程序员的编程语言迁移路线:Go语言是最大赢家,Java 还在,Perl 灭亡了,Rust 做的相当不错。
2017-05-09 12:01
1001 查看
原文:http://www.techug.com/post/the-eigenvector-of-why-we-moved-from-language-x-to-language-y.html
我看了一篇博客,标题是《为什么我们要从 X 语言转到 Y 语言》,具体是哪种编程语言,我忘了。于是我开始想,是不是可以把这些文章归纳起来,生成一个关于从 X 语言转到 Y 语言的 N*N 的联列表(contingency table)?
所以我写了个小脚本,可以用脚本在 Google 上查询,再加上一小段代码就能得到搜索结果的数目。我尝试了用几个不同的关键词来搜索,像“move from <language 1> to <language 2>”,“switch
to <language 2> from <language 1> ”等等。最终得到了一个所有语言的 N*N 的联列表。
本文图表尺寸很大,先来解释如何读图:
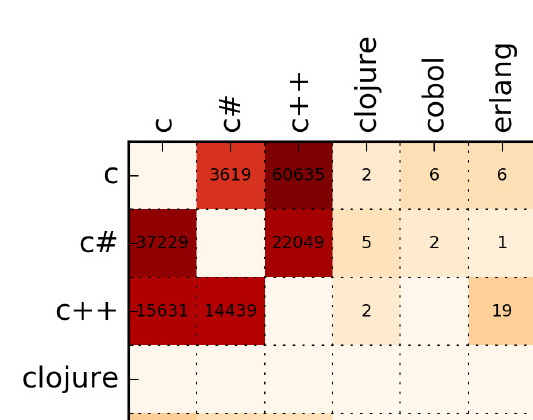
左侧纵向语言是「叛逃的源语言」;
上方横向的语言是「叛逃的目标语言」;
例如:从 C 语言转到 C# 的数量为 3619,从 C# 转到 C 的有 37229;
