[置顶] 【go语言爬虫】网贷天眼数据平台爬虫
2017-05-23 15:23
357 查看
一、需求分析
利用go语言抓取网贷天眼数据平台昨日数据
字段:
排序 平台名称 成交额 综合利率 投资人 借款周期 借款人 满标速度 累计贷款余额 资金净流入
抓取url:
http://www.p2peye.com/shuju/ptsj/
二、go语言爬虫实现源代码
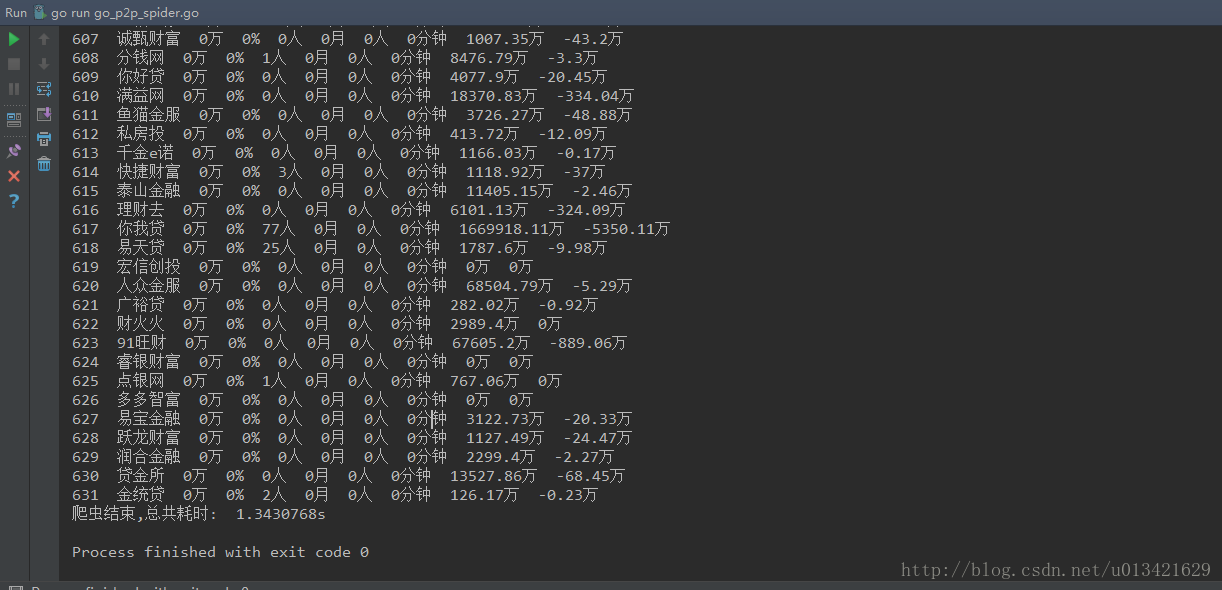

利用go语言抓取网贷天眼数据平台昨日数据
字段:
排序 平台名称 成交额 综合利率 投资人 借款周期 借款人 满标速度 累计贷款余额 资金净流入
抓取url:
http://www.p2peye.com/shuju/ptsj/
二、go语言爬虫实现源代码
package main
import (
"fmt"
"io/ioutil"
"net/http"
"time"
"os"
"regexp"
"github.com/axgle/mahonia"
)
//定义新的数据类型
type Spider1 struct {
url string
header map[string]string
}
//定义 Spider get的方法
func (keyword Spider1) get_html_header() string {
client := &http.Client{}
req, err := http.NewRequest("GET", keyword.url, nil)
if err != nil {
}
for key, value := range keyword.header {
req.Header.Add(key, value)
}
resp, err := client.Do(req)
if err != nil {
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
}
return string(body)
}
func parse1() {
header := map[string]string{
"Host":"www.p2peye.com",
"Connection":"keep-alive",
"Cache-Control":"max-age=0",
"Upgrade-Insecure-Requests":"1",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Referer":"http://www.p2peye.com/shuju/hysj/",
"Accept-Language":"zh-CN,zh;q=0.8",
}
//创建excel文件
f, err := os.Create("C:/p2p.xlsx")
if err != nil {
panic(err)
}
defer f.Close()
//写入标题
f.WriteString("排序"+"\t"+"平台名称"+"\t"+"成交额"+"\t" +"综合利率"+"\t" +"投资人"+"\t"+"借款周期"+"\t"+"借款人"+"\t"+"满标速度"+"\t"+"累计贷款余额"+"\t"+"资金净流入"+"\r\n")
url := "http://www.p2peye.com/shuju/ptsj/"
spider := &Spider1{url, header}
html := spider.get_html_header()
//设置编码格式
decoder := mahonia.NewDecoder("gbk")
html1:=decoder.ConvertString(html)
//排序
pattern1 := `<td class="num">(.*?)</td>`
rp1 := regexp.MustCompile(pattern1)
find_txt1 := rp1.FindAllStringSubmatch(html1, -1)
//平台名称
pattern2 := ` onclick="return false" title="(.*)">`
rp2 := regexp.MustCompile(pattern2)
find_txt2 := rp2.FindAllStringSubmatch(html1, -1)
//成交额
pattern3 := `<td class="total">(.*?)</td>`
rp3 := regexp.MustCompile(pattern3)
find_txt3 := rp3.FindAllStringSubmatch(html1, -1)
//综合利率
pattern4 := `<td class="rate">(.*?)</td>`
rp4 := regexp.MustCompile(pattern4)
