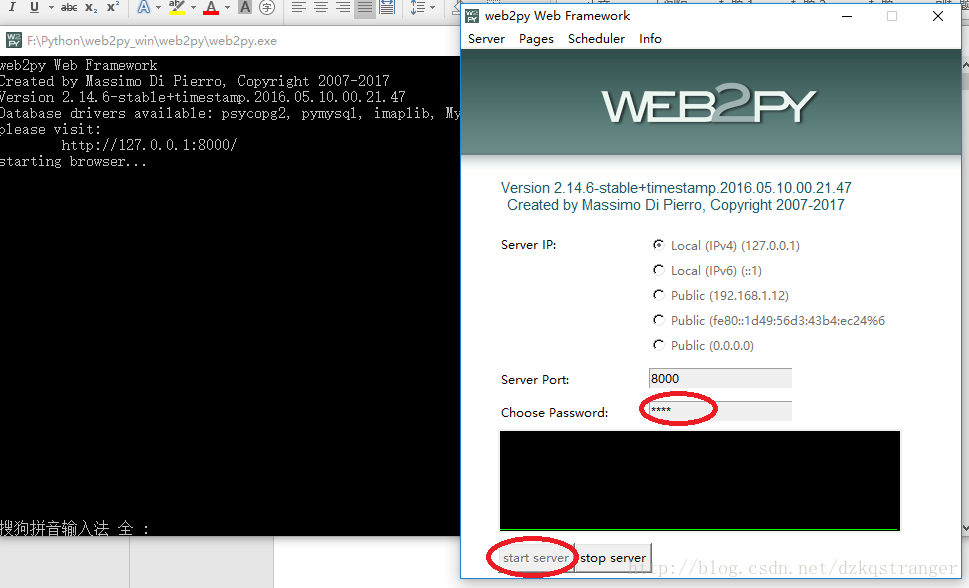
password自己填写即可,填写完password之后点击下面的“start server”即可
打开浏览器,在地址栏输入http://127.0.0.1:8000/places这个网址,就可以浏览了示例网站了,爬虫的时候应该也是用这个网址的
(PS:后续爬虫过程中我也不知道会出现什么问题,走一步看一步!如果有什么问题欢迎大家指正)
参考:http://www.cnblogs.com/hdan/archive/2017/03/29/6641848.html 百度网盘中分享的文件来自这个分享,如有不妥请告知删除
https://bitbucket.org/wswp/places 在这个网站下载web2py(点击download here下载)并解压
链接:http://pan.baidu.com/s/1sluHThV 密码:wuj0 在百度网盘下载这个
将百度网盘中下载的压缩包解压到web2py_win\web2py\applications目录下(这个目录是自己解压的目录)
返回上级web2py_win\web2py,在这个目录下找到web2py.exe运行
password自己填写即可,填写完password之后点击下面的“start server”即可
打开浏览器,在地址栏输入http://127.0.0.1:8000/places这个网址,就可以浏览了示例网站了,爬虫的时候应该也是用这个网址的
(PS:后续爬虫过程中我也不知道会出现什么问题,走一步看一步!如果有什么问题欢迎大家指正)
参考:http://www.cnblogs.com/hdan/archive/2017/03/29/6641848.html 百度网盘中分享的文件来自这个分享,如有不妥请告知删除

相关文章推荐
- 《用Python写网络爬虫》示例网站访问不了导致的系列问题解决办法
- 一步一步SharePoint 2007之十九:解决实现注册用户后,自动具备访问网站的权限的问题(1)——配置Provider
- 一步一步SharePoint 2007之十九:解决实现注册用户后,自动具备访问网站的权限的问题(1)——配置Provider
- 匿名用户访问用发布站点模板创建网站的列表项时要求登录的问题解决
- IIS ASP.NET网站部署问题解决: ASP.NET 未被授权访问所请求的资源。请考虑授予 ASP.NET 请求标识访问此资源的权限。
- 为电脑司版GHOST XP安装IIS 还有在IIS里面打不开网站的解决办法 访问IIS 元数据库失败的问题
- 匿名用户访问用发布站点模板创建网站的列表项时要求登录的问题解决
- Python2.5.4移植项目:import module问题的解决与boa服务器CGI访问问题
- IIS中网站弹出登陆框之匿名访问权限问题解决办法
- pf loopback rdr 解决内网nat上网发布内网web网站时,内网用户自己不可访问的问题。
- IIS ASP.NET网站部署问题解决: ASP.NET 未被授权访问所请求的资源。请考虑授予 ASP.NET 请求标识访问此资源的权限。
- 一步一步SharePoint 2007之二十:解决实现注册用户后,自动具备访问网站的权限的问题(2)——配置Role
- 一步一步SharePoint 2007之二十一:解决实现注册用户后,自动具备访问网站的权限的问题(3)——创建用户
- 一步一步SharePoint 2007之二十:解决实现注册用户后,自动具备访问网站的权限的问题(2)——配置Role
- 当网站有用户访问时,重启Tomcat,报Serializable session的问题解决方法
- 一步一步SharePoint 2007之十九:解决实现注册用户后,自动具备访问网站的权限的问题(1)——配置Provider
- 一步一步SharePoint 2007之二十一:解决实现注册用户后,自动具备访问网站的权限的问题(3)——创建用户
- 匿名用户访问用发布站点模板创建网站的列表项时要求登录的问题解决
- 还为使用google搜索找不到自己要的技术文章吗?彻底解决访问google域名地址搜索网站间歇访问无法找到服务器的问题
- 解决:此错误(HTTP 500 内部服务器错误)意味着您正在访问的网站出现了服务器问题,此问题阻止了该网页的显示