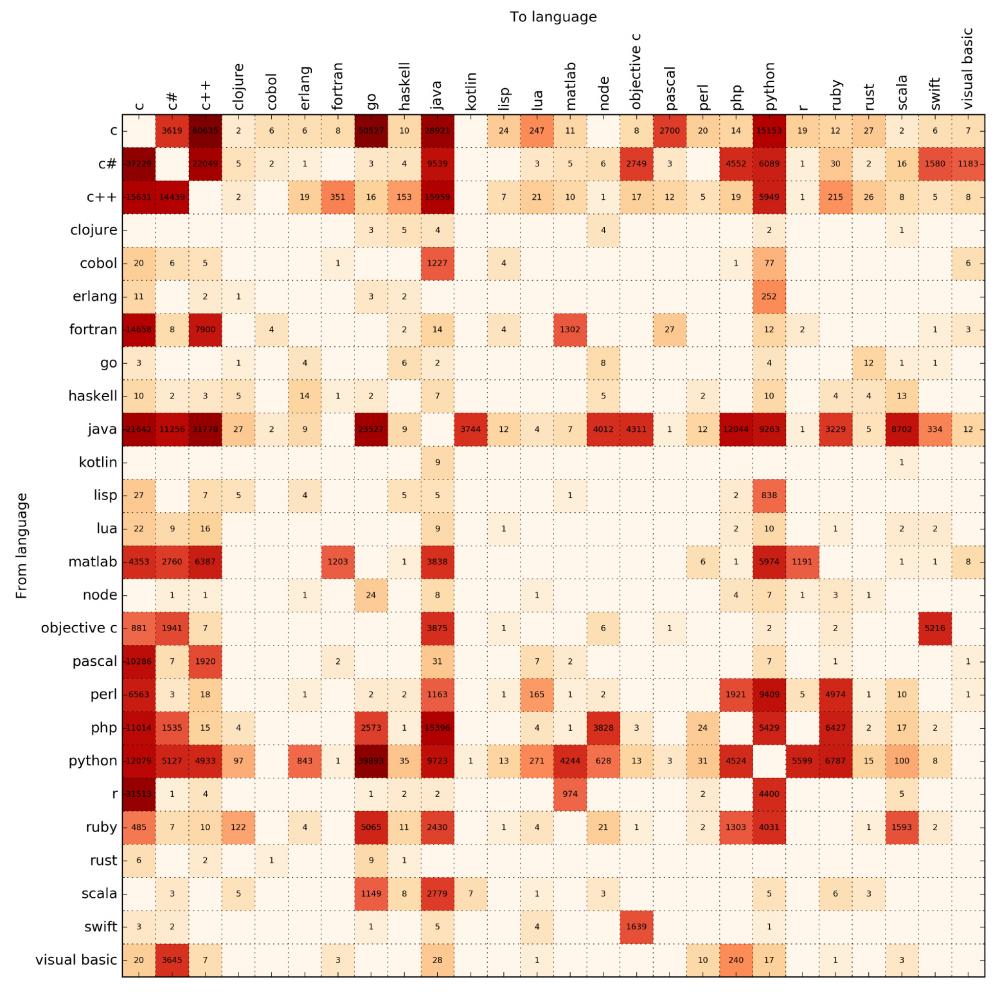
(点击查看大图)
有意思的部分来了。实际上我们可以把搜索结果数看作是编程语言之间转换的概率,从而得出一些关于未来编程语言的流行趋势的结论。一个关键点是,这个(编程语言转换过程)的平稳分布并不取决于它们的初始分布。事实证明,这只是矩阵的第一特征向量(first eigenvector)而已。所以没必要去假设现在哪种编程语言很流行,我们推测出的未来的平稳分布状态和初始状态是独立的。
我们需要把上述的联列表转化成转移矩阵(stochastic matrix)的形式,用来描述从状态
ii 到状态 jj 的概率。非常简单——想要把联列矩阵解释为转移概率的话,可以将联列矩阵的每一行正则化。这样就能得到从 X 语言到 Y 语言的粗略近似概率。
找出第一特征向量并不重要,我们只要把一个向量多次乘上这个转移矩阵,最终会向第一特征向量收敛。顺便说下,可以看看下面的注意事项,有关于我如何操作的更多讨论。
闲话少说,下表是平稳分布下排名前几的语言:
根据未来流行度,我把转移矩阵按照编程语言做了排序(根据第一特征向量所做的预测)
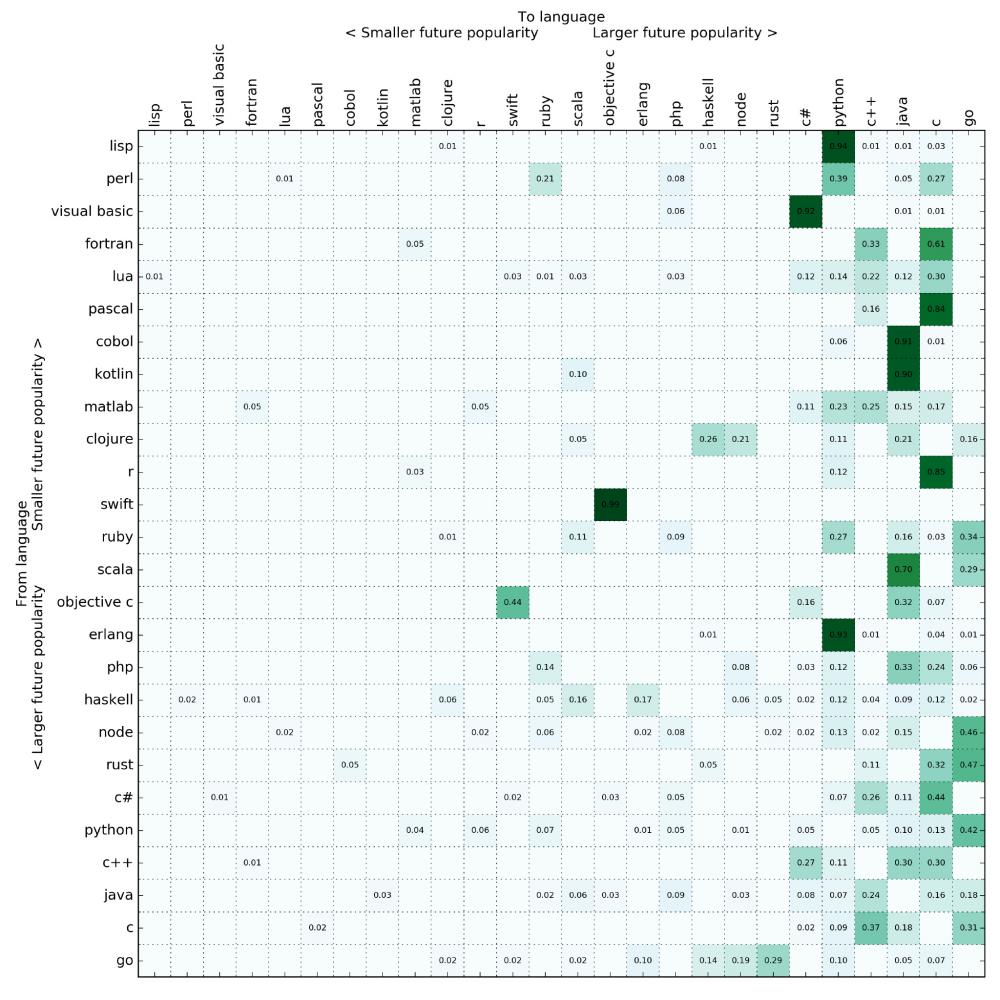
(点击查看大图)
令人惊讶的是(至少对我来说),Go 成为最大赢家。有超多的搜索结果显示大家由其他语言转向 Go。我都不能确定我对此是什么感受了(我对 Go 的感情很复杂)。但是我的绝对分析指出了一个必然结论,那就是 Go 值得关注。

