Redis_cluster 集群
2017-05-10 10:53
288 查看
Redis cluster 集群 Redis-Cluster 在设计的时候,就考虑到了去中心化,去中间件,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。所以我们在测试的时候看到set 和 get 的时候,直接跳转到了默认第一个配置启动的节点。
Redis 集群会把数据存在一个 master 节点,然后在这个 master 和其对应的salve 之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的 master 节点获取数据。只有当一个master 挂掉之后,才会启动一个对应的 salve 节点,充当 master 。
需要注意的是:Redis集群至少3+3,是还延续着Master-Slave的设计理念;
一、安装依赖
yum -y install gcc gcc-c++ tcl ruby ruby-devel rubygems rpm-build
安装完Redis再执行:gem install redis
二、redis配置实例
conf目录:redis_cluster
data目录: data
logs目录:logs
端口实例;6001 6001 6002 6003 6004 6005 6006
# cat redis.conf
bind 10.10.101.100
protected-mode yes
port 6379
# 端口配置6379
tcp-backlog 511
timeout 0
tcp-keepalive 300
daemonize yes
# redis后台运行
cluster-enabled yes
# 开启集群
cluster-config-file nodes_6379.conf
集群配置 首次启动生成
cluster-node-timeout 5000
# 请求超时
appendonly yes
# aof 日志开启
supervised no
pidfile /var/run/redis_6379.pid
loglevel notice
logfile /opt/redis/logs/6379/redis.log
# 日志目录
databases 16
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir /opt/redis/data/6379
slave-serve-stale-data yes
slave-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
slave-priority 100
appendfilename "appendonly.6379.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes
三、启动
src/redis-server redis_cluster/6001/redis.conf
