OkHttp 3.7源码分析(五)——连接池
2017-05-21 14:43
399 查看
接下来讲下OkHttp的连接池管理,这也是OkHttp的核心部分。通过维护连接池,最大限度重用现有连接,减少网络连接的创建开销,以此提升网络请求效率。

这种方法的好处是简单,各个请求互不干扰。但在复杂的网络请求场景下这种方式几乎不可用。例如:浏览器加载一个HTML网页,HTML中可能需要加载数十个资源,典型场景下这些资源中大部分来自同一个站点。按照HTTP1.0的做法,这需要建立数十个TCP连接,每个连接负责一个资源请求。创建一个TCP连接需要3次握手,而释放连接则需要2次或4次握手。重复的创建和释放连接极大地影响了网络效率,同时也增加了系统开销。
为了有效地解决这一问题,HTTP/1.1提出了

在现代浏览器中,一般同时开启6~8个keepalive connections的socket连接,并保持一定的链路生命,当不需要时再关闭;而在服务器中,一般是由软件根据负载情况(比如FD最大值、Socket内存、超时时间、栈内存、栈数量等)决定是否主动关闭。
报头压缩:HTTP/2使用HPACK压缩格式压缩请求和响应报头数据,减少不必要流量开销
请求与响应复用:HTTP/2通过引入新的二进制分帧层实现了完整的请求和响应复用,客户端和服务器可以将HTTP消息分解为互不依赖的帧,然后交错发送,最后再在另一端将其重新组装
指定数据流优先级:将 HTTP 消息分解为很多独立的帧之后,我们就可以复用多个数据流中的帧,客户端和服务器交错发送和传输这些帧的顺序就成为关键的性能决定因素。为了做到这一点,HTTP/2 标准允许每个数据流都有一个关联的权重和依赖关系
流控制:HTTP/2 提供了一组简单的构建块,这些构建块允许客户端和服务器实现其自己的数据流和连接级流控制
HTTP/2所有性能增强的核心在于新的二进制分帧层,它定义了如何封装HTTP消息并在客户端与服务器之间进行传输:
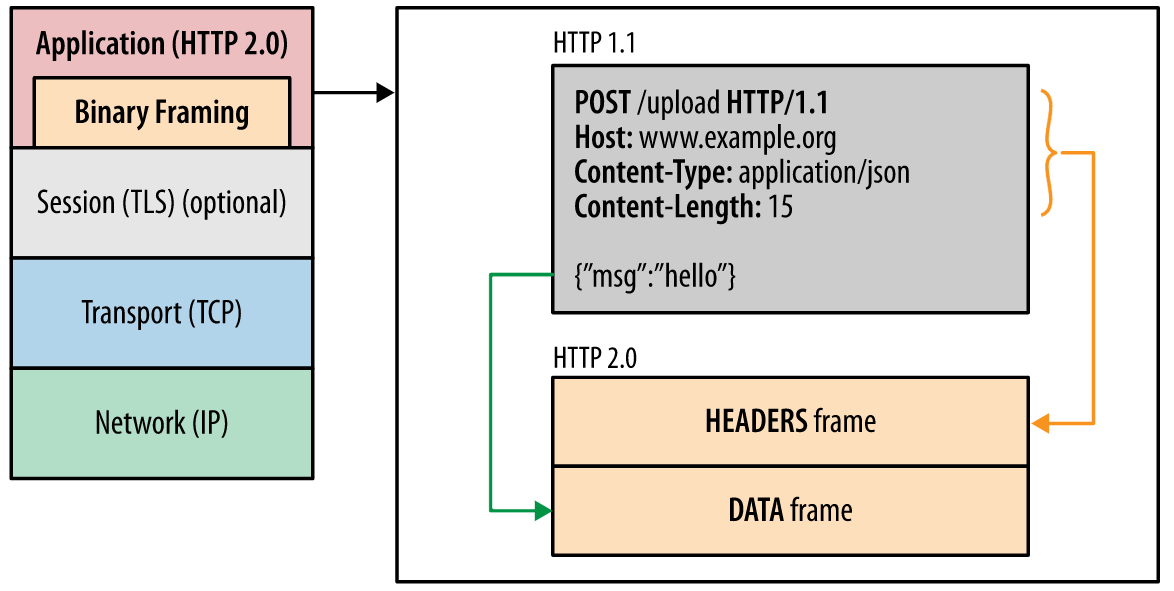
同时HTTP/2引入了三个新的概念:
数据流:基于TCP连接之上的逻辑双向字节流,对应一个请求及其响应。客户端每发起一个请求就建立一个数据流,后续该请求及其响应的所有数据都通过该数据流传输
消息:一个请求或响应对应的一系列数据帧
帧:HTTP/2的最小数据切片单位
上述概念之间的逻辑关系:
所有通信都在一个 TCP 连接上完成,此连接可以承载任意数量的双向数据流
每个数据流都有一个唯一的标识符和可选的优先级信息,用于承载双向消息
每条消息都是一条逻辑 HTTP 消息(例如请求或响应),包含一个或多个帧
帧是最小的通信单位,承载着特定类型的数据,例如 HTTP 标头、消息负载,等等。 来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装
每个HTTP消息被分解为多个独立的帧后可以交错发送,从而在宏观上实现了多个请求或响应并行传输的效果。这类似于多进程环境下的时间分片机制
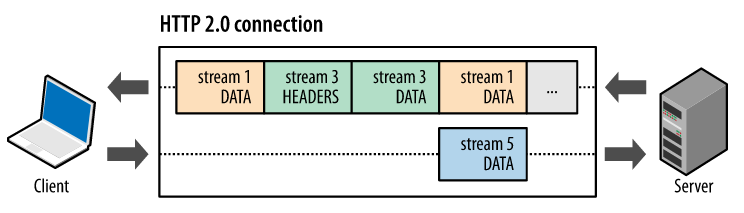
OkHttp内部通过ConnectionPool来管理连接池,首先来看下ConnectionPool的主要成员:
相关概念:
这样做的原因是:
Internal的唯一实现在OkHttpClient中,OkHttpClient通过这种方式暴露其API给外部类使用。
put:放入新连接
get:从连接池中获取连接
evictAll:关闭所有连接
