kNN算法__手写识别——基于Python和NumPy函数库
2017-04-24 23:11
881 查看
【机器学习算法实现】系列文章将记录个人阅读机器学习论文、书籍过程中所碰到的算法,每篇文章描述一个具体的算法、算法的编程实现、算法的具体应用实例。争取每个算法都用多种语言编程实现。所有代码共享至github:https://github.com/wepe/MachineLearning-Demo
欢迎交流指正!
kNN算法,即K最近邻(k-NearestNeighbor)分类算法,是最简单的机器学习算法之一,算法思想很简单:从训练样本集中选择k个与测试样本“距离”最近的样本,这k个样本中出现频率最高的类别即作为测试样本的类别。下面的简介选自wiki百科:http://zh.wikipedia.org/wiki/%E6%9C%80%E8%BF%91%E9%84%B0%E5%B1%85%E6%B3%95
目标:分类未知类别案例。
输入:待分类未知类别案例项目。已知类别案例集合D ,其中包含 j个已知类别的案例。
输出:项目可能的类别。
如下图
我们考虑样本为二维的情况下,利用knn方法进行二分类的问题。图中三角形和方形是已知类别的样本点,这里我们假设三角形为正类,方形为负类。图中圆形点是未知类别的数据,我们要利用这些已知类别的样本对它进行分类。

k近邻算法例子示意图
分类过程如下:
1 首先我们事先定下k值(就是指k近邻方法的k的大小,代表对于一个待分类的数据点,我们要寻找几个它的邻居)。这边为了说明问题,我们取两个k值,分别为3和5;
2 根据事先确定的距离度量公式(如:欧氏距离),得出待分类数据点和所有已知类别的样本点中,距离最近的k个样本。
3 统计这k个样本点中,各个类别的数量。如上图,如果我们选定k值为3,则正类样本(三角形)有2个,负类样本(方形)有1个,那么我们就把这个圆形数据点定为正类;而如果我们选择k值为5,则正类样本(三角形)有2个,负类样本(方形)有3个,那么我们这个数据点定为负类。即,根据k个样本中,数量最多的样本是什么类别,我们就把这个数据点定为什么类别。
补充:
优缺点:
(1)优点:
算法简单,易于实现,不需要参数估计,不需要事先训练。
(2)缺点:
属于懒惰算法,“平时不好好学习,考试时才临阵磨枪”,意思是kNN不用事先训练,而是在输入待分类样本时才开始运行,这一特点导致kNN计算量特别大,而且训练样本必须存储在本地,内存开销也特别大。
K的取值:
参数k的取值一般通常不大于20。——《机器学习实战》
kNN算法主要被应用于文本分类、相似推荐。本文将描述一个分类的例子,是《机器学习实战》一书中的实例,使用python语言以及数值计算库NumPy。下面首先简单介绍本实例编程开发过程中所用到的python、numpy中的函数。
NumPy库总包含两种基本的数据类型:矩阵和数组,矩阵的使用类似Matlab,本实例用得多的是数组array。
shape()
shape是numpy函数库中的方法,用于查看矩阵或者数组的维素
>>>shape(array) 若矩阵有m行n列,则返回(m,n)
>>>array.shape[0] 返回矩阵的行数m,参数为1的话返回列数n
tile()
tile是numpy函数库中的方法,用法如下:
>>>tile(A,(m,n)) 将数组A作为元素构造出m行n列的数组
sum()
sum()是numpy函数库中的方法
>>>array.sum(axis=1)按行累加,axis=0为按列累加
argsort()