find_txt4 := rp4.FindAllStringSubmatch(html1, -1)
//投资人
pattern5 := `<td class="pnum">(.*?)</td>`
rp5 := regexp.MustCompile(pattern5)
find_txt5 := rp5.FindAllStringSubmatch(html1, -1)
//借款周期
pattern6 := `<td class="cycle">(.*?)</td>`
rp6 := regexp.MustCompile(pattern6)
find_txt6 := rp6.FindAllStringSubmatch(html1, -1)
//借款人
pattern7 := `<td class="p1num">(.*?)</td>`
rp7 := regexp.MustCompile(pattern7)
find_txt7 := rp7.FindAllStringSubmatch(html1, -1)
//满标速度
pattern8 := `<td class="fuload">(.*?)</td>`
rp8 := regexp.MustCompile(pattern8)
find_txt8 := rp8.FindAllStringSubmatch(html1, -1)
//累计贷款余额
pattern9 := `<td class="alltotal">(.*?)</td>`
rp9 := regexp.MustCompile(pattern9)
find_txt9 := rp9.FindAllStringSubmatch(html1, -1)
//资金净流入
pattern10 := `<td class="capital">(.*?)</td>`
rp10 := regexp.MustCompile(pattern10)
find_txt10 := rp10.FindAllStringSubmatch(html1, -1)
//// 写入UTF-8 BOM
f.WriteString("\xEF\xBB\xBF")
//// 打印全部数据和写入excel文件
for i := 0; i < len(find_txt1); i++ {
fmt.Printf("%s %s %s %s %s %s %s %s %s %s\n",find_txt1[i][1],find_txt2[i][1],find_txt3[i][1],find_txt4[i][1],find_txt5[i][1],find_txt6[i][1],
find_txt7[i][1],find_txt8[i][1],find_txt9[i][1],find_txt10[i][1])
f.WriteString(find_txt1[i][1] + "\t" + find_txt2[i][1] + "\t" + find_txt3[i][1] + "\t"+find_txt4[i][1] + "\t" + find_txt5[i][1] + "\t"+
find_txt6[i][1] + "\t"+find_txt7[i][1] + "\t" + find_txt8[i][1] + "\t" + find_txt9[i][1] + "\t"+find_txt10[i][1] + "\r\n")
}
}
func main() {
t1 := time.Now() // get current time
parse1()
elapsed := time.Since(t1)
fmt.Println("爬虫结束,总共耗时: ", elapsed)
}

相关文章推荐
- [置顶] 【R语言爬虫】网贷天眼数据平台表格数据抓取2
- [置顶] 【R语言爬虫】网贷天眼平台表格数据爬虫1
- [置顶] 【python爬虫】网贷天眼平台表格数据抓取
- [置顶] 【go语言爬虫】go语言爬取豆瓣电影top250
- [置顶] 【R语言 数据分析】豆瓣电影R语言爬虫和数据分析
- [置顶] 【go语言爬虫】go语言高性能抓取手机号码归属地、所属运营商
- 使用GO语言开发 Redis数据监控程序
- 全球数据显示Go语言在中国最流行
- Go语言中怎样判断数据类型
- Go语言 简单的爬虫示例(2)——编码转换
- JAVA平台上的网络爬虫脚本语言 CrawlScript
- GO语言基本数据类型总结
- 高可用数据采集平台(如何玩转3门语言php+.net+aauto)
- [置顶] Oracle数据操作和控制语言详解
- go语言通过zlib压缩数据的方法
- 语音识别之获取语言数据(portaudio的平台搭建)
- Go语言服务器开发之客户端向服务器发送数据并接收返回数据的方法
- go语言使用protobuf与c++做数据通信。
- Go语言 爬虫2-编码转换
- Go 语言将在1.4版本中支持面向Android平台开发