src/redis-server redis_cluster/6002/redis.conf
src/redis-server redis_cluster/6003/redis.conf
src/redis-server redis_cluster/6004/redis.conf
src/redis-server redis_cluster/6005/redis.conf
src/redis-server redis_cluster/6006/redis.conf
四、集群操作
通过使用 Redis 集群命令行工具 redis-trib , 编写节点配置文件的工作可以非常容易地完成: redis-trib 位于 Redis 源码的 src 文件夹中, 它是一个 Ruby 程序, 这个程序通过向实例发送特殊命令来完成创建新集群, 检查集群, 或者对集群进行重新分片(reshared)等工作。
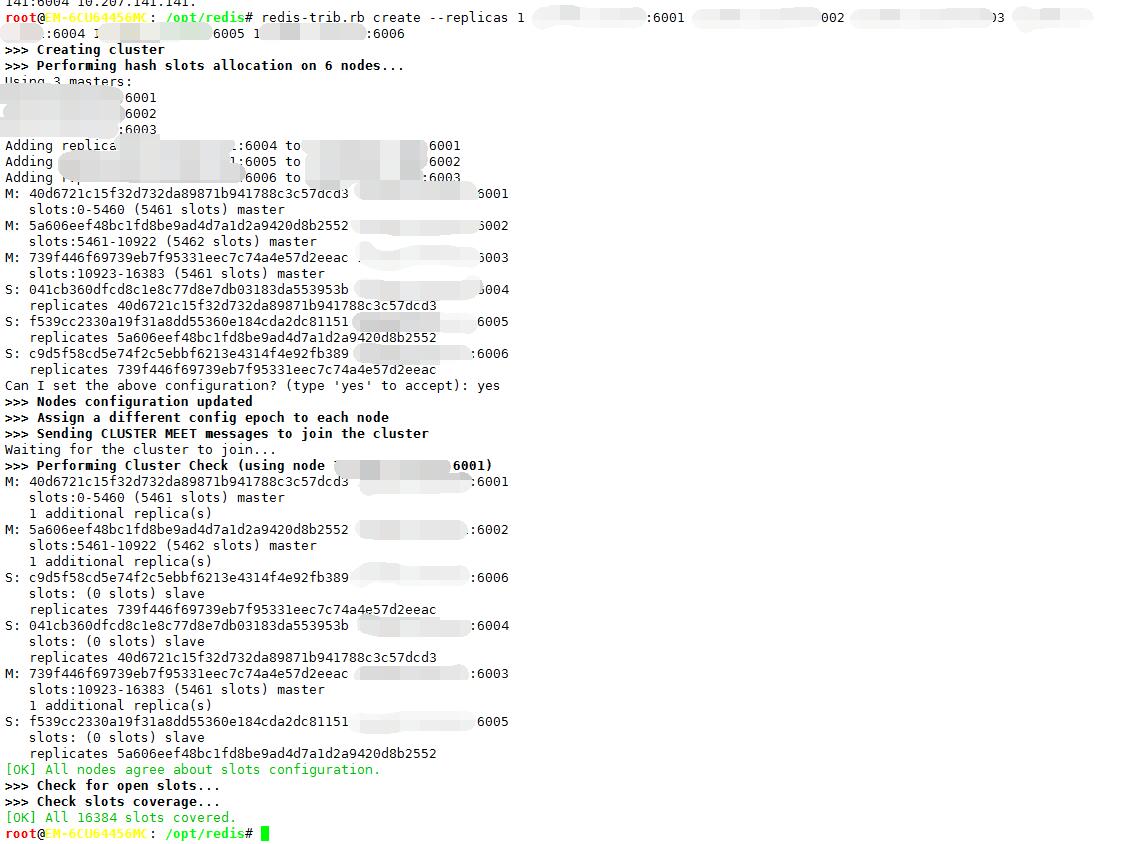
1、创建一个集群
redis-trib.rb create --replicas 1 10.10.101.100:6001 10.10.101.100:6002 10.10.101.100:6003 10.10.101.100:6004 10.10.101.100:6005 10.10.101.100:6006
// --replicas 1 表示 为集群中的每个主节点创建一个从节点。
2、集群重新分片
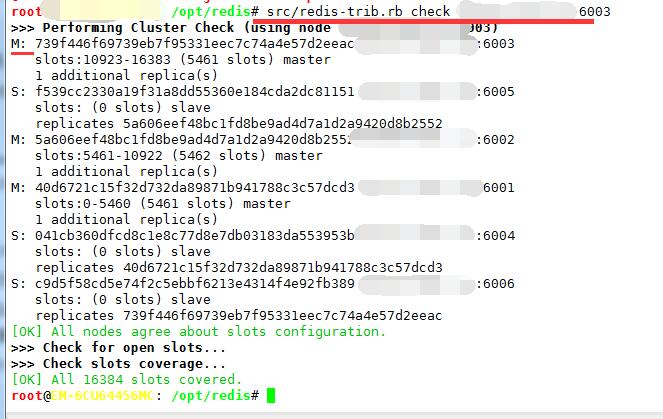
./redis-trib.rb reshard 10.10.101.100:6003
// 需要指定移动哈希槽数 ( 1 - 16383 ) 和目标节点 ID
# src/redis-cli -h 10.10.101.100 -p 6003 cluster nodes | grep myself
root@redis: /opt/redis# redis-cli -h 10.10.101.100 -p 6003 cluster nodes | grep myself
739f446f69739eb7f95331eec7c74a4e57d2eeac 10.10.101.100:6003 myself,master - 0 0 3 connected 10923-16383
3、添加一个新节点
添加新的节点的基本过程就是添加一个空的节点然后移动一些数据给它,有两种情况,添加一个主节点和添加一个从节点(添加从节点时需要将这个新的节点设置为集群中某个节点的复制).
两种情况第一步都是要添加一个空的节点.
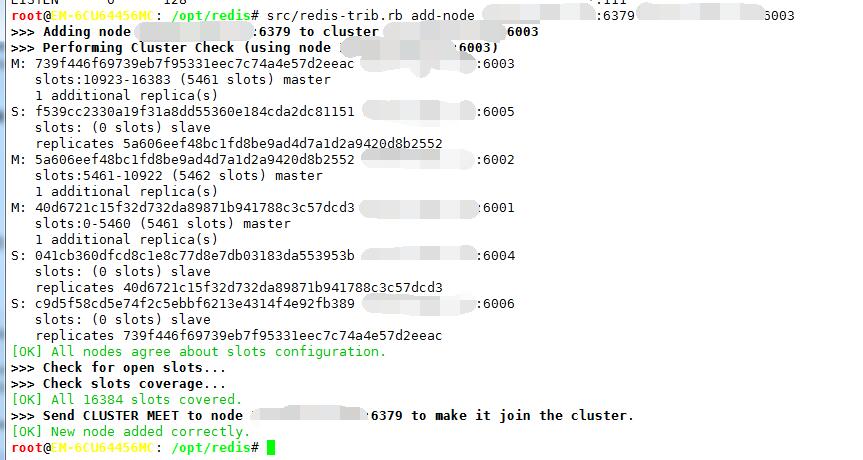
A、添加一个节点到现有的集群中去../redis-trib.rb add-node 10.10.101.100:6379 10.10.101.100:6003
// 使用addnode命令来添加节点,第一个参数是新节点的地址,第二个参数是任意一个已经存在的节点的IP和端口.
