【爬虫】基于R与Python的爬虫基本功(Imdb速8演员表)
2017-04-15 16:31
411 查看
忙到脑废, 刚给老师上交了毕业论文的初稿,趁着这段空闲给我这个人blog开个张。
对于任何数据控来说,网络爬虫约等于一个必要技能。现在上百度一搜,爬虫的代码(尤其是Python的)基本上占满了前三页。 对于吾等非web开发出身的人来说,知道该敲哪个命令,输出什么结果基本上就是够使唤了。 不过,为了保证个人自主性,毕竟这些代码可重复性很差,基本上只适用于那么一个website,还是得需要知道些基本逻辑为好。这篇blog就讲一些爬虫时候的通用步骤(包括R和Python)以及具体的案例来进行辅助分析。
互联网中,每个网站背后都有一个服务器(server)储存着这个网站中包含的所有数据及后台文件。我们浏览的网页实际上就是服务器发来的网页源码然后我们的浏览器将这些源码解析为可读的好看的网页文档,简言之就类似latex源码到pdf文件的过程。 基本上满足这么个流程
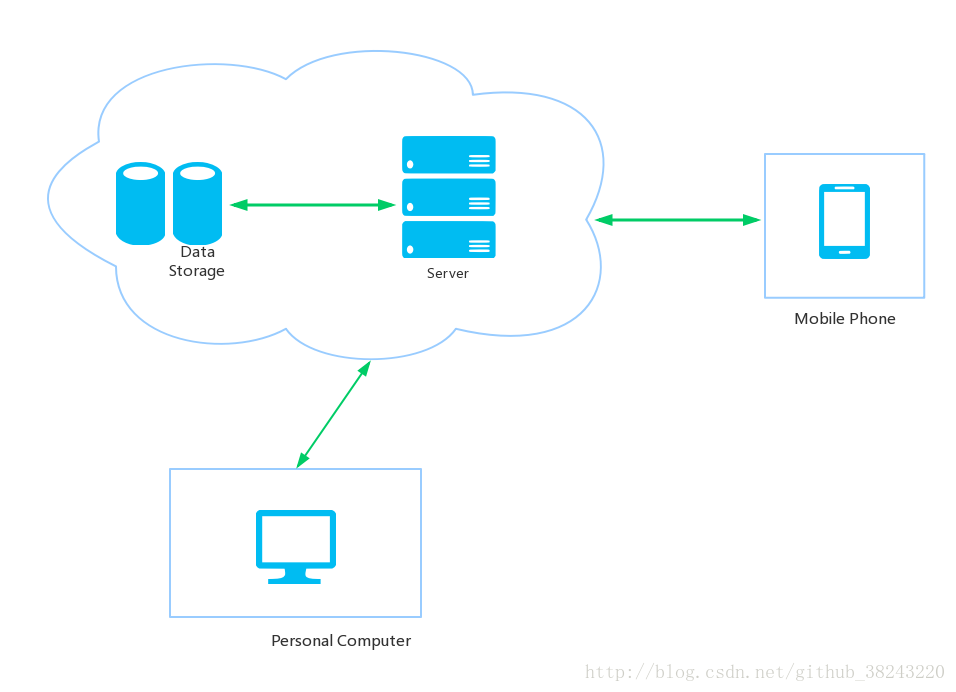
手机(Mobile)和电脑(PC)通过浏览器(browser)向服务器(server)发出请求(request),服务器反馈回来cookies以及网页源码(elements),浏览器解析成我们人眼可直接解读的网页文档,而我们所要爬取的信息基本上就隐藏在这些网页源码里。
在进行爬虫的时候,基本上会发生以下几种情况
网络信号不好,请求发不过去,或源码发不过来,显示获取失败。
请求发送成功,反馈的cookies未检测到,服务器判定你为机器人,不给你反馈网页源码,或者请求过于频繁,也会被服务器判定为机器人。(基本上爬虫失败都是这个原因)
服务器发过来的网页源码不含有我们想要的信息只是一部分js脚本,实际上真实的数据在另一个文件里,从源码不可获得。(很常见的防爬处理,比如说网易云的评论区)
服务器端该网页数据遗失,显示404。
针对第一种情况,这就跟lol里的拔网线debuff一个道理,每人都需要一个健康的上网环境。 对于第二种情况,就要让自己的程序骗过服务器,让服务器认为你是个谷歌浏览器,解决方法是在发出requests的时候设置好head信息。第三种情况就比较麻烦了,需要打开自己的浏览器,从该服务器发过来的缓存文件中找到那个储存着数据的文件(一般是json),然后记录浏览器向哪个网站(并不一定是你在爬的网站)发送的请求,记录下发送的请求参数,最后直接向该网站用该参数发送请求就可以获得数据。
R的话相对Python来说,功能性上会弱一点,也可能是因为大部分人对它的定位一直是统计分析语言很少有人拿它去做一些工程上的事情。所以当百度爬虫的时候,很少会找到关于R的资料或代码,但其实,经过我个人亲身测验,R的
还有好多没截,算上群演的话人估计更多。虽然我相信咱们平时不会那么脑残去找这些东西,但是就这么一个一个抄的还是会挂掉的。首先先看一下人名对应的是哪个网页节点,方法是鼠标在人名上
其他的也是类似的格式,比如说杰森·斯坦森的部分:
我们的工作就是把这部分节点中的那个
R
Package:
Python 3
Package:
Cod
以上的两个代码块已经分别将网页解析完毕并将数据储存在了工作环境中,接下来的步骤是根据正则表达式将符合我们要求的那个节点寻找出来,比较之前列举过的演员名字的在html里的格式,两部分的节点都有一个叫
登录过程简言之就是一个我们人在窗口中输入用户名及密码并手动提交给服务器的过程。也就是登录界面是一个提交信息的“接口”,如果我们的程序可以直接通过这个接口向服务器发送过去用户名及密码等等信息,服务器就会反馈给我们登录成功之后的网页文件。所以现在的问题是如何找到这个“接口”
一时半会儿想不到什么合适的例子,我就拿我们学校的学生个人ICE为例吧,不过在这里我不贡献密码。 首先从登录窗口找到这个所谓的接口。然后下面这个就是我们学生页面。在那个
然后大概会找到这样的注意这个tag:
接着创建handler并向服务器提交用户名及密码等。
一般说,如果最候获取的
原文【爬虫】 基于R与Python的爬虫基础(速8演员表)发布在个人blog(www.zhuifengmu.com)上,欢迎来刷流量,顺便在博客下留下看法。
本来想放一个棘手的案例的(针对某云歌曲评论的防爬处理的),不过时间紧迫,暂时先放个弱智的水一水。
“R不务正业之RCurl”: https://cos.name/cn/topic/17816/.
“Python Web Scrapping”, O’reilly.
对于任何数据控来说,网络爬虫约等于一个必要技能。现在上百度一搜,爬虫的代码(尤其是Python的)基本上占满了前三页。 对于吾等非web开发出身的人来说,知道该敲哪个命令,输出什么结果基本上就是够使唤了。 不过,为了保证个人自主性,毕竟这些代码可重复性很差,基本上只适用于那么一个website,还是得需要知道些基本逻辑为好。这篇blog就讲一些爬虫时候的通用步骤(包括R和Python)以及具体的案例来进行辅助分析。
Introduction
鄙人只是个金融数学系而不是纯正计算机出身,也无兴趣去从事web开发,所以我并没有去从基础上去了解整个互联网是如何搭建服务器又是如何工作,仅仅只是一些勉强符合逻辑的粗浅理解(如果有幸被web开发者看到欢迎补充)。互联网中,每个网站背后都有一个服务器(server)储存着这个网站中包含的所有数据及后台文件。我们浏览的网页实际上就是服务器发来的网页源码然后我们的浏览器将这些源码解析为可读的好看的网页文档,简言之就类似latex源码到pdf文件的过程。 基本上满足这么个流程
手机(Mobile)和电脑(PC)通过浏览器(browser)向服务器(server)发出请求(request),服务器反馈回来cookies以及网页源码(elements),浏览器解析成我们人眼可直接解读的网页文档,而我们所要爬取的信息基本上就隐藏在这些网页源码里。
在进行爬虫的时候,基本上会发生以下几种情况
网络信号不好,请求发不过去,或源码发不过来,显示获取失败。
