R语言分类算法之随机森林(Random Forest)
2017-05-08 00:00
267 查看
1.原理分析:
随机森林是通过自助法(boot-strap)重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练集样本集合,然后根据自助样本集生成k个决策树组成的随机森林,新数据的分类结果按照决策树投票多少形成的分数而定.
通俗的理解为由许多棵决策树组成的森林,而每个样本需要经过每棵树进行预测,然后根据所有决策树的预测结果最后来确定整个随机森林的预测结果.随机森林中的每一颗决策树都为二叉树,其生成遵循自顶向下的递归分裂原则,即从根节点开始依次对训练集进行划分.在二叉树中,根节点包含全部训练数据,按照节点不纯度最小原则,分裂为左节点和右节点,他们分别包含训数据的一个子集,按照同样的规则,节点继续分裂,直到满足分支停止规则,停止生长.
1.首先我们用N来表示原始训练集样本的个数,用M来表示变量的数目.
2.其次我们需要确定一个定值m,该值被用来决定当在一个节点上做决定时,会使用到多少个变量.m

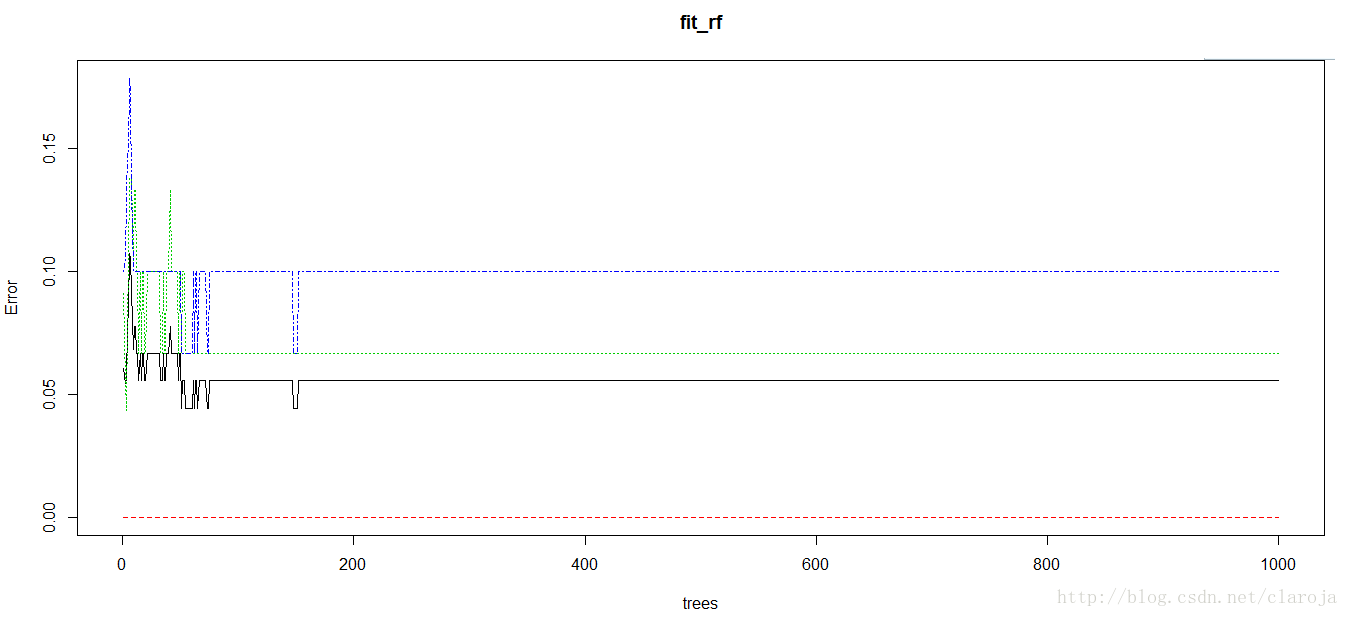
2)作图
随机森林是通过自助法(boot-strap)重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练集样本集合,然后根据自助样本集生成k个决策树组成的随机森林,新数据的分类结果按照决策树投票多少形成的分数而定.
通俗的理解为由许多棵决策树组成的森林,而每个样本需要经过每棵树进行预测,然后根据所有决策树的预测结果最后来确定整个随机森林的预测结果.随机森林中的每一颗决策树都为二叉树,其生成遵循自顶向下的递归分裂原则,即从根节点开始依次对训练集进行划分.在二叉树中,根节点包含全部训练数据,按照节点不纯度最小原则,分裂为左节点和右节点,他们分别包含训数据的一个子集,按照同样的规则,节点继续分裂,直到满足分支停止规则,停止生长.
1.首先我们用N来表示原始训练集样本的个数,用M来表示变量的数目.
2.其次我们需要确定一个定值m,该值被用来决定当在一个节点上做决定时,会使用到多少个变量.m
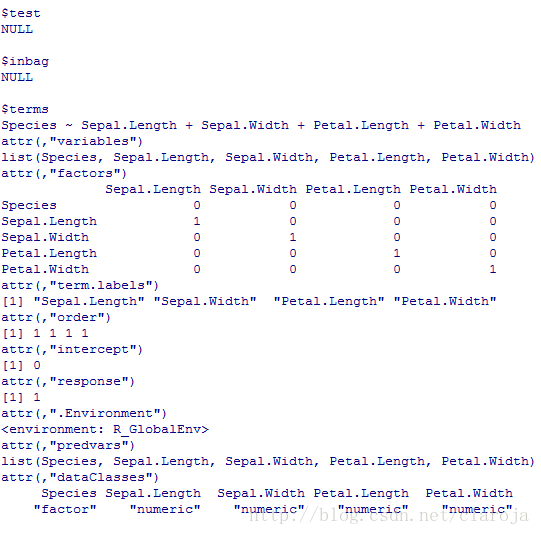
fit_rf=randomForest(Species~.,data=data_train,mtry=4,importance=TRUE,ntree=1000) fit_rf[1:length(fit_rf)]
2)作图

相关文章推荐
- R语言分类算法之随机森林(Random Forest)
- 【转】 R语言与机器学习学习笔记(分类算法)(1)K-近邻算法
- [置顶] 【ML--14】在R语言中使用SVM算法做多分类预测
- R语言与机器学习学习笔记(分类算法)(4)支持向量机
- 【转】R语言与机器学习学习笔记(分类算法)(2)决策树算法
- R语言与数据分析之三:分类算法2
- R语言与机器学习学习笔记(分类算法)(5)神经网络
- R语言使用逻辑回归分类算法
- 机器学习算法(二)——决策树分类算法及R语言实现方法
- 【转】R语言与机器学习学习笔记(分类算法)(3)朴素贝叶斯算法
- R语言与机器学习学习笔记(分类算法)(6)logistic回归
- R语言与机器学习学习笔记(分类算法)(1)K-近邻算法
- R语言分类算法之距离判别(Distance Discrimination)
- 【转】R语言与机器学习学习笔记(分类算法)(4)支持向量机
- 在R语言中对回归树模型、装袋算法与随机森林之间的简单比较
- R语言与分类算法的绩效评估
- R语言与机器学习学习笔记(分类算法)(2)决策树算法
- R语言与机器学习学习笔记(分类算法)(4)支持向量机
- 机器学习中的算法:决策树模型组合之随机森林(Random Forest)
- 【转】R语言与机器学习学习笔记(分类算法)(5)神经网络