root@redis: /opt/redis# src/redis-cli -c -h 10.10.101.100 -p 6379
10.10.101.100:6379> cluster nodes
0d9cb75cf92ce44dc3a4ad48bd95b48fc0d7a5ca 10.10.101.100:6379 myself,master - 0 0 0 connected
40d6721c15f32d732da89871b941788c3c57dcd3 10.10.101.100:6001 master - 0 1494413014845 1 connected 0-5460
041cb360dfcd8c1e8c77d8e7db03183da553953b 10.10.101.100:6004 slave 40d6721c15f32d732da89871b941788c3c57dcd3 0 1494413014344 1 connected
c9d5f58cd5e74f2c5ebbf6213e4314f4e92fb389 10.10.101.100:6006 slave 739f446f69739eb7f95331eec7c74a4e57d2eeac 0 1494413014644 3 connected
5a606eef48bc1fd8be9ad4d7a1d2a9420d8b2552 10.10.101.100:6002 master - 0 1494413015845 2 connected 5461-10922
f539cc2330a19f31a8dd55360e184cda2dc81151 10.10.101.100:6005 slave 5a606eef48bc1fd8be9ad4d7a1d2a9420d8b2552 0 1494413015345 2 connected
739f446f69739eb7f95331eec7c74a4e57d2eeac 10.10.101.100:6003 master - 0 1494413016345 3 connected 10923-16383
10.10.101.100:6379>
// 新节点没有包含任何数据, 因为它没有包含任何哈希槽.

尽管新节点没有包含任何哈希槽, 但它仍然是一个主节点, 所以在集群需要将某个从节点升级为新的主节点时, 这个新节点不会被选中。只要将集群中的某些哈希桶移动到新节点里面, 新节点就会成为真正的主节点了。
4、添加一个从节点
有两种方法添加从节点,可以像添加主节点一样使用redis-trib 命令,也可以像下面的例子一样使用 –slave选项:
src/redis-trib.rb add-node --slave 10.10.101.100:6379 10.10.101.100:6001
// 此处并没有指定添加的这个从节点的主节点,这种情况下系统会在其他的复制集中的主节点中随机选取一个作为这个从节点的主节点。
a、指定主节点添加:
src/redis-trib.rb add-node --slave --master-id 739f446f69739eb7f95331eec7c74a4e57d2eeac 10.10.101.100:6379 10.10.101.100:6001
b、给主节点 10.10.101.100:6003添加一个从节点,该节点哈希槽的范围10923-16383
节点 ID 739f446f69739eb7f95331eec7c74a4e57d2eeac,我们需要链接新的节点(已经是空的主节点)并执行命令:
redis 10.10.101.100:6379> cluster replicate 739f446f69739eb7f95331eec7c74a4e57d2eeac
c、验证下集群节点
$ redis-cli -p 6379 cluster nodes | grep slave | grep 739f446f69739eb7f95331eec7c74a4e57d2eeac
f093c80dde814da99c5cf72a7dd01590792b783b 10.10.101.100:6379 slave 739f446f69739eb7f95331eec7c74a4e57d2eeac 0 1385543617702 3 connected
041cb360dfcd8c1e8c77d8e7db03183da553953b 10.10.101.100:6004 slave 40d6721c15f32d732da89871b941788c3c57dcd3 0 1494413014344 1 connected
// 节点 739f446f69739eb7f95331eec7c74a4e57d2eeac 有两个从节点, 6004 (已经存在的) 和 6379 (新添加的).
5、移除一个节点
只要使用 del-node 命令即可:
src/redis-trib del-node 10.10.101.100:6001 `<node-id>`
// 第一个参数是任意一个节点的地址,第二个节点是你想要移除的节点地址。
使用同样的方法移除主节点,不过在移除主节点前,需要确保这个主节点是空的. 如果不是空的,需要将这个节点的数据重新分片到其他主节点上.
替代移除主节点的方法是手动执行故障恢复,被移除的主节点会作为一个从节点存在,不过这种情况下不会减少集群节点的数量,也需要重新分片数据.