请求发送成功,反馈的cookies未检测到,服务器判定你为机器人,不给你反馈网页源码,或者请求过于频繁,也会被服务器判定为机器人。(基本上爬虫失败都是这个原因)
服务器发过来的网页源码不含有我们想要的信息只是一部分js脚本,实际上真实的数据在另一个文件里,从源码不可获得。(很常见的防爬处理,比如说网易云的评论区)
服务器端该网页数据遗失,显示404。
针对第一种情况,这就跟lol里的拔网线debuff一个道理,每人都需要一个健康的上网环境。 对于第二种情况,就要让自己的程序骗过服务器,让服务器认为你是个谷歌浏览器,解决方法是在发出requests的时候设置好head信息。第三种情况就比较麻烦了,需要打开自己的浏览器,从该服务器发过来的缓存文件中找到那个储存着数据的文件(一般是json),然后记录浏览器向哪个网站(并不一定是你在爬的网站)发送的请求,记录下发送的请求参数,最后直接向该网站用该参数发送请求就可以获得数据。
Method and Packages
对于Python来说,论网页解析最好的永远是BeautifulSoup,但是说到网页获取,Python 2里常用的是
urllib或者
urllib2,但是在Python 3里,我一直强推
requests库,因为
requests库自带的
session()能自动对应生成cookies,基本上不用担心cookies的匹配问题,意思是,当我们要模拟登录的时候,不需要重复登录。
R的话相对Python来说,功能性上会弱一点,也可能是因为大部分人对它的定位一直是统计分析语言很少有人拿它去做一些工程上的事情。所以当百度爬虫的时候,很少会找到关于R的资料或代码,但其实,经过我个人亲身测验,R的
RCurl包可以实现Python中
requests库的大部分功能。
Case Analysis
这部分就是实例+代码了,既然最近速8刚上映,宣传的那么火,咱就来扒拉扒拉速八的演职员表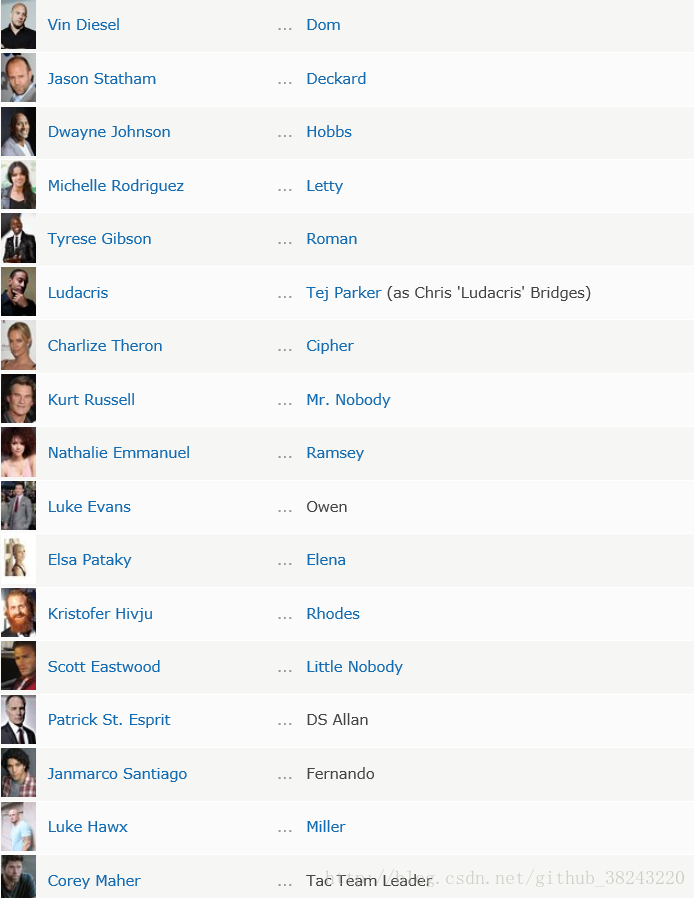 | 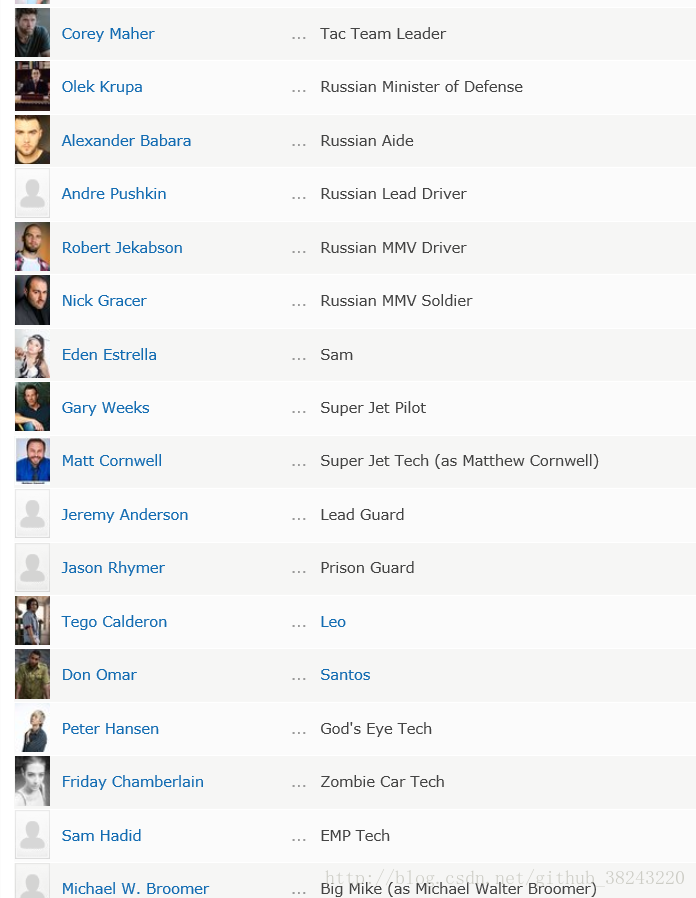 |
右键-检查元素。以男主为例:
<a href="/name/nm0004874/?ref_=ttfc_fc_cl_t1" itemprop="url"> <span class="itemprop" itemprop="name">Vin Diesel</span> ## 名字在这里 -- Vin Diesel </a>
其他的也是类似的格式,比如说杰森·斯坦森的部分:
<a href="/name/nm0005458/?ref_=ttfc_fc_cl_t2" itemprop="url"> <span class="itemprop" itemprop="name">Jason Statham</span> ## 名字在这里 -- Jason Statham </a>
我们的工作就是把这部分节点中的那个
text(人名)部分给全部拿出来。