C
语言到今年就有 45 岁了,仍然表现良好。我手动做了一些搜索,有很多都是人们真的在写他们通过从另一种编程语言迁移到 C,对特定的紧密循环(tight loops)做了优化。这个结果是错的吗?我不这么认为。C 语言是计算机工作的通用语言(lingua franca),如果人们还会积极地将其他语言的片段转换为 C 语言,那么这个结论也就可想而知了。说真的,我认为 C 语言会在它 100 岁生日,也就是 2072 年以前,变得更强大。有我在 LinkedIn 上对 C 的支持,我希望招聘人员能在 21 世纪 50
年代的时候给我一些关于 C 语言的工作机会(我收回上面那句话——希望 C 会比 LinkedIn 活得久)。
除了上面提到的以外,这些分析也很符合我的预期。Java
还在,Perl 灭亡了,Rust 做的相当不错。
顺便一提,这个分析让我想起了下面这条推
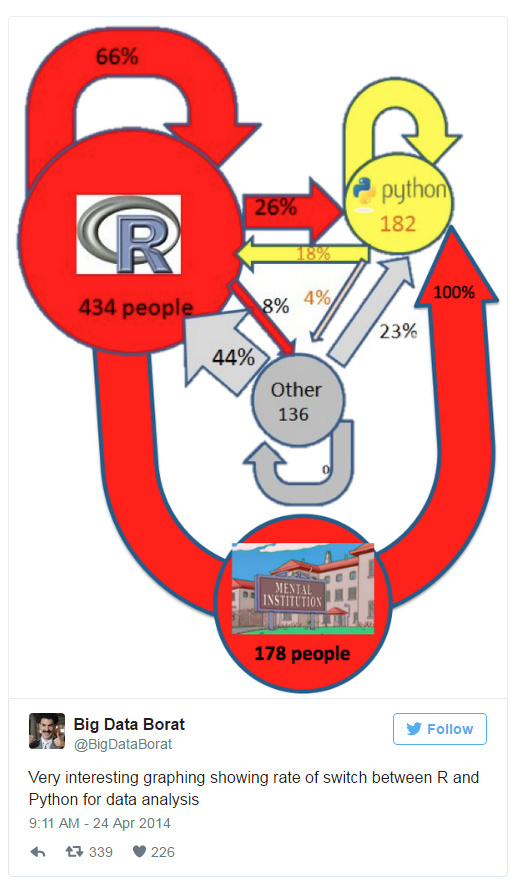
这图非常有意思,展示了在数据分析中 R 和 Python 之间的转化率。
我对前端框架也做了同样的分析:
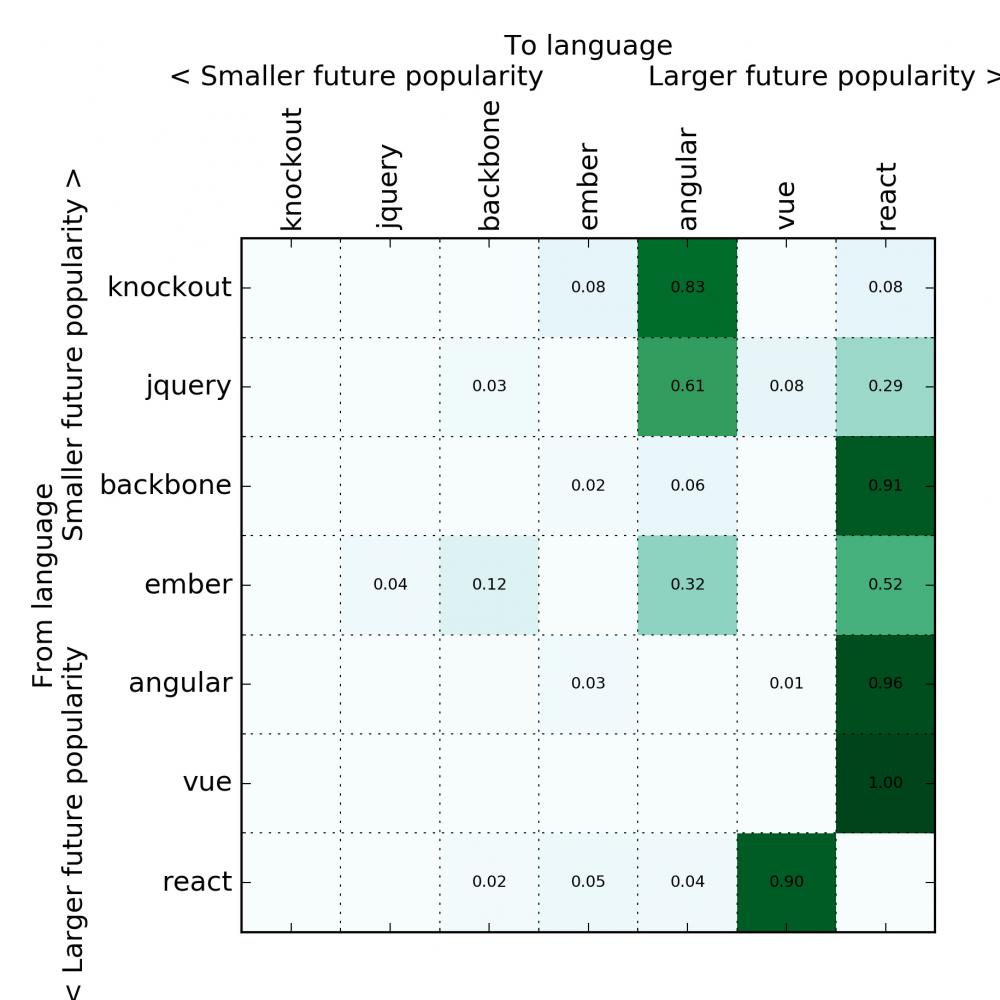
我预期 React 会脱颖而出成为第一,但有趣的是,Vue 也表现得非常好。我很惊讶于 Angular 的表现——传闻大批的人似乎在逃离 Angular。
