数据库设计与性能优化(一)
2017-05-25 02:30
246 查看
**
节省数据的存储空间。
能够保证数据的完整性。
方便进行数据库应用系统的开发。
糟糕的数据库设计:
数据冗余、存储空间浪费。
内存空间浪费。
数据更新和插入异常麻烦。
数据库的生命周期:
1、需求分析阶段 确定需求(与客户沟通)
2、逻辑设计阶段 通过数据模型(E-R模型、UML图例)得到数据概念模型 -> 转换为SQL表 -> 规范化
3、物理设计阶段 选择索引
4、实现阶段 把物理设计的结果转换为数据库管理系统(DBMS)中的DDL创建数据结构。通过SQL语句来进行增删改查。
5、再设计再修改。
6、废止
E-R图
E 实体 (一个学生、一本书、一门课、一个会议、一个关系…)
R 属性 (人的属性:年龄、性别 学生的属性:学号、性别、年龄…)
元组就是表中的一行。
分量就是某个属性值。
码就是表中唯一可以确定一个元组的某个属性,可以作为码的都是候选码,选出的一个码就是主码。
外码是一个属性(或者属性组),它不是码,但是它是别的表的码。
域是属性的取值范围。
概率示例图:
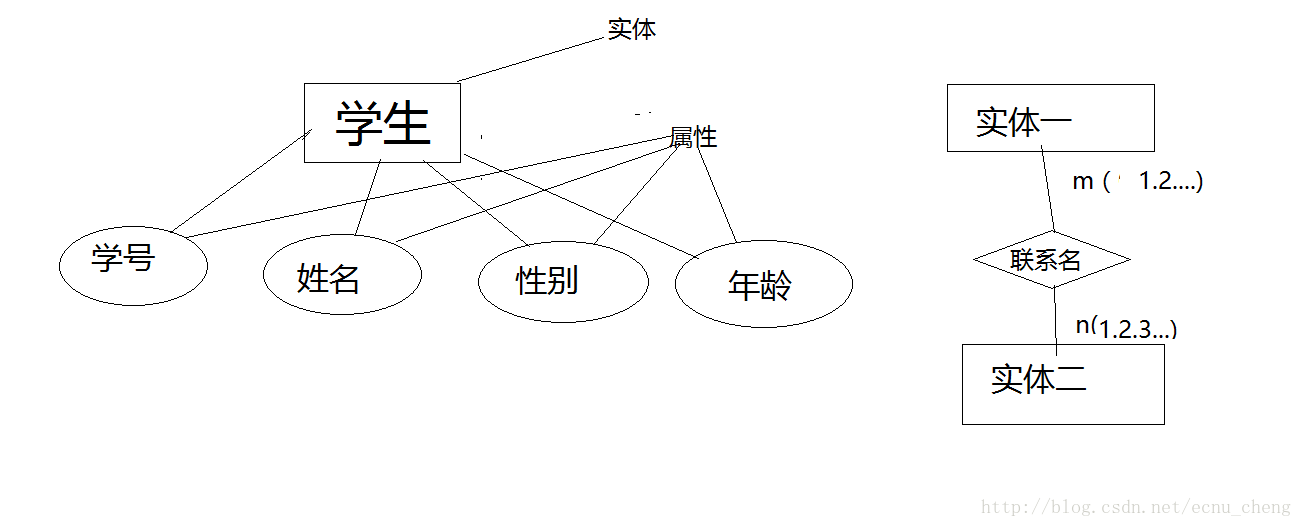
专业的画图工具有 Microsoft Vision 、、、
现在有一个教学管理系统。系统实体有:
教师,属性有 教师号、姓名、性别、年龄、出生日期、专业,其中教师号为码。
学生,属性有 学号、姓名、性别、出生日期、籍贯、专业,其中学号为码。
课程,属性有 课程号、课程名、学时数、学分、教材,其中课程号为码。
实体间的关系是:一个教师可以教授多门课程,一门课程可以被多名教师讲授,即教师与课程之间是多对多的关系。一个学生可以选修多门课程,一门课程可以被多名学生选修,即学生与课程之间是多对多的关系。
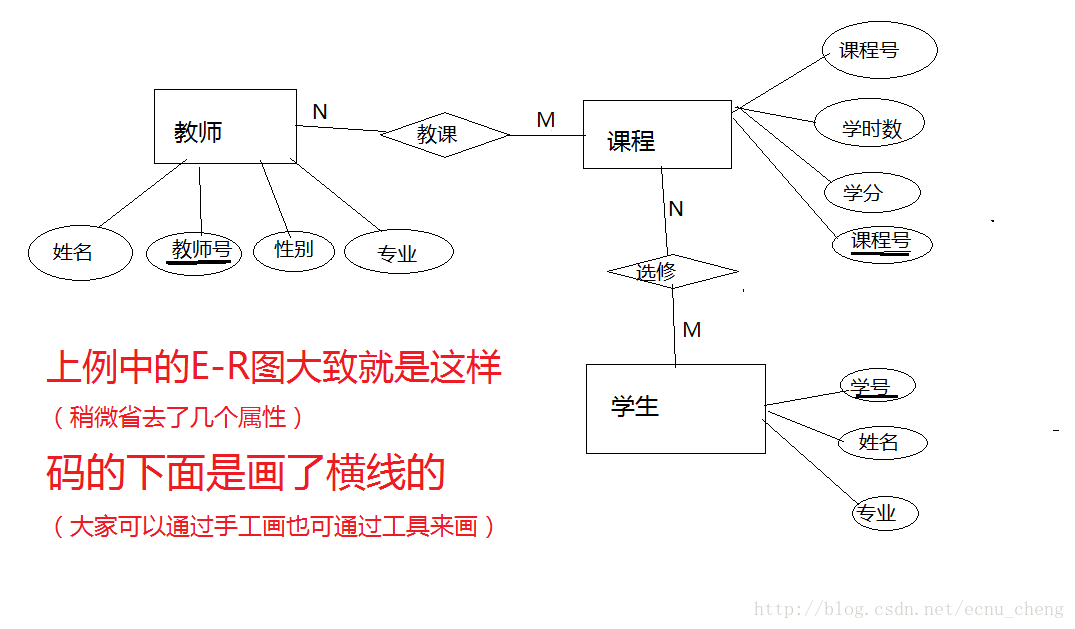
E-R图设计是属于数据库的逻辑设计阶段的。
E-R图转换为数据表的原则:
1、每一个实体应该映射为一个表。
例如:教师表、课程表、学生表
2、一般多对多的关系也应该映射为一个表,表中应该包含关系双方的码属性,同时还应该包含该关系本身的一些属性,如果该关系有属性的话(例如上例中的选修关系它就含有一个成绩属性,因为每位学生选的每一门课都有一个唯一的成绩,这个成绩属性就包含在选修这个关系中,所以我们建立选修表的时候不但要将学生和课程的码放进来,同时也要将该学生选修该门课程的成绩放进来;再例如上例中的教课关系也会有一个自己的属性:教课时间,因为每位老师上的每一门课的时间都是唯一的而且不同的课不同的老师时间不一定相同,所以教课时间是教课关系表中的一个属性,关系表的主键一般以双方的主键组合作为联合主键)。但是一对多(例如一个学生属于一个班,但是一个班可以有很多个学生,这个时候,可以在学生实体表中添加一个班级的码就可以有效关联学生和班级而不需要再去建一张学生和班级的关系表了)或者一对一(可以将一对一的两张表合并定义为一张新的表也可以按照一对多的方法建表)的关系则可以不用映射出一个关系表。
两个关系表大致如下:
选课表(课程号,学号,成绩) 也可以叫成绩表
教课表(课程号,教师号,开课时间) 也可以叫排课表
数据库的规范化
