R语言分类算法之集成学习(Bootstrap Aggregating)
2017-05-08 00:00
267 查看
1.集成学习(Bootstrap Aggregating)原理分析:
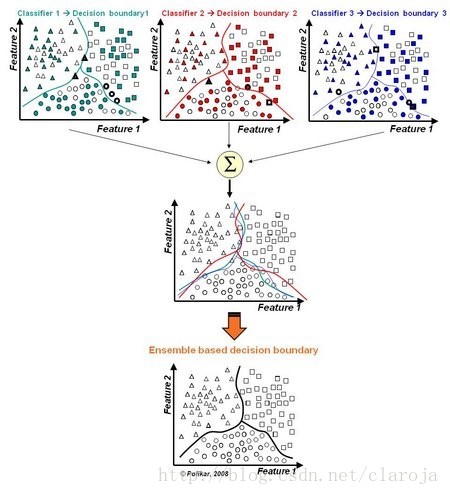
Bagging是Bootstrap Aggregating的缩写,简单来说,就是通过使用boostrap抽样得到若干不同的训练集,以这些训练集分别建立模型,即得到一系列的基分类器,这些分类器由于来自不同的训练样本,他们对同一测试集的预测效果不一样.因此,Bagging算法随后对基分类器的一系列预测结果进行投票(分类问题)和平均(回归问题),从而得到每一个测试集样本的最终预测结果,这一集成后的结果往往是准确而稳定的.
比如现在基分类器1至10,他们对某样本的预测结果分别为类别1/2/1/1/1/1/2/1/1/2,则Bagging给出的最终结果为”该样本属于类别1”,因为大多数基分类器将票投给了1.
AdaBoost(Adaptive Boosting)相对于Bagging算法更为巧妙,且一般来说是效果更优的集成分类算法,尤其在数据集分布不均衡的情况下,其优势更为显著.该算法的提出先于Bagging,但在复杂度和效果上高于Bagging.
AdaBoost同样是在若干基分类器基础上的一种集成算法,但不同于Bagging对一系列预测结果的简单综合,该算法在依次构建基分类器的过程中,会根据上一个基分类器对各训练集样本的预测结果,自行调整在本次基分类器构造时,个样本被抽中的概率.具体来说,如果在上一基分类器的预测中,样本i被错误分类了,那么,在这一次基分类器的训练样本抽取过程中,样本i就会被赋予较高的权重,以使其能够以较大的可能被抽中,从而提高其被正确分类的概率.
这样一个实时调节权重的过程正是AdaBoost算法的优势所在,它通过将若干具有互补性质的基分类器集合于一体,显著提高了集成分类器的稳定性和准确性.另外,Bagging和AdaBoost的基分类器选取都是任意的,但绝大多数我们使用决策树,因为决策树可以同时处理数值/类别/次序等各类型变量,且变量的选择也较容易.
2.在R语言中的应用
集成学习算法主要运用到了adabag包中的bossting函数。
bossting(formula,data,boos=TRUE,mfinal=100,coeflearn=’Breiman’,control)
3.以iris数据集为例进行分析
1)应用模型并查看模型的相应参数
fit_bag=bagging(Species~.,data_train,mfinal=5,control=rpart.control(maxdepth=3))
fit_bag[1:length(bag)]


2)预测分析
pre_bag=predict(fit_bag,data_test)

Bagging是Bootstrap Aggregating的缩写,简单来说,就是通过使用boostrap抽样得到若干不同的训练集,以这些训练集分别建立模型,即得到一系列的基分类器,这些分类器由于来自不同的训练样本,他们对同一测试集的预测效果不一样.因此,Bagging算法随后对基分类器的一系列预测结果进行投票(分类问题)和平均(回归问题),从而得到每一个测试集样本的最终预测结果,这一集成后的结果往往是准确而稳定的.
比如现在基分类器1至10,他们对某样本的预测结果分别为类别1/2/1/1/1/1/2/1/1/2,则Bagging给出的最终结果为”该样本属于类别1”,因为大多数基分类器将票投给了1.
AdaBoost(Adaptive Boosting)相对于Bagging算法更为巧妙,且一般来说是效果更优的集成分类算法,尤其在数据集分布不均衡的情况下,其优势更为显著.该算法的提出先于Bagging,但在复杂度和效果上高于Bagging.
AdaBoost同样是在若干基分类器基础上的一种集成算法,但不同于Bagging对一系列预测结果的简单综合,该算法在依次构建基分类器的过程中,会根据上一个基分类器对各训练集样本的预测结果,自行调整在本次基分类器构造时,个样本被抽中的概率.具体来说,如果在上一基分类器的预测中,样本i被错误分类了,那么,在这一次基分类器的训练样本抽取过程中,样本i就会被赋予较高的权重,以使其能够以较大的可能被抽中,从而提高其被正确分类的概率.
这样一个实时调节权重的过程正是AdaBoost算法的优势所在,它通过将若干具有互补性质的基分类器集合于一体,显著提高了集成分类器的稳定性和准确性.另外,Bagging和AdaBoost的基分类器选取都是任意的,但绝大多数我们使用决策树,因为决策树可以同时处理数值/类别/次序等各类型变量,且变量的选择也较容易.
2.在R语言中的应用
集成学习算法主要运用到了adabag包中的bossting函数。
bossting(formula,data,boos=TRUE,mfinal=100,coeflearn=’Breiman’,control)
3.以iris数据集为例进行分析
1)应用模型并查看模型的相应参数
fit_bag=bagging(Species~.,data_train,mfinal=5,control=rpart.control(maxdepth=3))
fit_bag[1:length(bag)]
2)预测分析
pre_bag=predict(fit_bag,data_test)

相关文章推荐
- R语言分类算法之集成学习(Bootstrap Aggregating)
- R语言与机器学习学习笔记(分类算法)(1)K-近邻算法
- R语言与机器学习学习笔记(分类算法
- R语言与机器学习学习笔记(分类算法)(3)朴素贝叶斯
- 机器学习分类算法——集成学习
- R语言与机器学习学习笔记(分类算法)(4)支持向量机
- R语言分类算法之朴素贝叶斯分类(Naive Bayesian Classification)
- 机器学习算法(二)——决策树分类算法及R语言实现方法
- 【转】 R语言与机器学习学习笔记(分类算法)(1)K-近邻算法
- R语言与机器学习学习笔记(分类算法)(5)神经网络
- [置顶] 【ML--14】在R语言中使用SVM算法做多分类预测
- 【转】R语言与机器学习学习笔记(分类算法)(2)决策树算法
- R语言与数据分析之三:分类算法2
- R语言与机器学习学习笔记(分类算法)(2)决策树算法
- R语言与机器学习学习笔记(分类算法)(6)logistic回归
- 【转】R语言与机器学习学习笔记(分类算法)(3)朴素贝叶斯算法
- R语言与机器学习学习笔记(分类算法)(6)logistic回归
- 【转】R语言与机器学习学习笔记(分类算法)(4)支持向量机
- 基于R语言的分类算法之CART决策树
- 朴素贝叶斯分类算法的R语言实现