connectionBecameIdle:连接变空闲后调用清理线程
deduplicate:清除重复的多路复用线程
2.2.1 StreamAllocation.findConnection
get是ConnectionPool中最为重要的方法,
其主要逻辑大致分为以下几个步骤:
查看当前streamAllocation是否有之前已经分配过的连接,有则直接使用
从连接池中查找可复用的连接,有则返回该连接
配置路由,配置后再次从连接池中查找是否有可复用连接,有则直接返回
新建一个连接,并修改其StreamAllocation标记计数,将其放入连接池中
查看连接池是否有重复的多路复用连接,有则清除
2.2.2 ConnectionPool.get
接下来再来看get方法的源码:
其逻辑比较简单,遍历当前连接池,如果有符合条件的连接则修改器标记计数,然后返回。这里的关键逻辑在
连接没有达到共享上限
非host域必须完全一样
如果此时host域也相同,则符合条件,可以被复用
如果host不相同,在HTTP/2的域名切片场景下一样可以复用,具体细节可以参考:https://hpbn.co/optimizing-application-delivery/#eliminate-domain-sharding
2.2.3 deduplicate
deduplicate方法主要是针对在HTTP/2场景下多个多路复用连接清除的场景。如果当前连接是HTTP/2,那么所有指向该站点的请求都应该基于同一个TCP连接:
put和evictAll比较简单,在这里就不写了,大家自行看源码。
当连接池中put新的连接时
当connectionBecameIdle接口被调用时
其代码如下:
这段死循环实际上是一个阻塞的清理任务,首先进行清理(clean),并返回下次需要清理的间隔时间,然后调用
接下来看下cleanup函数:
其基本逻辑如下:
遍历连接池中所有连接,标记泄露连接
如果被标记的连接满足(
如果(
如果(
而
OkHttp的连接池通过计数+标记清理的机制来管理连接池,使得无用连接可以被会回收,并保持多个健康的keep-alive连接。这也是OkHttp的连接池能保持高效的关键原因。
1. 背景
1.1 keep-alive机制
在HTTP1.0中HTTP的请求流程如下:这种方法的好处是简单,各个请求互不干扰。但在复杂的网络请求场景下这种方式几乎不可用。例如:浏览器加载一个HTML网页,HTML中可能需要加载数十个资源,典型场景下这些资源中大部分来自同一个站点。按照HTTP1.0的做法,这需要建立数十个TCP连接,每个连接负责一个资源请求。创建一个TCP连接需要3次握手,而释放连接则需要2次或4次握手。重复的创建和释放连接极大地影响了网络效率,同时也增加了系统开销。
为了有效地解决这一问题,HTTP/1.1提出了
Keep-Alive机制:当一个HTTP请求的数据传输结束后,TCP连接不立即释放,如果此时有新的HTTP请求,且其请求的Host通上次请求相同,则可以直接复用为释放的TCP连接,从而省去了TCP的释放和再次创建的开销,减少了网络延时:
在现代浏览器中,一般同时开启6~8个keepalive connections的socket连接,并保持一定的链路生命,当不需要时再关闭;而在服务器中,一般是由软件根据负载情况(比如FD最大值、Socket内存、超时时间、栈内存、栈数量等)决定是否主动关闭。
1.2 HTTP/2