6、从节点的迁移
在Redis集群中会存在改变一个从节点的主节点的情况,需要执行如下命令 :
CLUSTER REPLICATE <master-node-id>
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。所以我们在测试的时候看到set 和 get 的时候,直接跳转到了默认第一个配置启动的节点。
Redis 集群会把数据存在一个 master 节点,然后在这个 master 和其对应的salve 之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的 master 节点获取数据。只有当一个master 挂掉之后,才会启动一个对应的 salve 节点,充当 master 。
需要注意的是:Redis集群至少3+3,是还延续着Master-Slave的设计理念;
一、安装依赖
yum -y install gcc gcc-c++ tcl ruby ruby-devel rubygems rpm-build
安装完Redis再执行:gem install redis
二、redis配置实例
conf目录:redis_cluster
data目录: data
logs目录:logs
端口实例;6001 6001 6002 6003 6004 6005 6006
# cat redis.conf
bind 10.10.101.100
protected-mode yes
port 6379
# 端口配置6379
tcp-backlog 511
timeout 0
tcp-keepalive 300
daemonize yes
# redis后台运行
cluster-enabled yes
# 开启集群
cluster-config-file nodes_6379.conf
集群配置 首次启动生成
cluster-node-timeout 5000
# 请求超时
appendonly yes
# aof 日志开启
supervised no
pidfile /var/run/redis_6379.pid
loglevel notice
logfile /opt/redis/logs/6379/redis.log
# 日志目录
databases 16
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir /opt/redis/data/6379
slave-serve-stale-data yes
slave-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
slave-priority 100
appendfilename "appendonly.6379.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes
三、启动
src/redis-server redis_cluster/6001/redis.conf
src/redis-server redis_cluster/6002/redis.conf
src/redis-server redis_cluster/6003/redis.conf
src/redis-server redis_cluster/6004/redis.conf
src/redis-server redis_cluster/6005/redis.conf
src/redis-server redis_cluster/6006/redis.conf
四、集群操作
通过使用 Redis 集群命令行工具 redis-trib , 编写节点配置文件的工作可以非常容易地完成: redis-trib 位于 Redis 源码的 src 文件夹中, 它是一个 Ruby 程序, 这个程序通过向实例发送特殊命令来完成创建新集群, 检查集群, 或者对集群进行重新分片(reshared)等工作。
1、创建一个集群
redis-trib.rb create --replicas 1 10.10.101.100:6001 10.10.101.100:6002 10.10.101.100:6003 10.10.101.100:6004 10.10.101.100:6005 10.10.101.100:6006
// --replicas 1 表示 为集群中的每个主节点创建一个从节点。
2、集群重新分片
./redis-trib.rb reshard 10.10.101.100:6003
// 需要指定移动哈希槽数 ( 1 - 16383 ) 和目标节点 ID
# src/redis-cli -h 10.10.101.100 -p 6003 cluster nodes | grep myself
root@redis: /opt/redis# redis-cli -h 10.10.101.100 -p 6003 cluster nodes | grep myself
739f446f69739eb7f95331eec7c74a4e57d2eeac 10.10.101.100:6003 myself,master - 0 0 3 connected 10923-16383
3、添加一个新节点
添加新的节点的基本过程就是添加一个空的节点然后移动一些数据给它,有两种情况,添加一个主节点和添加一个从节点(添加从节点时需要将这个新的节点设置为集群中某个节点的复制).
两种情况第一步都是要添加一个空的节点.
A、添加一个节点到现有的集群中去../redis-trib.rb add-node 10.10.101.100:6379 10.10.101.100:6003
// 使用addnode命令来添加节点,第一个参数是新节点的地址,第二个参数是任意一个已经存在的节点的IP和端口.
root@redis: /opt/redis# src/redis-cli -c -h 10.10.101.100 -p 6379
10.10.101.100:6379> cluster nodes
0d9cb75cf92ce44dc3a4ad48bd95b48fc0d7a5ca 10.10.101.100:6379 myself,master - 0 0 0 connected
40d6721c15f32d732da89871b941788c3c57dcd3 10.10.101.100:6001 master - 0 1494413014845 1 connected 0-5460
041cb360dfcd8c1e8c77d8e7db03183da553953b 10.10.101.100:6004 slave 40d6721c15f32d732da89871b941788c3c57dcd3 0 1494413014344 1 connected
c9d5f58cd5e74f2c5ebbf6213e4314f4e92fb389 10.10.101.100:6006 slave 739f446f69739eb7f95331eec7c74a4e57d2eeac 0 1494413014644 3 connected
5a606eef48bc1fd8be9ad4d7a1d2a9420d8b2552 10.10.101.100:6002 master - 0 1494413015845 2 connected 5461-10922
f539cc2330a19f31a8dd55360e184cda2dc81151 10.10.101.100:6005 slave 5a606eef48bc1fd8be9ad4d7a1d2a9420d8b2552 0 1494413015345 2 connected
739f446f69739eb7f95331eec7c74a4e57d2eeac 10.10.101.100:6003 master - 0 1494413016345 3 connected 10923-16383
10.10.101.100:6379>
// 新节点没有包含任何数据, 因为它没有包含任何哈希槽.