R
Package:
RCurl(网页获取),
XML(解析网页并提取相对应的节点信息)
Python 3
Package:
requests(网页获取),
BeautifulSoup(解析网页并提取相对应的节点信息)
Cod
4000
e
R:
library(RCurl) library(XML) ## Store the url Url <- 'http://www.imdb.com.cn/title/tt4630562/fullcredits?ref_=tt_cl_sm#cast' ## Get the HTML file html <- getURL(Url) ## Parse the html Tree <- htmlParse(html)```
Python:
import requests from bs4 import BeautifulSoup as bs ## Store the url Url = 'http://www.imdb.com.cn/title/tt4630562/fullcredits?ref_=tt_cl_sm#cast' ## Get the HTML document html_doc = requests.request(method='get',url=Url) ## Parse the html by using BeautifulSoup Soup = bs(html_doc.content, features="lxml")
以上的两个代码块已经分别将网页解析完毕并将数据储存在了工作环境中,接下来的步骤是根据正则表达式将符合我们要求的那个节点寻找出来,比较之前列举过的演员名字的在html里的格式,两部分的节点都有一个叫
itemprop的attr,都属于
a这个tag。仔细观察的话其他的演员也是类似的格式,所以我们就通过这两个特征tag:
a和attr:
itemprop来进行初步定位。 除此之外,人名处于一个叫
span的tag并含有一个attr:
class='itemprop'。
R:
R中的xml包可以让我们直接通过节点路径寻找到人名所在那类节点
## Get the node of name lis <- getNodeSet(Tree,path = "//a[@itemprop='url']//span[@class='itemprop']") ## Get the name list Name <- sapply(lis, FUN = xmlValue) print(Name) #[1] <span class="itemprop" itemprop="name">Vin Diesel</span> #[2] <span class="itemprop" itemprop="name">Jason Statham</span> #[3] <span class="itemprop" itemprop="name">Dwayne Johnson</span> ...