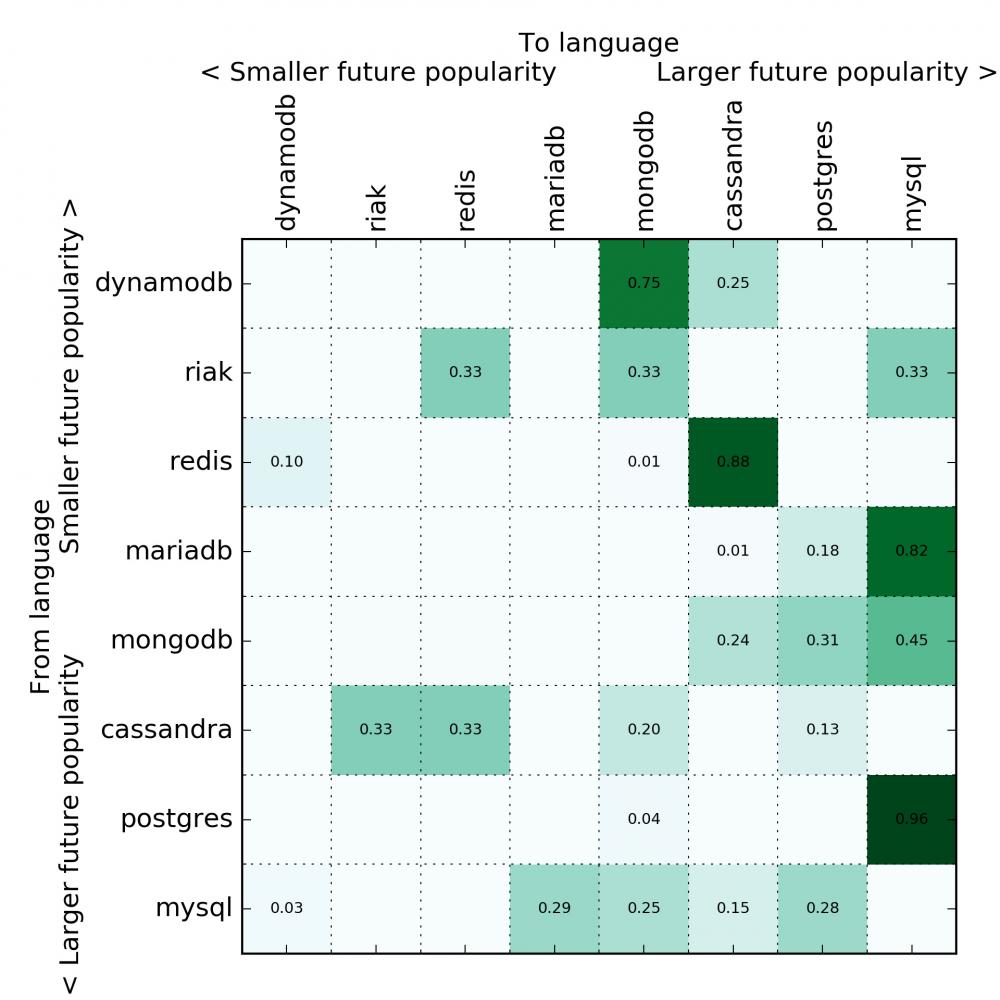
我开始留意共享单车 App,深度学习框架还有其他一些东西,但是数据太稀疏了,也不太可靠。有结果的话,会及时向大家公布的!
关于我这篇文章,看看网友们在 Hacker News 和 /r/programming 上的讨论;
为什么我从编程语言 1 转向编程语言 2,这篇博文给我启发;
下面是如何抓取 Google 并获取搜索结果数的代码:
很不幸,Google 对查询的 IP 有速率限制,但是我最终用 Proxymesh 抓取到了这 N*N 组合所需的所有数据。
注意:我在搜索的时候将确切的查询语句放在双引号中了,比如:“switch from go to c++”
细心的读者可能会问为什么 JavaScript 没有包含在分析中。原因是:(a)如果你在前端开发中使用它,那么你会一直坚持用下去,并没有转移的这个过程,除非你疯了,要做转译(transpiling,从一种编程语言到另一种编程语言的编译),这种情况太不常见了;(b)大家会把后端的 JavaScript 认作是 “Node”。