在HTTP/1.x中,如果客户端想发起多个并行请求必须建立多个TCP连接,这无疑增大了网络开销。另外HTTP/1.x不会压缩请求和响应报头,导致了不必要的网络流量;HTTP/1.x不支持资源优先级导致底层TCP连接利用率低下。而这些问题都是HTTP/2要着力解决的。简单来说HTTP/2主要解决了以下问题:报头压缩:HTTP/2使用HPACK压缩格式压缩请求和响应报头数据,减少不必要流量开销
请求与响应复用:HTTP/2通过引入新的二进制分帧层实现了完整的请求和响应复用,客户端和服务器可以将HTTP消息分解为互不依赖的帧,然后交错发送,最后再在另一端将其重新组装
指定数据流优先级:将 HTTP 消息分解为很多独立的帧之后,我们就可以复用多个数据流中的帧,客户端和服务器交错发送和传输这些帧的顺序就成为关键的性能决定因素。为了做到这一点,HTTP/2 标准允许每个数据流都有一个关联的权重和依赖关系
流控制:HTTP/2 提供了一组简单的构建块,这些构建块允许客户端和服务器实现其自己的数据流和连接级流控制
HTTP/2所有性能增强的核心在于新的二进制分帧层,它定义了如何封装HTTP消息并在客户端与服务器之间进行传输:
同时HTTP/2引入了三个新的概念:
数据流:基于TCP连接之上的逻辑双向字节流,对应一个请求及其响应。客户端每发起一个请求就建立一个数据流,后续该请求及其响应的所有数据都通过该数据流传输
消息:一个请求或响应对应的一系列数据帧
帧:HTTP/2的最小数据切片单位
上述概念之间的逻辑关系:
所有通信都在一个 TCP 连接上完成,此连接可以承载任意数量的双向数据流
每个数据流都有一个唯一的标识符和可选的优先级信息,用于承载双向消息
每条消息都是一条逻辑 HTTP 消息(例如请求或响应),包含一个或多个帧
帧是最小的通信单位,承载着特定类型的数据,例如 HTTP 标头、消息负载,等等。 来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装
每个HTTP消息被分解为多个独立的帧后可以交错发送,从而在宏观上实现了多个请求或响应并行传输的效果。这类似于多进程环境下的时间分片机制
2. 连接池的使用与分析
无论是HTTP/1.1的Keep-Alive机制还是HTTP/2的多路复用机制,在实现上都需要引入连接池来维护网络连接。接下来看下OkHttp中的连接池实现。
OkHttp内部通过ConnectionPool来管理连接池,首先来看下ConnectionPool的主要成员:
public final class ConnectionPool {
private static final Executor executor = new ThreadPoolExecutor(0 /* corePoolSize */,
Integer.MAX_VALUE /* maximumPoolSize */, 60L /* keepAliveTime */, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp ConnectionPool", true));
/** The maximum number of idle connections for each address. */
private final int maxIdleConnections;
private final long keepAliveDurationNs;
private final Runnable cleanupRunnable = new Runnable() {
@Override public void run() {
......