Python
Python 可以通过正则表达式定位某个attrs,比如说我们定位href中的
/name/nm0004874/?ref_=ttfc_fc部分。
import re
## Compile the regular expression matching '/name/nm0004874/?ref_=ttfc_fc'
href_re = re.compile(pattern="/name/nm[0-9]{7}/\?ref_=ttfc")
## Find the tag 'a' which have the particular form
soup1 = Soup.find_all('a', attrs={"href":href_re,"itemprop":"url"})
## Extract the text
name = [var.get_text().strip() for var in soup1]
print(soup1)
#<a href="/name/nm0004874/?ref_=ttfc_fc_cl_t1" itemprop="url"> <span class="itemprop" itemprop="name">Vin Diesel</span></a>
#<a href="/name/nm0005458/?ref_=ttfc_fc_cl_t2" itemprop="url"> <span class="itemprop" itemprop="name">Jason Statham</span></a>
#<a href="/name/nm0425005/?ref_=ttfc_fc_cl_t3" itemprop="url"> <span class="itemprop" itemprop="name">Dwayne Johnson</span></a>
#<a href="/name/nm0735442/?ref_=ttfc_fc_cl_t4" itemprop="url"> <span class="itemprop" itemprop="name">Michelle Rodriguez</span></a>
...Result:
输出的结果前十位为Name: [1] "Vin Diesel" [2] "Jason Statham" [3] "Dwayne Johnson" [4] "Michelle Rodriguez"
[5] Tyrese Gibson" [6] "Ludacris" [7] "Charlize Theron" [8] "Kurt Russell" [9] "Nathalie Emmanuel" [10] "Luke Evans"...版面限制就显示10个吧。
模拟登录
有些时候,当我们想要读取某网站的数据的时候是需要先行登录的。平时用Chrome的时候登录过一次以后,浏览器保留了服务器反馈的cookie,再直接打开该网站子界面的时候跳过了登录阶段,但是这不代表我们重新编写的脚本也可以直接跳过登录阶段,所以,如果要爬取的网页需要登录的话我们就需要让程序自己登录,不然最终获得的页面也只是一个登录页面。登录过程简言之就是一个我们人在窗口中输入用户名及密码并手动提交给服务器的过程。也就是登录界面是一个提交信息的“接口”,如果我们的程序可以直接通过这个接口向服务器发送过去用户名及密码等等信息,服务器就会反馈给我们登录成功之后的网页文件。所以现在的问题是如何找到这个“接口”
一时半会儿想不到什么合适的例子,我就拿我们学校的学生个人ICE为例吧,不过在这里我不贡献密码。 首先从登录窗口找到这个所谓的接口。然后下面这个就是我们学生页面。在那个
log in那块
右键-检查元素。
然后大概会找到这样的注意这个tag:
form后面紧跟了一个attr:
action,这个action后面的那个地址就是我们实际登录时向服务器发送用户名及密码的网址。所以如果我们想让程序自己登录,就写几行代码向这个地址发送你的个人账号及密码
<form action="https://ice.xjtlu.edu.cn/login/index.php" method="post" id="login" autocomplete="off">
<div class="loginform">
<div class="form-label"><label for="username">Username</label></div>
<div class="form-input">
<!-- START: XJTLU ADDITION 30/03/2017 - add placeholder element to username and password input fields
<input type="text" name="username" id="username" size="15" value="" /> -->
<input type="text" name="username" placeholder="Username" id="username" size="15" value="">
<!-- START: XJTLU ADDITION 30/03/2017 -->
</div>
<div class="clearer"><!-- --></div>
<div class="form-label"><label for="password">Password</label></div>
<div class="form-input">
<!-- START: XJTLU ADDITION 30/03/2017 - add placeholder element to username and password input fields
<input type="password" name="password" id="password" size="15" value="" autocomplete="off" /> -->
<input type="password" name="password" placeholder="Password" id="password" size="15" value="" autocomplete="off">
<!-- START: XJTLU ADDITION 30/03/2017 -->
</div>
</div>
<div class="clearer"><!-- --></div>
<div class="clearer"><!-- --></div>