对角线的元素又是怎么回事呢?当然了,有些人会只坚持使用一种编程语言,这也是有很大的可能性的。但是我选择忽略它,因为:(a)事实证明,像“stay with Swift”(坚守 Swift)的搜索结果 99% 都是和女明星 Taylor Swift 相关的;(b)平稳分布与添加一个常数对角(单位)矩阵是无关的(即添加一个常数对角矩阵结果不变);(c)这是我的博客,所以我想怎样就怎样 [坏笑]
对于上一条的(b),e(αS+(1−α)I) = e(S) 这个结论是对的,其中,e(…) 是第一特征向量,I 是单位矩阵。这个结论可能不完全符合现实,对于不同的编程语言,你坚持用它的概率可能是不相等的。
重复相乘以得到第一特征向量的方法叫做幂迭代(Power iteration)。
这个用特征向量表示的模型能不能对实际情况做超准确地描述呢?大概不能。我的脑海中浮现出了一句来自 George Box 的名言:“所有模型都有错,不过有些还是有用的”(All models are wrong, some are useful,意为没有模型能够完全准确地描述实际情况,但是可以用一些模型来解决问题。George
Box 是英国著名的统计学家)。
我也知道还有一些其他的约束条件需要一一考虑,但是实际情况基本都是这样的。
代码可以在 Github 上找到。
我看了一篇博客,标题是《为什么我们要从 X 语言转到 Y 语言》,具体是哪种编程语言,我忘了。于是我开始想,是不是可以把这些文章归纳起来,生成一个关于从 X 语言转到 Y 语言的 N*N 的联列表(contingency table)?