argsort()是numpy中的方法,得到矩阵中每个元素的排序序号
>>>A=array.argsort() A[0]表示排序后 排在第一个的那个数在原来数组中的下标
dict.get(key,x)
Python中字典的方法,get(key,x)从字典中获取key对应的value,字典中没有key的话返回0
sorted()
python中的方法
min()、max()
numpy中有min()、max()方法,用法如下
>>>array.min(0) 返回一个数组,数组中每个数都是它所在列的所有数的最小值
>>>array.min(1) 返回一个数组,数组中每个数都是它所在行的所有数的最小值
listdir('str')
python的operator中的方法
>>>strlist=listdir('str') 读取目录str下的所有文件名,返回一个字符串列表
split()
python中的方法,切片函数
>>>string.split('str')以字符str为分隔符切片,返回list
关于更多的numpy中的函数,可以查阅官网:http://docs.scipy.org/doc/
手写识别的概念:是指将在手写设备上书写时产生的轨迹信息转化为具体字码。
手写识别系统是个很大的项目,识别汉字、英语、数字、其他字符。本文只是个小demo,重点不在手写识别而在于理解kNN,因此只识别0~9单个数字。
输入格式:每个手写数字已经事先处理成32*32的二进制文本,存储为txt文件。0~9每个数字都有10个训练样本,5个测试样本。训练样本集如下图:
打开3_3.txt这个文件看看:

上面的背景介绍完了,现在编程实现,大概分为三个步骤:
(1)将每个图片(即txt文本,以下提到图片都指txt文本)转化为一个向量,即32*32的数组转化为1*1024的数组,这个1*1024的数组用机器学习的术语来说就是特征向量。
(2)训练样本中有10*10个图片,可以合并成一个100*1024的矩阵,每一行对应一个图片。(这是为了方便计算,很多机器学习算法在计算的时候采用矩阵运算,可以简化代码,有时还可以减少计算复杂度)。
(3)测试样本中有10*5个图片,我们要让程序自动判断每个图片所表示的数字。同样的,对于测试图片,将其转化为1*1024的向量,然后计算它与训练样本中各个图片的“距离”(这里两个向量的距离采用欧式距离),然后对距离排序,选出较小的前k个,因为这k个样本来自训练集,是已知其代表的数字的,所以被测试图片所代表的数字就可以确定为这k个中出现次数最多的那个数字。
第一步:转化为1*1024的特征向量。程序中的filename是文件名,比如3_3.txt
[python] view
plain copy
<span style="font-family:SimSun;font-size:18px;">#样本是32*32的二值图片,将其处理成1*1024的特征向量
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect</span>
第二步、第三步:将训练集图片合并成100*1024的大矩阵,同时逐一对测试集中的样本分类
[python] view
plain copy
<span style="font-family:SimSun;font-size:18px;">def handwritingClassTest():
#加载训练集到大矩阵trainingMat
hwLabels = []