}
};
private final Deque<RealConnection> connections = new ArrayDeque<>();
final RouteDatabase routeDatabase = new RouteDatabase();
boolean cleanupRunning;
......
/**
*返回符合要求的可重用连接,如果没有返回NULL
*/
RealConnection get(Address address, StreamAllocation streamAllocation, Route route) {
......
}
/*
* 去除重复连接。主要针对多路复用场景下一个address只需要一个连接
*/
Socket deduplicate(Address address, StreamAllocation streamAllocation) {
......
}
/*
* 将连接加入连接池
*/
void put(RealConnection connection) {
......
}
/*
* 当有连接空闲时唤起cleanup线程清洗连接池
*/
boolean connectionBecameIdle(RealConnection connection) {
......
}
/**
* 扫描连接池,清除空闲连接
*/
long cleanup(long now) {
......
}
/*
* 标记泄露连接
*/
private int pruneAndGetAllocationCount(RealConnection connection, long now) {
......
}
}相关概念:
Call:对Http请求的封装
Connection/RealConnection:物理连接的封装,其内部有
List<WeakReference<StreamAllocation>>的引用计数
StreamAllocation: okhttp中引入了StreamAllocation负责管理一个连接上的流,同时在connection中也通过一个StreamAllocation的引用的列表来管理一个连接的流,从而使得连接与流之间解耦。关于StreamAllocation的定义可以看下这篇文章:okhttp源码学习笔记(二)– 连接与连接管理
connections: Deque双端队列,用于维护连接的容器
routeDatabase:用来记录连接失败的
Route的黑名单,当连接失败的时候就会把失败的线路加进去
2.1 实例化
首先来看下ConnectionPool的实例化过程,一个OkHttpClient只包含一个ConnectionPool,其实例化过程也在OkHttpClient的实例化过程中实现,值得一提的是ConnectionPool各个方法的调用并没有直接对外暴露,而是通过OkHttpClient的Internal接口统一对外暴露:public class OkHttpClient implements Cloneable, Call.Factory, WebSocket.Factory {
static {
Internal.instance = new Internal() {
@Override public void addLenient(Headers.Builder builder, String line) {
builder.addLenient(line);
}
@Override public void addLenient(Headers.Builder builder, String name, String value) {
builder.addLenient(name, value);
}
@Override public void setCache(Builder builder, InternalCache internalCache) {
builder.setInternalCache(internalCache);
}
@Override public boolean connectionBecameIdle(
ConnectionPool pool, RealConnection connection) {
return pool.connectionBecameIdle(connection);
}
@Override public RealConnection get(ConnectionPool pool, Address address,
StreamAllocation streamAllocation, Route route) {
return pool.get(address, streamAllocation, route);
}
@Override public boolean equalsNonHost(Address a, Address b) {
return a.equalsNonHost(b);
}
@Override public Socket deduplicate(
ConnectionPool pool, Address address, StreamAllocation streamAllocation) {
return pool.deduplicate(address, streamAllocation);
}
@Override public void put(ConnectionPool pool, RealConnection connection) {
pool.put(connection);
}
@Override public RouteDatabase routeDatabase(ConnectionPool connectionPool) {
return connectionPool.routeDatabase;
}
@Override public int code(Response.Builder responseBuilder) {
return responseBuilder.code;
}
@Override
public void apply(ConnectionSpec tlsConfiguration, SSLSocket sslSocket, boolean isFallback) {
tlsConfiguration.apply(sslSocket, isFallback);
}
@Override public HttpUrl getHttpUrlChecked(String url)
throws MalformedURLException, UnknownHostException {
return HttpUrl.getChecked(url);
}
@Override public StreamAllocation streamAllocation(Call call) {
return ((RealCall) call).streamAllocation();
}
@Override public Call newWebSocketCall(OkHttpClient client, Request originalRequest) {
return new RealCall(client, originalRequest, true);
}
};
......