尽管新节点没有包含任何哈希槽, 但它仍然是一个主节点, 所以在集群需要将某个从节点升级为新的主节点时, 这个新节点不会被选中。只要将集群中的某些哈希桶移动到新节点里面, 新节点就会成为真正的主节点了。
4、添加一个从节点
有两种方法添加从节点,可以像添加主节点一样使用redis-trib 命令,也可以像下面的例子一样使用 –slave选项:
src/redis-trib.rb add-node --slave 10.10.101.100:6379 10.10.101.100:6001
// 此处并没有指定添加的这个从节点的主节点,这种情况下系统会在其他的复制集中的主节点中随机选取一个作为这个从节点的主节点。
a、指定主节点添加:
src/redis-trib.rb add-node --slave --master-id 739f446f69739eb7f95331eec7c74a4e57d2eeac 10.10.101.100:6379 10.10.101.100:6001
b、给主节点 10.10.101.100:6003添加一个从节点,该节点哈希槽的范围10923-16383
节点 ID 739f446f69739eb7f95331eec7c74a4e57d2eeac,我们需要链接新的节点(已经是空的主节点)并执行命令:
redis 10.10.101.100:6379> cluster replicate 739f446f69739eb7f95331eec7c74a4e57d2eeac
c、验证下集群节点
$ redis-cli -p 6379 cluster nodes | grep slave | grep 739f446f69739eb7f95331eec7c74a4e57d2eeac
f093c80dde814da99c5cf72a7dd01590792b783b 10.10.101.100:6379 slave 739f446f69739eb7f95331eec7c74a4e57d2eeac 0 1385543617702 3 connected
041cb360dfcd8c1e8c77d8e7db03183da553953b 10.10.101.100:6004 slave 40d6721c15f32d732da89871b941788c3c57dcd3 0 1494413014344 1 connected
// 节点 739f446f69739eb7f95331eec7c74a4e57d2eeac 有两个从节点, 6004 (已经存在的) 和 6379 (新添加的).
5、移除一个节点
只要使用 del-node 命令即可:
src/redis-trib del-node 10.10.101.100:6001 `<node-id>`
// 第一个参数是任意一个节点的地址,第二个节点是你想要移除的节点地址。
使用同样的方法移除主节点,不过在移除主节点前,需要确保这个主节点是空的. 如果不是空的,需要将这个节点的数据重新分片到其他主节点上.
替代移除主节点的方法是手动执行故障恢复,被移除的主节点会作为一个从节点存在,不过这种情况下不会减少集群节点的数量,也需要重新分片数据.
6、从节点的迁移
在Redis集群中会存在改变一个从节点的主节点的情况,需要执行如下命令 :
CLUSTER REPLICATE <master-node-id>

相关文章推荐
- Redis集群的方案总结:客户端Sharding/Redis Cluster/Proxy
- Redis-cluster集群【第三篇】:redis主从
- 分布式缓存集群方案特性使用场景(Memcache/Redis(Twemproxy/Codis/Redis-cluster))优缺点对比及选型
- redis集群 Waiting for the cluster to join 一直等待
- 分布式缓存集群方案特性使用场景(Memcache/Redis(Twemproxy/Codis/Redis-cluster))优缺点对比及选型
- 分布式缓存集群方案特性使用场景(Memcache/Redis(Twemproxy/Codis/Redis-cluster))优缺点对比及选型
- Redis-Cluster集群搭建及配置
- Redis3.0.7 cluster/集群 安装配置教程
- 【redis】 redis 创建集群时,Waiting for the cluster to join.... 一直等待
- Redis-3.2.0集群配置(redis cluster)
- Redis集群管理之Redis Cluster集群节点增减
- Redis进阶实践之十一 Redis的Cluster集群搭建
- 分布式Redis中集群中(cluster_state:fail),什么时候整个集群不可用了
- Redis 集群cluster
- 分布式缓存集群方案特性使用场景(Memcache/Redis(Twemproxy/Codis/Redis-cluster))优缺点对比及选型
- Redis学习笔记(五)jedis(JedisCluster)操作Redis集群 redis-cluster
- 在windows上搭建redis集群(redis-cluster)
- redis cluster window 集群管理
- 经验分享 |【PDF下载】运维/DevOps峰会之饿了么Redis Cluster集群演进
- redis-cluster集群模式下使用pipeline,mget,mset批量操作