所以我写了个小脚本,可以用脚本在 Google 上查询,再加上一小段代码就能得到搜索结果的数目。我尝试了用几个不同的关键词来搜索,像“move from <language 1> to <language 2>”,“switch
to <language 2> from <language 1> ”等等。最终得到了一个所有语言的 N*N 的联列表。
本文图表尺寸很大,先来解释如何读图:
左侧纵向语言是「叛逃的源语言」;
上方横向的语言是「叛逃的目标语言」;
例如:从 C 语言转到 C# 的数量为 3619,从 C# 转到 C 的有 37229;
(点击查看大图)
有意思的部分来了。实际上我们可以把搜索结果数看作是编程语言之间转换的概率,从而得出一些关于未来编程语言的流行趋势的结论。一个关键点是,这个(编程语言转换过程)的平稳分布并不取决于它们的初始分布。事实证明,这只是矩阵的第一特征向量(first eigenvector)而已。所以没必要去假设现在哪种编程语言很流行,我们推测出的未来的平稳分布状态和初始状态是独立的。
我们需要把上述的联列表转化成转移矩阵(stochastic matrix)的形式,用来描述从状态
ii 到状态 jj 的概率。非常简单——想要把联列矩阵解释为转移概率的话,可以将联列矩阵的每一行正则化。这样就能得到从 X 语言到 Y 语言的粗略近似概率。
找出第一特征向量并不重要,我们只要把一个向量多次乘上这个转移矩阵,最终会向第一特征向量收敛。顺便说下,可以看看下面的注意事项,有关于我如何操作的更多讨论。
Go 是编程语言的未来(?)
闲话少说,下表是平稳分布下排名前几的语言:| 16.41% | Go |
| 14.26% | C |
| 13.21% | Java |
| 11.51% | C++ |
| 9.45% | Python |
(点击查看大图)
令人惊讶的是(至少对我来说),Go 成为最大赢家。有超多的搜索结果显示大家由其他语言转向 Go。我都不能确定我对此是什么感受了(我对 Go 的感情很复杂)。但是我的绝对分析指出了一个必然结论,那就是 Go 值得关注。
C
语言到今年就有 45 岁了,仍然表现良好。我手动做了一些搜索,有很多都是人们真的在写他们通过从另一种编程语言迁移到 C,对特定的紧密循环(tight loops)做了优化。这个结果是错的吗?我不这么认为。C 语言是计算机工作的通用语言(lingua franca),如果人们还会积极地将其他语言的片段转换为 C 语言,那么这个结论也就可想而知了。说真的,我认为 C 语言会在它 100 岁生日,也就是 2072 年以前,变得更强大。有我在 LinkedIn 上对 C 的支持,我希望招聘人员能在 21 世纪 50
年代的时候给我一些关于 C 语言的工作机会(我收回上面那句话——希望 C 会比 LinkedIn 活得久)。
除了上面提到的以外,这些分析也很符合我的预期。Java
还在,Perl 灭亡了,Rust 做的相当不错。
顺便一提,这个分析让我想起了下面这条推
这图非常有意思,展示了在数据分析中 R 和 Python 之间的转化率。
JavaScript 框架
我对前端框架也做了同样的分析:我预期 React 会脱颖而出成为第一,但有趣的是,Vue 也表现得非常好。我很惊讶于 Angular 的表现——传闻大批的人似乎在逃离 Angular。
数据库
我开始留意共享单车 App,深度学习框架还有其他一些东西,但是数据太稀疏了,也不太可靠。有结果的话,会及时向大家公布的!