trainingFileList = listdir('trainingDigits') #os模块中的listdir('str')可以读取目录str下的所有文件名,返回一个字符串列表
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i] #训练样本的命名格式:1_120.txt
fileStr = fileNameStr.split('.')[0] #string.split('str')以字符str为分隔符切片,返回list,这里去list[0],得到类似1_120这样的
classNumStr = int(fileStr.split('_')[0]) #以_切片,得到1,即类别
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
#逐一读取测试图片,同时将其分类
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))</span>
这里面的函数classify()为分类主体函数,计算欧式距离,并最终返回测试图片类别:
[python] view
plain copy
<span style="font-family:SimSun;font-size:18px;">#分类主体程序,计算欧式距离,选择距离最小的k个,返回k个中出现频率最高的类别
#inX是所要测试的向量
#dataSet是训练样本集,一行对应一个样本。dataSet对应的标签向量为labels
#k是所选的最近邻数目
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] #shape[0]得出dataSet的行数,即样本个数
diffMat = tile(inX, (dataSetSize,1)) - dataSet #tile(A,(m,n))将数组A作为元素构造m行n列的数组
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1) #array.sum(axis=1)按行累加,axis=0为按列累加
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort() #array.argsort(),得到每个元素的排序序号
classCount={} #sortedDistIndicies[0]表示排序后排在第一个的那个数在原来数组中的下标
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #get(key,x)从字典中获取key对应的value,没有key的话返回0
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) #sorted()函数,按照第二个元素即value的次序逆向(reverse=True)排序
return sortedClassCount[0][0]</span>
整个工程文件包括源代码、训练集、测试集,可到github获取:github地址
进入use Python and NumPy目录,打开python开发环境,import kNN模块,调用手写识别函数:
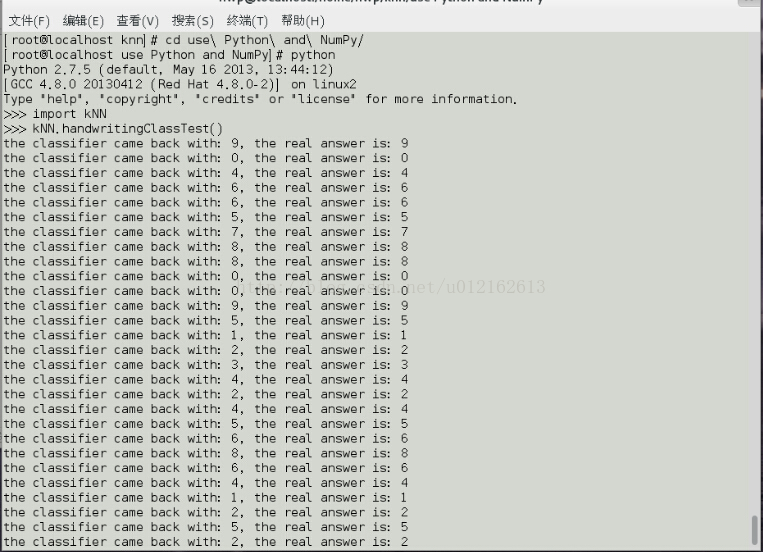
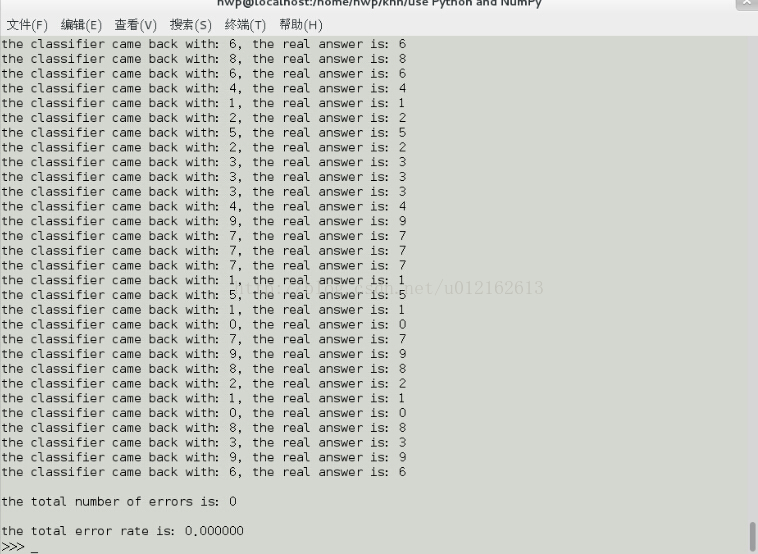
因为我用的训练集和测试集都比较小,所以凑巧没有识别错误的情况:
欢迎交流指正!