}这样做的原因是:
Escalate internal APIs in {@code okhttp3} so they can be used from OkHttp's implementation
packages. The only implementation of this interface is in {@link OkHttpClient}.Internal的唯一实现在OkHttpClient中,OkHttpClient通过这种方式暴露其API给外部类使用。
2.2 连接池维护
ConnectionPool内部通过一个双端队列(dequeue)来维护当前所有连接,主要涉及到的操作包括:put:放入新连接
get:从连接池中获取连接
evictAll:关闭所有连接
connectionBecameIdle:连接变空闲后调用清理线程
deduplicate:清除重复的多路复用线程
2.2.1 StreamAllocation.findConnection
get是ConnectionPool中最为重要的方法,
StreamAllocation在其findConnection方法内部通过调用get方法为其找到stream找到合适的连接,如果没有则新建一个连接。首先来看下
findConnection的逻辑:
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout,
boolean connectionRetryEnabled) throws IOException {
Route selectedRoute;
synchronized (connectionPool) {
if (released) throw new IllegalStateException("released");
if (codec != null) throw new IllegalStateException("codec != null");
if (canceled) throw new IOException("Canceled");
// 一个StreamAllocation刻画的是一个Call的数据流动,一个Call可能存在多次请求(重定向,Authenticate等),所以当发生类似重定向等事件时优先使用原有的连接
RealConnection allocatedConnection = this.connection;
if (allocatedConnection != null && !allocatedConnection.noNewStreams) {
return allocatedConnection;
}
// 试图从连接池中找到可复用的连接
Internal.instance.get(connectionPool, address, this, null);
if (connection != null) {
return connection;
}
selectedRoute = route;
}
// 获取路由配置,所谓路由其实就是代理,ip地址等参数的一个组合
if (selectedRoute == null) {
selectedRoute = routeSelector.next();
}
RealConnection result;
synchronized (connectionPool) {
if (canceled) throw new IOException("Canceled");
//拿到路由后可以尝试重新从连接池中获取连接,这里主要针对http2协议下清除域名碎片机制
Internal.instance.get(connectionPool, address, this, selectedRoute);
if (connection != null) return connection;
//新建连接
route = selectedRoute;
refusedStreamCount = 0;
result = new RealConnection(connectionPool, selectedRoute);
//修改result连接stream计数,方便connection标记清理
acquire(result);
}
// Do TCP + TLS handshakes. This is a blocking operation.
result.connect(connectTimeout, readTimeout, writeTimeout, connectionRetryEnabled);
routeDatabase().connected(result.route());
Socket socket = null;
synchronized (connectionPool) {
// 将新建的连接放入到连接池中
Internal.instance.put(connectionPool, result);
// 如果同时存在多个连向同一个地址的多路复用连接,则关闭多余连接,只保留一个
if (result.isMultiplexed()) {
socket = Internal.instance.deduplicate(connectionPool, address, this);
result = connection;
}
}
closeQuietly(socket);
return result;
}其主要逻辑大致分为以下几个步骤:
查看当前streamAllocation是否有之前已经分配过的连接,有则直接使用
从连接池中查找可复用的连接,有则返回该连接
配置路由,配置后再次从连接池中查找是否有可复用连接,有则直接返回
新建一个连接,并修改其StreamAllocation标记计数,将其放入连接池中
查看连接池是否有重复的多路复用连接,有则清除
2.2.2 ConnectionPool.get
接下来再来看get方法的源码:
[ConnectionPool.java]
RealConnection get(Address address, StreamAllocation streamAllocation, Route route) {
assert (Thread.holdsLock(this));
for (RealConnection connection : connections) {
if (connection.isEligible(address, route)) {
streamAllocation.acquire(connection);
return connection;
}
}
return null;
}其逻辑比较简单,遍历当前连接池,如果有符合条件的连接则修改器标记计数,然后返回。这里的关键逻辑在
RealConnection.isEligible方法:
[RealConnection.java]
/**
* Returns true if this connection can carry a stream allocation to {@code address}. If non-null
* {@code route} is the resolved route for a connection.
*/
public boolean isEligible(Address address, Route route) {
// If this connection is not accepting new streams, we're done.
if (allocations.size() >= allocationLimit || noNewStreams) return false;
// If the non-host fields of the address don't overlap, we're done.
if (!Internal.instance.equalsNonHost(this.route.address(), address)) return false;
// If the host exactly matches, we're done: this connection can carry the address.
if (address.url().host().equals(this.route().address().url().host())) {
return true; // This connection is a perfect match.
