Spark - 利用 Spark SQL + MongoDB 对PandaTV主播进行等级分类
2017-04-20 14:34
232 查看
Spark SQL
使用Spark SQL时,最主要的两个组件就是DataFrame和SQLContext。1. DataFrame
DataFrame是一个分布式的,按照命名列的形式组织的数据集合。与关系型数据库中的数据库表类似。通过调用将DataFrame的内容作为行RDD(RDD of Rows)返回的rdd方法,可以将DataFrame转换成RDD。可以通过如下数据源创建DataFrame:
已有的RDD
结构化数据文件
JSON数据集
Hive表
外部数据库
2. SQL Context
Spark SQL提供SQLContext封装Spark中的所有关系型功能。此外,Spark SQL中的HiveContext可以提供SQLContext所提供功能的超集。可以在用HiveQL解析器编写查询语句以及从Hive表中读取数据时使用。在Spark程序中使用HiveContext无需既有的Hive环境
Spark + Mongo的应用场景
对那些已经使用MongoDB的用户,如果你希望在你的MongoDB驱动的应用上提供个性化功能,比如说像Yahoo一样为你找感兴趣的新闻,能够在你的MongoDB数据上利用到Spark强大的机器学习或者流处理,你就可以考虑在MongoDB集群上部署Spark来实现这些功能。如果你已经使用Hadoop而且数据已经在HDFS里面,你可以考虑使用Spark来实现更加实时更加快速的分析型需求,并且如果你的分析结果有数据量大、格式多变以及这些结果数据要及时提供给前台APP使用的需求,那么MongoDB可以用来作为你分析结果的一个存储方案。
原文:MongoDB + Spark: 完整的大数据解决方案
RDD、DataFrame和DataSet的区别
RDD和DataFrame
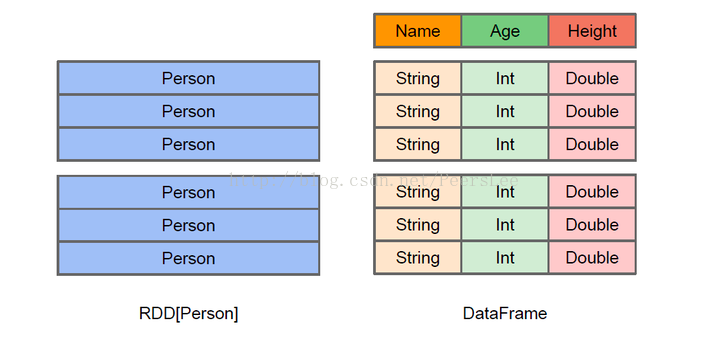
RDD和DataSet