注意事项
关于我这篇文章,看看网友们在 Hacker News 和 /r/programming 上的讨论;为什么我从编程语言 1 转向编程语言 2,这篇博文给我启发;
下面是如何抓取 Google 并获取搜索结果数的代码:
<br /><br /><br />
def get_n_results_dumb(q):<br /><br /><br />
r = requests.get('http://www.google.com/search',<br /><br /><br />
params={'q': q,<br /><br /><br />
"tbs": "li:1"})<br /><br /><br />
r.raise_for_status()<br /><br /><br />
soup = bs4.BeautifulSoup(r.text)<br /><br /><br />
s = soup.find('div', {'id': 'resultStats'}).text<br /><br /><br />
if not s:<br /><br /><br />
return 0<br /><br /><br />
m = re.search(r'([0-9,]+)', s)<br /><br /><br />
return int(m.groups()[0].replace(',', ''))很不幸,Google 对查询的 IP 有速率限制,但是我最终用 Proxymesh 抓取到了这 N*N 组合所需的所有数据。
注意:我在搜索的时候将确切的查询语句放在双引号中了,比如:“switch from go to c++”
细心的读者可能会问为什么 JavaScript 没有包含在分析中。原因是:(a)如果你在前端开发中使用它,那么你会一直坚持用下去,并没有转移的这个过程,除非你疯了,要做转译(transpiling,从一种编程语言到另一种编程语言的编译),这种情况太不常见了;(b)大家会把后端的 JavaScript 认作是 “Node”。
对角线的元素又是怎么回事呢?当然了,有些人会只坚持使用一种编程语言,这也是有很大的可能性的。但是我选择忽略它,因为:(a)事实证明,像“stay with Swift”(坚守 Swift)的搜索结果 99% 都是和女明星 Taylor Swift 相关的;(b)平稳分布与添加一个常数对角(单位)矩阵是无关的(即添加一个常数对角矩阵结果不变);(c)这是我的博客,所以我想怎样就怎样 [坏笑]
对于上一条的(b),e(αS+(1−α)I) = e(S) 这个结论是对的,其中,e(…) 是第一特征向量,I 是单位矩阵。这个结论可能不完全符合现实,对于不同的编程语言,你坚持用它的概率可能是不相等的。
重复相乘以得到第一特征向量的方法叫做幂迭代(Power iteration)。
这个用特征向量表示的模型能不能对实际情况做超准确地描述呢?大概不能。我的脑海中浮现出了一句来自 George Box 的名言:“所有模型都有错,不过有些还是有用的”(All models are wrong, some are useful,意为没有模型能够完全准确地描述实际情况,但是可以用一些模型来解决问题。George
Box 是英国著名的统计学家)。
我也知道还有一些其他的约束条件需要一一考虑,但是实际情况基本都是这样的。
代码可以在 Github 上找到。

相关文章推荐
- 大神为你分析 Go、Java、C 等主流编程语言(Go可以替代Java,而且最小化程序员的工作量,学习比较容易)
- Mozart OZ计算机编程语言有你想要的几乎全部特性,本身有haskell,lisp,prolog,c,perl,java等语言的影子,(本帖以后续会连载)
- TIOBE 2 月编程语言排行榜:Java稳居第一,Go 还在跌!
- 在线编程语言模拟(Java,C,Python,R语言,Ruby,PHP,Perl,Go等)
- 为Java程序员准备的Go语言入门PPT
- TIOBE 2 月编程语言排行榜:Java稳居第一,Go 还在跌!
- 在线编程语言模拟(Java,C,Python,R语言,Ruby,PHP,Perl,Go等)
- java程序员10分钟可上手的golang框架golang实战使用gin+xorm搭建go语言web框架restgo
- 程序员的编程语言迁移路线
- D、GO、Rust 谁会在未来取代 C?为什么?——Go语言的定位非常好,Rust语言非常优秀,D语言也不错
- Java程序员应该掌握的三种语言
- Java脚本语言程序员手册(Java Scripting Programmer's Guide)
- Java语言程序员人生:J2ee的学习流程简介
- Java程序员应该掌握的三种语言
- 寻找更好的Java替代语言的10大理由-----Scala是个不错的选择
- Java程序员应该掌握的三种语言
- Go 语言:Google 的新编程语言
- Java程序员应该掌握的三种语言
- Java程序员应该掌握的三种语言
- JAVA语言基础:现在你还在用if else吗?