<input id="anchor" type="hidden" name="anchor" value="">
<script>document.getElementById('anchor').value = location.hash</script>
<input type="submit" id="loginbtn" value="Log in">
<div class="forgetpass"><a href="forgot_password.php">Problems logging in?</a></div>
</form>Simulated Login (R)
在R中,我们通过使用Rcurl来向服务器发送请求,为了避免服务器将我们认为是机器人,所以我们提前准备好几个
httpheader(Python同理。不过目前来看Python模拟登录莫名一直很顺利)。先从自己常用的浏览器里抄下
requests header
myheader <- c( "User-Agent"="Mozilla/5.0 (Windows NT 10.0; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0", "Accept"="text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Language"="zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3", "Connection"="keep-alive", "Accept-Charset"="GB2312,utf-8;q=0.7,*;q=0.7" )
接着创建handler并向服务器提交用户名及密码等。
params <- list("username"="YourUserName",
"password"="YourPassword")
## Set the curl option
cHandle <- getCurlHandle(httpheader=myheader,debugfunction=d$update)
## POST your requests to the server
postForm('https://ice.xjtlu.edu.cn/login/index.php',.params = params,.opts = list(cookiefile=""),curl = cHandle,style = "POST")
## Test whether you've logged in(进入该网站子界面来检测是否可以获取)
Html_doc <- getURL('ice.xjtlu.edu.cn',curl=cHandle)
## 之后用XML包来解析Html_doc就OK了一般说,如果最候获取的
Html_doc足够长的话,说明已经登录而且服务器也给你反馈了。 然而这时候就想吐槽一下R了,这函数有点不太稳定,个人觉的应该是因为header容易被封。所以建议多准备几个header。相对来说
Python就稳定很多了。
Simulated Login (Python)
Python的requests库在post requests方面非常有统治力,稳定性比R强(原因未知),主要用到
requests.post方法。
## Login
import requests
uri = 'https://ice.xjtlu.edu.cn/login/index.php'
param = {"username":"Your User Name",
"password":"Your Password"}
## Post the username and password
res = requests.post(uri, data=param)
## The Html File
Html_doc = res.text
print(Html_doc)
## 之后用BeautifulSoup来解析Html_doc就好啦总结
就我个人来说,我爬虫的时候Python和R都实验过,而且作为一个忠实的R党,我对R的在这块的功能花的精力更多一点。不过我还是不得不承认,Python的功能还是强于R,就模拟登录学校官网这个过程,用R基本上每次都要换一个header,而且成功率比较低,有时候还有关键词冲突,Python就没这些恶心人的问题,不过考虑到R语言数据结构比较少还简单,受点限制也是可以理解的,而且考虑到R语言不错的数据可视化功能,我也就不那么纠结了,大不了用Python抓网页然后R语言来解析就行了。原文【爬虫】 基于R与Python的爬虫基础(速8演员表)发布在个人blog(www.zhuifengmu.com)上,欢迎来刷流量,顺便在博客下留下看法。
本来想放一个棘手的案例的(针对某云歌曲评论的防爬处理的),不过时间紧迫,暂时先放个弱智的水一水。
Reference
“R语言爬虫之——RCurl”: http://www.w2bc.com/Article/28489.“R不务正业之RCurl”: https://cos.name/cn/topic/17816/.
“Python Web Scrapping”, O’reilly.

相关文章推荐
- 基于Python的urllib2模块的多线程网络爬虫程序
- 基于python的豆瓣“我看过的电影”的爬虫
- 基于python的爬虫---自顶向下的设计思想
- 一个基于python的数据爬虫
- 简单的python2.7基于bs4和requests的爬虫
- 一种基于迭代与分类识别方法的入门级Python爬虫
- python基于web.py的爬虫站点
- 基于python实现的抓取腾讯视频所有电影的爬虫
- 基于python实现的抓取腾讯视频所有电影的爬虫
- 利用python写一个简易的爬虫,基于慕课网对应课程
- 基于python的一个大规模爬虫遇到的一些问题总结
- 基于python的爬虫
- Python 基于学习 网络小爬虫
- python爬虫——基于selenium用火狐模拟登陆爬搜索关键词的微博
- 使用Python编写基于DHT协议的BT资源爬虫
- 基于python的简单爬虫
- 基于Python,scrapy,redis的分布式爬虫实现框架
- 基于python和amap(高德地图)web api的爬虫,用于搜索某POI点
- 基于正则表达式(python)对东方财富网上证指数吧爬虫实例
- Python实现基于协程的异步爬虫(一)