自己动手实现机器学习算法:神经网络(附源代码)
2017-05-03 17:47
381 查看
原创文章,转载请注明:转载自 听风居士博客(http://blog.csdn.net/zhouzx2010)
神经网络的一些原理这不做介绍,不清楚的可以搜索相关博客和数据,资料相对较多。
下面开始正题
输入层(input layer), 隐藏层 (hidden layers), 输入层 (output layers)
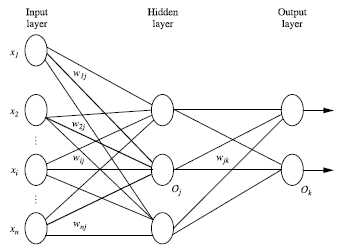
2.1. 前向传播求损失
由输入层向前传送

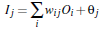

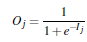
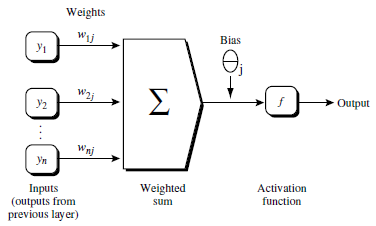
2.2. 反向传播更新w
3.1.定义激活函数
激活函数一般有双曲函数和逻辑函数
#xhe_tmpurl
1.1 双曲函数(tanh)

其导数:


1.2 逻辑函数(logistic function)
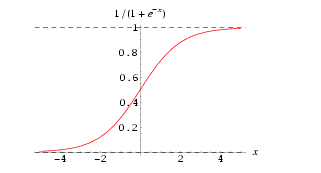
其导数f'(x)=f(x)*[1-f(x)]
代码:
3.2 然后定义两层的神经网络的class,初始化激活函数,和权值:
给权值随机赋值,权值的范围[-0.25,0.25)
3.3下面实现神经网络的核心训练逻辑向前传播计算损失和相互传播更新w
3.3.1、函数申明:
[/code]
参数X为样本数据,y为标签数据,learning_rate 为学习率默认0.2,epochs 为迭代次数默认值10000
3.3.2、数据预处理:
上面代码,给X加了一个值为1的维度,y变成numpy中的array类型
3.3.3、数据训练
正向计算部分:
将每层的计算节点值保存在二维数组a中,下面反向传播更新权值时候会用到该数据。计算过程如下图所示:

反向传播部分:
该部分的计算公式如下:
根据误差(error)反向传送
对于输出层:

对于隐藏层:
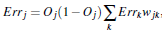
权重更新:

偏向更新

其中delta保存每层节点的Err值,最后利用前面的节点值a和现在的delta更新权值。
3.3.4、预测
预测的过程就是一个向前计算输出值的过程:
至此,神经网络的算法就完成了。大功告成!
完整代码:https://github.com/tingfengjushi/mymllib/tree/master/NeuralNetwork
现在用刚才写的神经网络算法,来训练一个实现“异或“的神经网络。
输入数据如下:
0 0 0
0 1 1
1 0 1
1 1 0
前两列是x,最后一列是y
当x两个维度值是相同时候返回0,不同时候返回1,就是
“异或“。
代码如下:
执行结果:
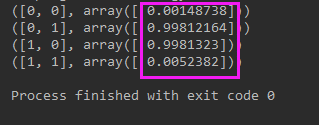
可以看到执行结果已经很不错了
可以看到该神经网络的代码只是一个简单的两层网络,后面将继续改进实现更深层次的网络,可以关注本博客了解详情,敬请期待。
神经网络的一些原理这不做介绍,不清楚的可以搜索相关博客和数据,资料相对较多。
下面开始正题
一、神经网络的构成
输入层(input layer), 隐藏层 (hidden layers), 输入层 (output layers)
二、神经网络的算法的核心过程:
2.1. 前向传播求损失由输入层向前传送
2.2. 反向传播更新w
三、代码实现
3.1.定义激活函数激活函数一般有双曲函数和逻辑函数
#xhe_tmpurl
1.1 双曲函数(tanh)
其导数:
1.2 逻辑函数(logistic function)
其导数f'(x)=f(x)*[1-f(x)]
代码:
#!/usr/bin/env # -*- coding:utf-8 -*- import numpy as np def tanh(x): return np.tanh(x) def tanh_derivative(x): return 1.0 - np.tanh(x) * np.tanh(x) def logistic(x): return 1 / (1 + np.exp(-x)) def logistic_derivative(x): return logistic(x) * (1 - logistic(x) )
3.2 然后定义两层的神经网络的class,初始化激活函数,和权值:
给权值随机赋值,权值的范围[-0.25,0.25)
class NeuralNetworkWith2layers: def __init__(self, layers, activation='tanh'): if activation == 'Logistic': self.activation = logistic self.activation_deriv = logistic_derivative elif activation == 'tanh': self.activation = tanh self.activation_deriv = tanh_derivative self.weights = [] for i in range(1, len(layers)-1): # 初始化 权值范围 [-0.25,0.25) # [0,1) * 2 - 1 => [-1,1) => * 0.25 => [-0.25,0.25) self.weights.append( (2*np.random.random((layers[i-1] + 1, layers[i] + 1 ))-1 ) * 0.25 ) self.weights.append( (2*np.random.random((layers[i] + 1, layers[i+1] ))-1 ) * 0.25 )
3.3下面实现神经网络的核心训练逻辑向前传播计算损失和相互传播更新w
3.3.1、函数申明:
def fit(self, X, y, learning_rate=0.2, epochs = 10000):
[/code]
参数X为样本数据,y为标签数据,learning_rate 为学习率默认0.2,epochs 为迭代次数默认值10000
3.3.2、数据预处理:
X = np.atleast_2d(X) X = np.column_stack((X, np.ones(len(X)))) y = np.array(y)
上面代码,给X加了一个值为1的维度,y变成numpy中的array类型
3.3.3、数据训练
def fit(self, X, y, learning_rate=0.2, epochs = 10000): X = np.atleast_2d(X) temp = np.ones([X.shape[0], X.shape[1]+1]) temp[:,0:-1] = X X = temp y = np.array(y) for k in range(epochs): i = np.random.randint(X.shape[0]) a = [X[i]] # 正向计算 for l in range(len(self.weights)): a.append(self.activation( np.dot(a[l], self.weights[l])) ) # 反向传播 error = y[i] - a[-1] deltas = [error * self.activation_deriv(a[-1])] # starting backprobagation layerNum = len(a) - 2 for j in range(layerNum, 0, -1): # 倒数第二层开始 deltas.append(deltas[-1].dot(self.weights[j].T) * self.activation_deriv(a[j])) deltas.reverse() # 更新权值 for i in range(len(self.weights)): layer = np.atleast_2d(a[i]) delta = np.atleast_2d(deltas[i]) self.weights[i] += learning_rate * layer.T.dot(delta)
正向计算部分:
将每层的计算节点值保存在二维数组a中,下面反向传播更新权值时候会用到该数据。计算过程如下图所示:
反向传播部分:
该部分的计算公式如下:
根据误差(error)反向传送
对于输出层:
对于隐藏层:
权重更新:
偏向更新
其中delta保存每层节点的Err值,最后利用前面的节点值a和现在的delta更新权值。
3.3.4、预测
预测的过程就是一个向前计算输出值的过程:
def predict(self, x): x = np.array(x) temp = np.ones(x.shape[0] + 1) temp[0:-1] = x a = temp for l in range(0, len(self.weights)): a = self.activation(np.dot(a, self.weights[l])) return a
至此,神经网络的算法就完成了。大功告成!
完整代码:https://github.com/tingfengjushi/mymllib/tree/master/NeuralNetwork
四、神经网络代码测试
现在用刚才写的神经网络算法,来训练一个实现“异或“的神经网络。输入数据如下:
0 0 0
0 1 1
1 0 1
1 1 0
前两列是x,最后一列是y
当x两个维度值是相同时候返回0,不同时候返回1,就是
“异或“。
代码如下:
#!/usr/bin/env # -*- coding:utf-8 -*- from NeuralNetwork import NeuralNetwork from DeepNeuralNetwork import DeepNeuralNetwork import numpy as np nn = NeuralNetwork([2, 2, 1], 'tanh') #nn = DeepNeuralNetwork([2, 2, 1], 'tanh') x = np.array([[0,0],[0,1],[1,0],[1,1]]) y = np.array([0,1,1,0]) nn.fit(x, y) for i in [[0,0],[0,1],[1,0],[1,1]]: print (i, nn.predict(i))
执行结果:
可以看到执行结果已经很不错了
五、后记
可以看到该神经网络的代码只是一个简单的两层网络,后面将继续改进实现更深层次的网络,可以关注本博客了解详情,敬请期待。

相关文章推荐
- 自己动手实现机器学习算法:神经网络(附源代码)
- 【自己动手写神经网络】小白入门连载(三)--神经元的感知
- 学习【神经网络】最好的书来了《自己动手写神经网络》电子书在百度阅读上线!
- 用自己实现的全连接神经网络分类MNIST
- 用TensorFlow自己动手搭建神经网络
- 机器学习算法及代码实现--神经网络
- 看到一篇【自己动手写神经网络】,转过来
- 深度学习与计算机视觉系列(9)_串一串神经网络之动手实现小例子
- 机器学习算法及代码实现--神经网络
- 自己动手实践神经网络----视频课程开课了
- 机器学习算法实现——神经网络
- 自己动手写神经网络,自己真的可以动手写神经网络嘛?
- 深度学习与计算机视觉系列(9)_串一串神经网络之动手实现小例子
- 连“霍金”都想学习的“人工智能”---【自己动手写神经网络】小白入门连载开始了(4)
- 深度学习与计算机视觉系列(9)_串一串神经网络之动手实现小例子
- 【原创】连“霍金”都想学习的“人工智能”---【自己动手写神经网络】小白入门连载开始了(1)
- 【自己动手写神经网络】---人人都可以学的神经网络书
- 【自己动手写神经网络】小白入门连载(二)--机器人时代必须得有人工神经(不是神经病)
- 深度学习与计算机视觉系列(9)_串一串神经网络之动手实现小例子
- 机器学习算法及代码实现--神经网络