DataFrame和DataSet
Dataset可以认为是DataFrame的一个特例,主要区别是Dataset每一个record存储的是一个强类型值而不是一个Row。因此具有如下三个特点:
原文:RDD、DataFrame和DataSet的区别
练习:根据熊猫TV房间订阅人数对主播进行分类
原始数据为熊猫tv英雄联盟类别直播间信息,共[7257条],部分如下/* 1 */
{
"_id" : ObjectId("58e77b94a9231916402a4d8b"),
"r_id" : "511386",
"r_name" : "柯柯:6K把德莱文电一王者局",
"r_classification" : {
"cname" : "英雄联盟",
"ename" : "lol"
},
"u_name" : "SteinsGate1",
"u_avatar_url" : "http://i7.pdim.gs/1a1399db3dd5dde23d673204c34d3e89.jpeg",
"time" : "2017-04-07 19:44:20",
"u_follower" : 4896
}
/* 2 */
{
"_id" : ObjectId("58e77b94a9231916402a4d8c"),
"r_id" : "419546",
"r_name" : "大根:国服第一龙王!",
"r_classification" : {
"cname" : "英雄联盟",
"ename" : "lol"
},
"u_name" : "龙大大大大大根",
"u_avatar_url" : "http://i6.pdim.gs/4c0a0e43d7956e9dd8aa8c07df6acb7b.png",
"time" : "2017-04-07 19:44:20",
"u_follower" : 91682
}
/* 3 */
{
"_id" : ObjectId("58e77b94a9231916402a4d8d"),
"r_id" : "7000",
"r_name" : "LPL春季赛Snake vs RNG",
"r_classification" : {
"cname" : "英雄联盟",
"ename" : "lol"
},
"u_name" : "LPL熊猫官方直播",
"u_avatar_url" : "http://i5.pdim.gs/4558e050a485b215de8474e3ab64d04e.png",
"time" : "2017-04-07 19:44:20",
"u_follower" : 846436
}从mongodb中读取原始数据之后,根据"u_follower"对主播进行分类,类别如下
100 <-> 1000
1000 <- >1w
1w <-> 10w
10w <-> 100w
100w <-> 1000w
实现如下
import com.mongodb.spark.MongoSpark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.sql.types.{StringType, StructField, StructType}
/**
* Created by peerslee on 17-4-20.
*/
object MongoSQL {
def main(args: Array[String]): Unit = {
// 1. 创建SparkContext -> spark 入口
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("MongoSQL")
.set("spark.mongodb.input.uri", "mongodb://127.0.0.1:27017/lol.panda")
.set("spark.mongodb.output.uri", "mongodb://127.0.0.1:27017/lol")
val sc = new SparkContext(conf)
// 2. 创建SQLContext
val sqlContext = SQLContext.getOrCreate(sc)
// 3. 使用MongoSpark创建Dataframe(其他方式创建见文档)
val df = MongoSpark.load(sqlContext)
// df.show()
// 4. 使用filter根据"u_follower"对直播间进行分类
var border = 100
/*
[rdd => DataFrame]
1. 推断Schema
原理: Spark SQL能够将含Row对象的RDD转换成DataFrame,并推断数据类型
*/
val schemaStr = "id,follower,rank"
val schema = StructType(schemaStr.split(",")
.map(column => StructField(column, StringType, true)))
for(i <- 1 to 5) {
// val rowRdd = df.filter(df("u_follower") > border && df("u_follower") < border*10).show()
/*
2. 指定Schema
2.1 从原来的RDD创建一个元祖或列表的RDD
2.2 用StructType 创建一个和步骤一中创建的RDD中元组或列表的结构相匹配的Schema
2.3 通过SQLContext提供的createDataFrame方法将schema 应用到RDD上
*/
val rowRdd = df.filter(df("u_follower") > border && df("u_follower") < border*10)
.map(room => Row(room(2), room(6).toString, i.toString))
.sortBy(room => room(1).toString.toLong, false)
val rankDF = sqlContext.createDataFrame(rowRdd, schema)
MongoSpark.save(rankDF.write.option("collection", "panda_rank").mode("append"))
border *= 10
}
}
}rank 库共[1771]条数据,部分如下
/* 1 */
{
"_id" : ObjectId("58f84fbfa830984cc36ef9e0"),
"id" : "6666",
"follower" : "3998068",
"rank" : "5"
}/* 1 */
{
"_id" : ObjectId("58f84fbea830984cc36ef9b8"),
"id" : "16666",
"follower" : "974142",
"rank" : "4"
}/* 1 */
{
"_id" : ObjectId("58f84fbea830984cc36ef915"),
"id" : "246868",
"follower" : "99866",
"rank" : "3"
}/* 1 */
{
"_id" : ObjectId("58f84fbea830984cc36ef558"),
"id" : "357838",
"follower" : "9980",
"rank" : "2"
}/* 1 */
{
"_id" : ObjectId("58f84fbda830984cc36ef2fb"),
"id" : "633473",
"follower" : "999",
"rank" : "1"
}等级5的所有主播

参考文档:
MONGODB SPARK CONNECTOR 1.1 Spark SQL
DataFrame

相关文章推荐
- 利用Spark-mllab进行聚类,分类,回归分析的代码实现(python)
- 利用机器学习进行分类(梯度算法)
- 利用class、id对元素进行分类、标识实例
- 在opencv3中利用SVM进行图像目标检测和分类
- 利用机器学习进行恶意代码分类
- 如何利用关联规则进行分类
- 利用工具箱进行分类实验
- 利用CNN进行图像分类学习笔记
- 利用kmeans分类对重庆经济进行分析
- 利用朴素贝叶斯模型进行文档分类
- 利用caffe pre-trained model进行图像分类
- 如何利用libsvm进行分类
- Caffe学习:pycaffe利用caffemodel进行分类
- 利用Excel函数对相同的字段进行分类汇总求平均值
- 利用manifest文件对程序目录下的dll进行分类
- 利用class、id对元素进行分类、标识。
- 机器学习实验报告:利用3层神经网络对CIFAR-10图像数据库进行分类
- Java调用weka.jar利用交叉验证方法进行分类
- 在ENVI进行的土地利用分类数据,需要做景观指数分析,如何将其转换成GRID格式呀
- matlab下利用K-Means进行图像分类