(一)Redis笔记——简介 、key 、数据类型
2017-05-20 09:27
726 查看
1. Redis是什么、特点、优势
Redis是一个开源的使用C语言编写、开源、支持网络、可基于内存亦可持久化的日志型、高性能的Key-Value数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String)、哈希(Map)、 列表(list)、集合(sets) 和 有序集合(sorted sets)等类型。
Redis 与其他 key - value 缓存产品有以下三个特点:
Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
Redis支持数据的备份,即master-slave模式的数据备份。
Redis优势
性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
2. Redis 的启动与退出
redis命令不区分大小写,所以get var和GET var是等价的
4. Redis数据类型
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
string是最简单的类型,你可以理解成与Memcached一模一个的类型,一个key对应一个value,其上支持的操作与Memcached的操作类似。但它的功能更丰富。
Hash数据类型允许用户用Redis存储对象类型,Hash数据类型的一个重要优点是,当你存储的数据对象只有很少几个key值时,数据存储的内存消耗会很小.
list是一个链表结构,主要功能是push、pop、获取一个范围的所有值等等。操作中key理解为链表的名字。
set是集合,和我们数学中的集合概念相似,对集合的操作有添加删除元素,有对多个集合求交并差等操作。操作中key理解为集合的名字。
zset是set的一个升级版本,他在set的基础上增加了一个顺序属性,这一属性在添加修改元素的时候可以指定,每次指定后,zset会自动重新按新的值调整顺序。可以理解了有两列的mysql表,一列存value,一列存顺序。操作中key理解为zset的名字。
4.1 String(字符串)
是Redis最基本的数据类型,可以理解成与Memcached一模一样的类型,一个key对应一个value
二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象
一个键最大能存储512MB
利用set给变量var赋值“String type”;利用get获得变量var的值
4.2 Hash(哈希)
是一个键值对集合
是一个string类型的field和value的映射表,hash特别适合用于存储对象
hset,hget例子
hset&hget一次只能往哈希结构里面插入一个键值对,如果插入多个可以用hmset&hmget
hmset, hmget例子
4.3 List(列表)
lpush往列表的前边插入;lrange后面的数字是范围(闭区间)
列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)。
Redis Lrange 返回列表中指定区间内的元素,区间以偏移量 START 和 END 指定。 其中 0 表示列表的第一个元素, 1 表示列表的第二个元素,以此类推。 你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
4.4 Set(集合)
Redis的Set是string类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)
set往集合中插入元素,smembers列举出集合中的元素
成功插入返回1;错误插入返回0,例子中 two 第二次插入时,因已经存在,故插入失败。
4.5 zset(sorted sete:有序集合)
zset和set一样也是String类型的集合,且不允许元素重复 , 用于将一个或多个成员元素及其分数值加入到有序集当中。
如果某个成员已经是有序集的成员,那么更新这个成员的分数值,并通过重新插入这个成员元素,来保证该成员在正确的位置上。
zset和set不同的地方在于zset关联一个double类型的分数,redis通过分数对集合中的元素排序
zset的元素是唯一的,但是分数是可以重复的
成功插入返回1,否则返回0。插入已存在元素失败--返回0
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
注:因为HyperLogLog只会根据输入元素来计算基数,而不会存储输入元素本身,因此不会返回输入的各个元素。
基数是什么?比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
Redis是一个开源的使用C语言编写、开源、支持网络、可基于内存亦可持久化的日志型、高性能的Key-Value数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String)、哈希(Map)、 列表(list)、集合(sets) 和 有序集合(sorted sets)等类型。
Redis 与其他 key - value 缓存产品有以下三个特点:
Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
Redis支持数据的备份,即master-slave模式的数据备份。
Redis优势
性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
2. Redis 的启动与退出
[root@centoszang 桌面]# redis-cli Could not connect to Redis at 127.0.0.1:6379: Connection refused Could not connect to Redis at 127.0.0.1:6379: Connection refused not connected> exit [root@centoszang 桌面]# redis-server /etc/redis.conf [root@centoszang 桌面]# redis-cli 127.0.0.1:6379>