就是要对表中的属性来做设计,防止数据冗余,存储空间浪费,内存空间浪费,数据更新和插入异常。
基于数据冗余提出了有五个设计范式。
第五范式数据冗余率最低,但是数据会被分解到很多张表,会给检索造成较大负担,因为检索结果要关联很多张表才能得到。
一般设计到第三范式就已经不错了。即可以减少数据冗余又可以实现较快的检索。
1NF表示表中的数据的每一个字段都是不可以再分割的原子数据。
2NF表示在满足1NF的情况下,表中的非码属性必须被联合主键决定,不能有联合主键中的某一个属性决定。例如:
成绩表(课程号,学号,成绩,课程名)
这个成绩表中的”课程名“这个属性只依赖课程号这一个属性,而不是依赖课程名和学号这个联合主键,所以这张表不满足2NF,需要将这张表分解为如下两张表才能满足2NF
成绩表(课程号,学号,成绩)
课程表(_课程号,课程名)
3NF表示在满足2NF的情况下,每一个非关键字必须由关键字来决定而不能由非关键字来决定。
例如:
信息表(_职工编号,职工姓名,部门名称,部门位置)
这个信息表的主键是职工编号,但是部门经理名称并不依赖职工编号而是依赖与非主键的部门名,这样就不满足3NF了,可做如下修改
职工表(_职工编号,职工姓名,部门编号)
部门表(_部门编号,部门名称,部门位置)
良好的数据库设计能够
**:节省数据的存储空间。
能够保证数据的完整性。
方便进行数据库应用系统的开发。
糟糕的数据库设计:
数据冗余、存储空间浪费。
内存空间浪费。
数据更新和插入异常麻烦。
数据库的生命周期:
1、需求分析阶段 确定需求(与客户沟通)
2、逻辑设计阶段 通过数据模型(E-R模型、UML图例)得到数据概念模型 -> 转换为SQL表 -> 规范化
3、物理设计阶段 选择索引
4、实现阶段 把物理设计的结果转换为数据库管理系统(DBMS)中的DDL创建数据结构。通过SQL语句来进行增删改查。
5、再设计再修改。
6、废止
E-R图
E 实体 (一个学生、一本书、一门课、一个会议、一个关系…)
R 属性 (人的属性:年龄、性别 学生的属性:学号、性别、年龄…)
元组就是表中的一行。
分量就是某个属性值。
码就是表中唯一可以确定一个元组的某个属性,可以作为码的都是候选码,选出的一个码就是主码。
外码是一个属性(或者属性组),它不是码,但是它是别的表的码。
域是属性的取值范围。
概率示例图:
专业的画图工具有 Microsoft Vision 、、、
现在有一个教学管理系统。系统实体有:
教师,属性有 教师号、姓名、性别、年龄、出生日期、专业,其中教师号为码。
学生,属性有 学号、姓名、性别、出生日期、籍贯、专业,其中学号为码。
课程,属性有 课程号、课程名、学时数、学分、教材,其中课程号为码。
实体间的关系是:一个教师可以教授多门课程,一门课程可以被多名教师讲授,即教师与课程之间是多对多的关系。一个学生可以选修多门课程,一门课程可以被多名学生选修,即学生与课程之间是多对多的关系。
E-R图设计是属于数据库的逻辑设计阶段的。
E-R图转换为数据表的原则:
1、每一个实体应该映射为一个表。
例如:教师表、课程表、学生表