}
// At this point we don't have a hostname match. But we still be able to carry the request if
// our connection coalescing requirements are met. See also:
// https://hpbn.co/optimizing-application-delivery/#eliminate-domain-sharding // https://daniel.haxx.se/blog/2016/08/18/http2-connection-coalescing/
// 1. This connection must be HTTP/2.
if (http2Connection == null) return false;
// 2. The routes must share an IP address. This requires us to have a DNS address for both
// hosts, which only happens after route planning. We can't coalesce connections that use a
// proxy, since proxies don't tell us the origin server's IP address.
if (route == null) return false;
if (route.proxy().type() != Proxy.Type.DIRECT) return false;
if (this.route.proxy().type() != Proxy.Type.DIRECT) return false;
if (!this.route.socketAddress().equals(route.socketAddress())) return false;
// 3. This connection's server certificate's must cover the new host.
if (route.address().hostnameVerifier() != OkHostnameVerifier.INSTANCE) return false;
if (!supportsUrl(address.url())) return false;
// 4. Certificate pinning must match the host.
try {
address.certificatePinner().check(address.url().host(), handshake().peerCertificates());
} catch (SSLPeerUnverifiedException e) {
return false;
}
return true; // The caller's address can be carried by this connection.
}连接没有达到共享上限
非host域必须完全一样
如果此时host域也相同,则符合条件,可以被复用
如果host不相同,在HTTP/2的域名切片场景下一样可以复用,具体细节可以参考:https://hpbn.co/optimizing-application-delivery/#eliminate-domain-sharding
2.2.3 deduplicate
deduplicate方法主要是针对在HTTP/2场景下多个多路复用连接清除的场景。如果当前连接是HTTP/2,那么所有指向该站点的请求都应该基于同一个TCP连接:
[ConnectionPool.java]
/**
* Replaces the connection held by {@code streamAllocation} with a shared connection if possible.
* This recovers when multiple multiplexed connections are created concurrently.
*/
Socket deduplicate(Address address, StreamAllocation streamAllocation) {
assert (Thread.holdsLock(this));
for (RealConnection connection : connections) {
if (connection.isEligible(address, null)
&& connection.isMultiplexed()
&& connection != streamAllocation.connection()) {
return streamAllocation.releaseAndAcquire(connection);
}
}
return null;
}put和evictAll比较简单,在这里就不写了,大家自行看源码。
2.3 自动回收
连接池中有socket回收,而这个回收是以RealConnection的弱引用
List<Reference<StreamAllocation>>是否为0来为依据的。ConnectionPool有一个独立的线程
cleanupRunnable来清理连接池,其触发时机有两个:
当连接池中put新的连接时
当connectionBecameIdle接口被调用时
其代码如下:
while (true) {
//执行清理并返回下场需要清理的时间
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -1) return;
if (waitNanos > 0) {
synchronized (ConnectionPool.this) {
try {
//在timeout内释放锁与时间片
ConnectionPool.this.wait(TimeUnit.NANOSECONDS.toMillis(waitNanos));
} catch (InterruptedException ignored) {
}
}
}
}这段死循环实际上是一个阻塞的清理任务,首先进行清理(clean),并返回下次需要清理的间隔时间,然后调用
wait(timeout)进行等待以释放锁与时间片,当等待时间到了后,再次进行清理,并返回下次要清理的间隔时间…
接下来看下cleanup函数:
[ConnectionPool.java]
long cleanup(long now) {
int inUseConnectionCount = 0;
int idleConnectionCount = 0;
RealConnection longestIdleConnection = null;
long longestIdleDurationNs = Long.MIN_VALUE;
//遍历`Deque`中所有的`RealConnection`,标记泄漏的连接
synchronized (this) {
for (RealConnection connection : connections) {
// 查询此连接内部StreamAllocation的引用数量
if (pruneAndGetAllocationCount(connection, now) > 0) {
inUseConnectionCount++;
continue;
}
idleConnectionCount++;
//选择排序法,标记出空闲连接
long idleDurationNs = now - connection.idleAtNanos;
if (idleDurationNs > longestIdleDurationNs) {
longestIdleDurationNs = idleDurationNs;
longestIdleConnection = connection;
}
}
if (longestIdleDurationNs >= this.keepAliveDurationNs
|| idleConnectionCount > this.maxIdleConnections) {
//如果(`空闲socket连接超过5个`
//且`keepalive时间大于5分钟`)
//就将此泄漏连接从`Deque`中移除
connections.remove(longestIdleConnection);
} else if (idleConnectionCount > 0) {
//返回此连接即将到期的时间,供下次清理
//这里依据是在上文`connectionBecameIdle`中设定的计时
return keepAliveDurationNs - longestIdleDurationNs;
} else if (inUseConnectionCount > 0) {
//全部都是活跃的连接,5分钟后再次清理
return keepAliveDurationNs;
} else {
//没有任何连接,跳出循环
cleanupRunning = false;
return -1;
}
}
//关闭连接,返回`0`,也就是立刻再次清理
closeQuietly(longestIdleConnection.socket());
return 0;
}其基本逻辑如下:
遍历连接池中所有连接,标记泄露连接
如果被标记的连接满足(
空闲socket连接超过5个&&
keepalive时间大于5分钟),就将此连接从
Deque中移除,并关闭连接,返回
0,也就是将要执行
wait(0),提醒立刻再次扫描
如果(
目前还可以塞得下5个连接,但是有可能泄漏的连接(即空闲时间即将达到5分钟)),就返回此连接即将到期的剩余时间,供下次清理
如果(
全部都是活跃的连接),就返回默认的
keep-alive时间,也就是5分钟后再执行清理
而
pruneAndGetAllocationCount负责标记并找到不活跃连接:
[ConnnecitonPool.java]
//类似于引用计数法,如果引用全部为空,返回立刻清理
private int pruneAndGetAllocationCount(RealConnection connection, long now) {
//虚引用列表
List<Reference<StreamAllocation>> references = connection.allocations;
//遍历弱引用列表
for (int i = 0; i < references.size(); ) {
Reference<StreamAllocation> reference = references.get(i);
//如果正在被使用,跳过,接着循环
//是否置空是在上文`connectionBecameIdle`的`release`控制的
if (reference.get() != null) {
//非常明显的引用计数
i++;
continue;
}
//否则移除引用
references.remove(i);
connection.noNewStreams = true;
//如果所有分配的流均没了,标记为已经距离现在空闲了5分钟
if (references.isEmpty()) {
connection.idleAtNanos = now - keepAliveDurationNs;
return 0;
}
}
return references.size();
}OkHttp的连接池通过计数+标记清理的机制来管理连接池,使得无用连接可以被会回收,并保持多个健康的keep-alive连接。这也是OkHttp的连接池能保持高效的关键原因。

相关文章推荐
- OkHttp 3.7源码分析(五)——连接池
- OkHttp 3.7源码分析(五)——连接池
- OkHttp 3.7源码分析(三)——任务队列
- OkHttp 3.7源码分析(二)——拦截器&一个实际网络请求的实现
- OkHttp 3.7源码分析(一)——整体架构
- OkHttp 3.7源码分析(四)——缓存策略
- OkHttp 3.7源码分析(二)——拦截器&一个实际网络请求的实现
- OkHttp 3.7源码分析(三)——任务队列
- OkHttp3源码分析[复用连接池]
- Okhttp源码分析(五)连接池
- OkHttp 3.7源码分析(三)——任务队列
- OkHttp 3.7源码分析(一)——整体架构
- OkHttp 3.7源码分析(四)——缓存策略
- OkHttp3源码分析[复用连接池]
- OkHttp 3.7源码分析(四)——缓存策略
- OkHttp 3.7源码分析(二)——拦截器&一个实际网络请求的实现
- OkHttp 3.7源码分析(五)——连接池
- OkHttp 3.7源码分析(一)——整体架构
- OkHttp 3.7源码分析(三) - 任务队列
- OkHttp 3.7源码分析(二)——拦截器&一个实际网络请求的实现