[root@centoszang 桌面]# redis-cli 127.0.0.1:6379> ping PONG 127.0.0.1:6379> set var helloWorld OK 127.0.0.1:6379> get var "helloWorld" 127.0.0.1:6379> del var (integer) 1 127.0.0.1:6379> get var (nil) 127.0.0.1:6379> quit [root@centoszang 桌面]#
redis命令不区分大小写,所以get var和GET var是等价的
3. Redis key
Redis是key-value的数据库,Redis的键用于管理Redis的键。主要命令如下:| 序号 | Redis keys命令及描述 |
|---|---|
| 1 | DEL key 该命令用于在 key 存在是删除 key。 |
| 2 | DUMP key 序列化给定 key ,并返回被序列化的值。 |
| 3 | EXISTS key 检查给定 key 是否存在。 |
| 4 | EXPIRE key seconds 为给定 key 设置过期时间。 |
| 5 | EXPIREAT key timestamp EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。 不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳(unix timestamp)。 |
| 6 | PEXPIRE key milliseconds 设置 key 的过期时间亿以毫秒计。 |
| 7 | PEXPIREAT key milliseconds-timestamp 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计 |
| 8 | KEYS pattern 查找所有符合给定模式( pattern)的 key 。例如keys * 返回所有的key |
| 9 | MOVE key db 将当前数据库的 key 移动到给定的数据库 db 当中。 |
| 10 | PERSIST key 移除 key 的过期时间,key 将持久保持。 |
| 11 | PTTL key 以毫秒为单位返回 key 的剩余的过期时间。 |
| 12 | TTL key 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。 |
| 13 | RANDOMKEY 从当前数据库中随机返回一个 key 。 |
| 14 | RENAME key newkey 修改 key 的名称 |
| 15 | RENAMENX key newkey 仅当 newkey 不存在时,将 key 改名为 newkey 。 |
| 16 | TYPE key 返回 key 所储存的值的类型。 |
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
string是最简单的类型,你可以理解成与Memcached一模一个的类型,一个key对应一个value,其上支持的操作与Memcached的操作类似。但它的功能更丰富。
Hash数据类型允许用户用Redis存储对象类型,Hash数据类型的一个重要优点是,当你存储的数据对象只有很少几个key值时,数据存储的内存消耗会很小.
list是一个链表结构,主要功能是push、pop、获取一个范围的所有值等等。操作中key理解为链表的名字。
set是集合,和我们数学中的集合概念相似,对集合的操作有添加删除元素,有对多个集合求交并差等操作。操作中key理解为集合的名字。
zset是set的一个升级版本,他在set的基础上增加了一个顺序属性,这一属性在添加修改元素的时候可以指定,每次指定后,zset会自动重新按新的值调整顺序。可以理解了有两列的mysql表,一列存value,一列存顺序。操作中key理解为zset的名字。
4.1 String(字符串)
是Redis最基本的数据类型,可以理解成与Memcached一模一样的类型,一个key对应一个value
二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象
一个键最大能存储512MB
利用set给变量var赋值“String type”;利用get获得变量var的值
127.0.0.1:6379> set var1 "xiaofeng" OK 127.0.0.1:6379> get var1 "xiaofeng"
4.2 Hash(哈希)
是一个键值对集合
是一个string类型的field和value的映射表,hash特别适合用于存储对象
hset,hget例子
127.0.0.1:6379> hset hash1 name "xiaoming" (integer) 1 127.0.0.1:6379> hset hash1 rank "first" (integer) 1 127.0.0.1:6379> hset hash2 name "dahuang" (integer) 1 127.0.0.1:6379> hset hash2 rank "second" (integer) 1 127.0.0.1:6379> hget hash1 rank "first"
hset&hget一次只能往哈希结构里面插入一个键值对,如果插入多个可以用hmset&hmget
hmset, hmget例子
127.0.0.1:6379> hmset hash3 name "fengge" rank "third" OK 127.0.0.1:6379> hmget hash3 (error) ERR wrong number of arguments for 'hmget' command 127.0.0.1:6379> hmget hash3 name 1) "fengge" 127.0.0.1:6379> hgetall hash3 1) "name" 2) "fengge" 3) "rank" 4) "third"
4.3 List(列表)
lpush往列表的前边插入;lrange后面的数字是范围(闭区间)
列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)。
127.0.0.1:6379> lpush list1 one (integer) 1 127.0.0.1:6379> lpush list1 two (integer) 2 127.0.0.1:6379> lpush list1 three (integer) 3 127.0.0.1:6379> lrange list1 (error) ERR wrong number of arguments for 'lrange' command 127.0.0.1:6379> lrange list1 0 10 1) "three" 2) "two" 3) "one"