2、一般多对多的关系也应该映射为一个表,表中应该包含关系双方的码属性,同时还应该包含该关系本身的一些属性,如果该关系有属性的话(例如上例中的选修关系它就含有一个成绩属性,因为每位学生选的每一门课都有一个唯一的成绩,这个成绩属性就包含在选修这个关系中,所以我们建立选修表的时候不但要将学生和课程的码放进来,同时也要将该学生选修该门课程的成绩放进来;再例如上例中的教课关系也会有一个自己的属性:教课时间,因为每位老师上的每一门课的时间都是唯一的而且不同的课不同的老师时间不一定相同,所以教课时间是教课关系表中的一个属性,关系表的主键一般以双方的主键组合作为联合主键)。但是一对多(例如一个学生属于一个班,但是一个班可以有很多个学生,这个时候,可以在学生实体表中添加一个班级的码就可以有效关联学生和班级而不需要再去建一张学生和班级的关系表了)或者一对一(可以将一对一的两张表合并定义为一张新的表也可以按照一对多的方法建表)的关系则可以不用映射出一个关系表。
两个关系表大致如下:
选课表(课程号,学号,成绩) 也可以叫成绩表
教课表(课程号,教师号,开课时间) 也可以叫排课表
数据库的规范化
就是要对表中的属性来做设计,防止数据冗余,存储空间浪费,内存空间浪费,数据更新和插入异常。
基于数据冗余提出了有五个设计范式。
第五范式数据冗余率最低,但是数据会被分解到很多张表,会给检索造成较大负担,因为检索结果要关联很多张表才能得到。
一般设计到第三范式就已经不错了。即可以减少数据冗余又可以实现较快的检索。
1NF表示表中的数据的每一个字段都是不可以再分割的原子数据。
2NF表示在满足1NF的情况下,表中的非码属性必须被联合主键决定,不能有联合主键中的某一个属性决定。例如:
成绩表(课程号,学号,成绩,课程名)
这个成绩表中的”课程名“这个属性只依赖课程号这一个属性,而不是依赖课程名和学号这个联合主键,所以这张表不满足2NF,需要将这张表分解为如下两张表才能满足2NF
成绩表(课程号,学号,成绩)
课程表(_课程号,课程名)
3NF表示在满足2NF的情况下,每一个非关键字必须由关键字来决定而不能由非关键字来决定。
例如:
信息表(_职工编号,职工姓名,部门名称,部门位置)
这个信息表的主键是职工编号,但是部门经理名称并不依赖职工编号而是依赖与非主键的部门名,这样就不满足3NF了,可做如下修改
职工表(_职工编号,职工姓名,部门编号)
部门表(_部门编号,部门名称,部门位置)

相关文章推荐
- 系统性能调优(2)----数据库设计优化
- 数据库性能优化之索引设计原则及其分析
- 一、数据库设计与性能优化--概述
- 一、数据库设计与性能优化--概述
- Mysql性能优化-数据库设计
- 关于ZFS和数据库存储性能的优化设计
- 数据库的架构设计与性能优化
- 性能优化系列六:数据库设计
- MySQL性能管理及架构设计(二):数据库结构优化、高可用架构设计、数据库索引优化
- 【系统性能优化】(二)数据库设计
- 系统性能调优(2)----数据库设计优化
- 数据库设计,数据库性能优化(teched 2008讲义)
- 优化设计提高sql类数据库的性能
- 数据库性能优化
- ASP.NET设计中的性能优化问题
- ASP.NET设计中的性能优化问题
- 几个简单的步骤大幅提高Oracle性能--我优化数据库的三板斧
- 数据库优化设计方案
- ASP.NET设计中的性能优化问题
- 漫谈ASP.NET设计中的性能优化问题