(1)kNN算法_手写识别实例——基于Python和NumPy函数库
1、kNN算法简介
kNN算法,即K最近邻(k-NearestNeighbor)分类算法,是最简单的机器学习算法之一,算法思想很简单:从训练样本集中选择k个与测试样本“距离”最近的样本,这k个样本中出现频率最高的类别即作为测试样本的类别。下面的简介选自wiki百科:http://zh.wikipedia.org/wiki/%E6%9C%80%E8%BF%91%E9%84%B0%E5%B1%85%E6%B3%95
方法
目标:分类未知类别案例。输入:待分类未知类别案例项目。已知类别案例集合D ,其中包含 j个已知类别的案例。
输出:项目可能的类别。
步骤
如下图我们考虑样本为二维的情况下,利用knn方法进行二分类的问题。图中三角形和方形是已知类别的样本点,这里我们假设三角形为正类,方形为负类。图中圆形点是未知类别的数据,我们要利用这些已知类别的样本对它进行分类。

k近邻算法例子示意图
分类过程如下:
1 首先我们事先定下k值(就是指k近邻方法的k的大小,代表对于一个待分类的数据点,我们要寻找几个它的邻居)。这边为了说明问题,我们取两个k值,分别为3和5;
2 根据事先确定的距离度量公式(如:欧氏距离),得出待分类数据点和所有已知类别的样本点中,距离最近的k个样本。
3 统计这k个样本点中,各个类别的数量。如上图,如果我们选定k值为3,则正类样本(三角形)有2个,负类样本(方形)有1个,那么我们就把这个圆形数据点定为正类;而如果我们选择k值为5,则正类样本(三角形)有2个,负类样本(方形)有3个,那么我们这个数据点定为负类。即,根据k个样本中,数量最多的样本是什么类别,我们就把这个数据点定为什么类别。
补充:
优缺点:
(1)优点:
算法简单,易于实现,不需要参数估计,不需要事先训练。
(2)缺点:
属于懒惰算法,“平时不好好学习,考试时才临阵磨枪”,意思是kNN不用事先训练,而是在输入待分类样本时才开始运行,这一特点导致kNN计算量特别大,而且训练样本必须存储在本地,内存开销也特别大。
K的取值:
参数k的取值一般通常不大于20。——《机器学习实战》
2、手写识别实例
kNN算法主要被应用于文本分类、相似推荐。本文将描述一个分类的例子,是《机器学习实战》一书中的实例,使用python语言以及数值计算库NumPy。下面首先简单介绍本实例编程开发过程中所用到的python、numpy中的函数。
2.1 python、numpy函数
NumPy库总包含两种基本的数据类型:矩阵和数组,矩阵的使用类似Matlab,本实例用得多的是数组array。shape()
shape是numpy函数库中的方法,用于查看矩阵或者数组的维素
>>>shape(array) 若矩阵有m行n列,则返回(m,n)
>>>array.shape[0] 返回矩阵的行数m,参数为1的话返回列数n
tile()
tile是numpy函数库中的方法,用法如下:
>>>tile(A,(m,n)) 将数组A作为元素构造出m行n列的数组
sum()
sum()是numpy函数库中的方法
>>>array.sum(axis=1)按行累加,axis=0为按列累加
argsort()
argsort()是numpy中的方法,得到矩阵中每个元素的排序序号
>>>A=array.argsort() A[0]表示排序后 排在第一个的那个数在原来数组中的下标
dict.get(key,x)
Python中字典的方法,get(key,x)从字典中获取key对应的value,字典中没有key的话返回0
sorted()
python中的方法
min()、max()
numpy中有min()、max()方法,用法如下
>>>array.min(0) 返回一个数组,数组中每个数都是它所在列的所有数的最小值
>>>array.min(1) 返回一个数组,数组中每个数都是它所在行的所有数的最小值
listdir('str')
python的operator中的方法
>>>strlist=listdir('str') 读取目录str下的所有文件名,返回一个字符串列表
split()
python中的方法,切片函数
>>>string.split('str')以字符str为分隔符切片,返回list
关于更多的numpy中的函数,可以查阅官网:http://docs.scipy.org/doc/
2.2 编程实现“手写识别”
手写识别的概念:是指将在手写设备上书写时产生的轨迹信息转化为具体字码。手写识别系统是个很大的项目,识别汉字、英语、数字、其他字符。本文只是个小demo,重点不在手写识别而在于理解kNN,因此只识别0~9单个数字。
输入格式:每个手写数字已经事先处理成32*32的二进制文本,存储为txt文件。0~9每个数字都有10个训练样本,5个测试样本。训练样本集如下图:
打开3_3.txt这个文件看看:
上面的背景介绍完了,现在编程实现,大概分为三个步骤:
(1)将每个图片(即txt文本,以下提到图片都指txt文本)转化为一个向量,即32*32的数组转化为1*1024的数组,这个1*1024的数组用机器学习的术语来说就是特征向量。
(2)训练样本中有10*10个图片,可以合并成一个100*1024的矩阵,每一行对应一个图片。(这是为了方便计算,很多机器学习算法在计算的时候采用矩阵运算,可以简化代码,有时还可以减少计算复杂度)。
(3)测试样本中有10*5个图片,我们要让程序自动判断每个图片所表示的数字。同样的,对于测试图片,将其转化为1*1024的向量,然后计算它与训练样本中各个图片的“距离”(这里两个向量的距离采用欧式距离),然后对距离排序,选出较小的前k个,因为这k个样本来自训练集,是已知其代表的数字的,所以被测试图片所代表的数字就可以确定为这k个中出现次数最多的那个数字。