redis 127.0.0.1:6379> LRANGE KEY_NAME START END
Redis Lrange 返回列表中指定区间内的元素,区间以偏移量 START 和 END 指定。 其中 0 表示列表的第一个元素, 1 表示列表的第二个元素,以此类推。 你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
4.4 Set(集合)
Redis的Set是string类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)
set往集合中插入元素,smembers列举出集合中的元素
成功插入返回1;错误插入返回0,例子中 two 第二次插入时,因已经存在,故插入失败。
127.0.0.1:6379> sadd set1 one (integer) 1 127.0.0.1:6379> sadd set1 two (integer) 1 127.0.0.1:6379> sadd set1 two (integer) 0 127.0.0.1:6379> sadd set1 three (integer) 1 127.0.0.1:6379> SMEMBERS set1 1) "two" 2) "three" 3) "one"
4.5 zset(sorted sete:有序集合)
zset和set一样也是String类型的集合,且不允许元素重复 , 用于将一个或多个成员元素及其分数值加入到有序集当中。
如果某个成员已经是有序集的成员,那么更新这个成员的分数值,并通过重新插入这个成员元素,来保证该成员在正确的位置上。
zset和set不同的地方在于zset关联一个double类型的分数,redis通过分数对集合中的元素排序
zset的元素是唯一的,但是分数是可以重复的
127.0.0.1:6379> zadd zset1 1 one (integer) 1 127.0.0.1:6379> zadd zset1 2 two (integer) 1 127.0.0.1:6379> zadd zset1 3 three (integer) 1 127.0.0.1:6379> zadd zset1 3 three (integer) 0 127.0.0.1:6379> zadd zset1 4 three (integer) 0 127.0.0.1:6379> ZRANGE zset1 0 10 1) "one" 2) "two" 3) "three"
127.0.0.1:6379> zadd zset1 3 ttt (integer) 1 127.0.0.1:6379> ZRANGE zset1 0 10 1) "one" 2) "two" 3) "ttt" 4) "three"
成功插入返回1,否则返回0。插入已存在元素失败--返回0
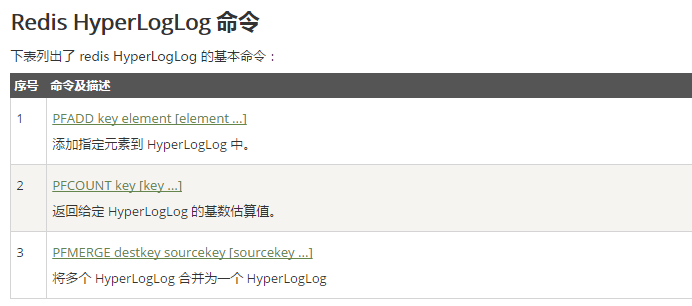
5. Redis HyperLogLog
Redis HyperLogLog是用来做基数统计的算法。优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
注:因为HyperLogLog只会根据输入元素来计算基数,而不会存储输入元素本身,因此不会返回输入的各个元素。
基数是什么?比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
127.0.0.1:6379> pfadd zang money (integer) 1 127.0.0.1:6379> pfadd zang health (integer) 1 127.0.0.1:6379> pfadd zang handsome (integer) 1 127.0.0.1:6379> pfadd zang clever (integer) 1 127.0.0.1:6379> PFCOUNT zang (integer) 4
127.0.0.1:6379> pfadd key1 a b c d (integer) 1 127.0.0.1:6379> pfadd key2 a e f d (integer) 1 127.0.0.1:6379> PFMERGE key3 key1 key2 OK 127.0.0.1:6379> PFCOUNT key3 (integer) 6

相关文章推荐
- Redis笔记(二) - key关键字和Redis五个数据类型
- Redis简介、与memcached比较、存储方式、应用场景、生产经验教训、安全设置、key的建议、安装和常用数据类型介绍、ServiceStack.Redis使用(1)
- Redis学习笔记五、Key数据类型
- 虚拟机安装redis 以及 redis五种数据类型 key命令(过期时间) redis持久化方案 教科书笔记
- Redis笔记(二) - key关键字和Redis五个数据类型
- MySQL基础笔记(一) SQL简介+数据类型
- Redis-HelloWorld与五大基本数据类型(笔记)
- Redis和nosql简介,api调用;Redis数据功能(String类型的数据处理);List数据结构(及Java调用处理);Hash数据结构;Set数据结构功能;sortedSet(有序集合)数
- redis学习笔记二之数据类型
- NoSQL初探之人人都爱Redis:(2)Redis API与常用数据类型简介
- Redis笔记(二):Redis数据类型
- Redis基础学习--安装、简介、基本数据类型及相应命令
- Redis是一种面向“key-value”类型数据的分布式NoSQL数据库系统,具有高性能、持久存储、适应高并发应用场景等优势。它虽然起步较晚,但发展却十分迅速。
- 二 redis学习笔记之数据类型
- redis五种数据类型学习笔记
- Redis学习笔记---数据类型二(set、sortedset)
- Redis和nosql简介,api调用;Redis数据功能(String类型的数据处理);List数据结构(及Java调用处理);Hash数据结构;Set数据结构功能;sortedSet(有序集合)数
- Redis简介(二)数据类型
- Swift学习笔记一:简介和数据类型
- redis学习笔记之数据类型