第一步:转化为1*1024的特征向量。程序中的filename是文件名,比如3_3.txt
[python] view
plain copy
<span style="font-family:SimSun;font-size:18px;">#样本是32*32的二值图片,将其处理成1*1024的特征向量
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect</span>
第二步、第三步:将训练集图片合并成100*1024的大矩阵,同时逐一对测试集中的样本分类
[python] view
plain copy
<span style="font-family:SimSun;font-size:18px;">def handwritingClassTest():
#加载训练集到大矩阵trainingMat
hwLabels = []
trainingFileList = listdir('trainingDigits') #os模块中的listdir('str')可以读取目录str下的所有文件名,返回一个字符串列表
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i] #训练样本的命名格式:1_120.txt
fileStr = fileNameStr.split('.')[0] #string.split('str')以字符str为分隔符切片,返回list,这里去list[0],得到类似1_120这样的
classNumStr = int(fileStr.split('_')[0]) #以_切片,得到1,即类别
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
#逐一读取测试图片,同时将其分类
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))</span>
这里面的函数classify()为分类主体函数,计算欧式距离,并最终返回测试图片类别:
[python] view
plain copy
<span style="font-family:SimSun;font-size:18px;">#分类主体程序,计算欧式距离,选择距离最小的k个,返回k个中出现频率最高的类别
#inX是所要测试的向量
#dataSet是训练样本集,一行对应一个样本。dataSet对应的标签向量为labels
#k是所选的最近邻数目
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] #shape[0]得出dataSet的行数,即样本个数
diffMat = tile(inX, (dataSetSize,1)) - dataSet #tile(A,(m,n))将数组A作为元素构造m行n列的数组
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1) #array.sum(axis=1)按行累加,axis=0为按列累加
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort() #array.argsort(),得到每个元素的排序序号
classCount={} #sortedDistIndicies[0]表示排序后排在第一个的那个数在原来数组中的下标
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #get(key,x)从字典中获取key对应的value,没有key的话返回0
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) #sorted()函数,按照第二个元素即value的次序逆向(reverse=True)排序
return sortedClassCount[0][0]</span>
3、工程文件
整个工程文件包括源代码、训练集、测试集,可到github获取:github地址进入use Python and NumPy目录,打开python开发环境,import kNN模块,调用手写识别函数:
因为我用的训练集和测试集都比较小,所以凑巧没有识别错误的情况:

相关文章推荐
- 【机器学习算法实现】kNN算法__手写识别——基于Python和NumPy函数库
- 【机器学习算法实现】kNN算法__手写识别——基于Python和NumPy函数库
- (1)kNN算法_手写识别实例——基于Python和NumPy函数库
- 【机器学习算法实现】kNN算法__手写识别——基于Python和NumPy函数库
- 机器学习笔记2-基于KNN算法的手写字识别程序
- KNN近邻算法(python3)识别手写数字
- KNN算法 手写识别 python
- 基于python和numpy的KNN手写识别
- Python实现knn算法手写数字识别
- Python实现KNN算法手写识别数字
- 【python】机器学习实战KNN算法之手写数字识别
- Python实现基于KNN算法的笔迹识别功能详解
- 使用KNN算法在python下识别手写数字(带注释)
- kNN算法识别手写数字(代码笔记)
- 基于KNN算法实现的单个图片数字识别
- Python 学习笔记(Machine Learning In Action)K-近邻算法识别手写数字
- KNN算法-手写识别
- 机器学习(4)——KNN算法及手写数字的识别(二)
- 基于k近邻(KNN)的手写数字识别
- Python徒手实现识别手写数字—图像识别算法(K最近邻)