java爬虫实战(2):下载沪深信息科技类上市公司年度报告
2017-04-07 16:12
393 查看
java爬虫实战(2):下载沪深信息科技类上市公司年度报告
*本实战仅作为学习和技术交流使用,转载请注明出处;本篇实战来源于一位朋友需要进行学术研究,涉及数据内容是2010年-2016年的沪深主板上市信息科技类公司年报,由于并没有现成的数据源,百度之后发现“巨潮咨询网(http://www.cninfo.com.cn/)”中含有所需信息,但需要自己手动下载,工程量大。因此,程序作为提高效率的工具,它的价值就在此。
java爬虫实战2下载沪深信息科技类上市公司年度报告
HttpURLConnection
通过POST方式获取JSON
通过GET请求获取文件
JSON-Lib
线程池同步
源代码
DownLoadThreadjar
DownLoadJsonjava
DownLoadFilejar
DownloadMainjava
截图
HttpURLConnection
Java网络编程中经常使用的网络连接类库无疑是HttpClient和HttpURLConnection, 其种HttpURLConnection能实现的,HttpClient都能实现,简单说来HttpCilent是近似于HttpURLConnection的封装。具体二者的区别将另外用一篇博文进行讲解。鉴于本次数据下载只有提交请求及获取Response数据,因此用HttpURLConnection足够。首先分析目标网站请求响应情况
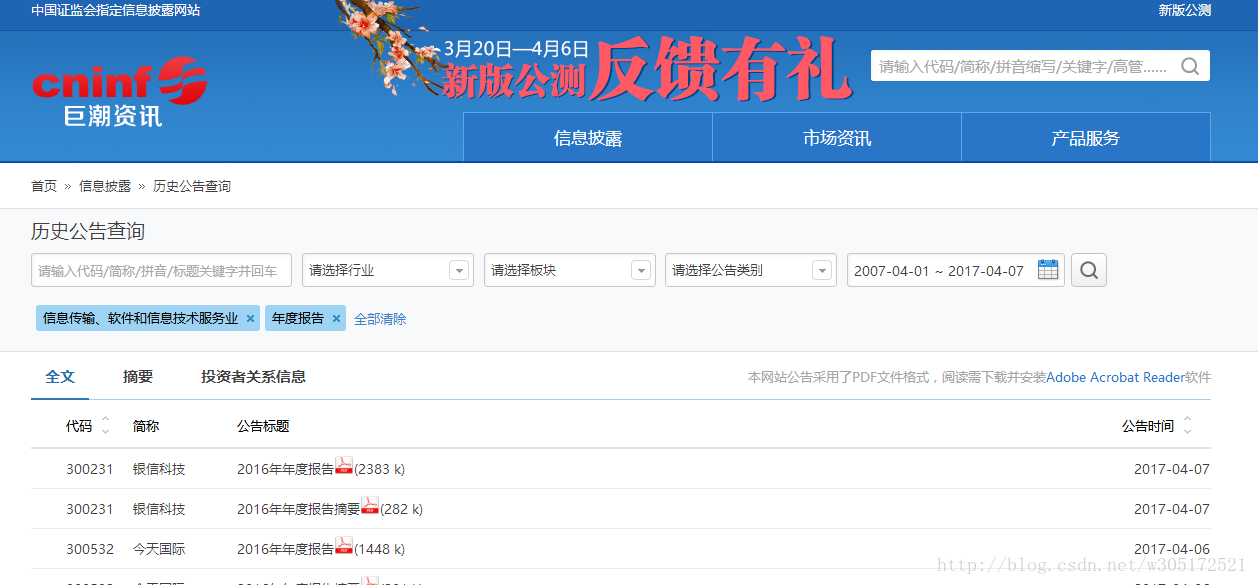
该搜索页面已经提供了详细的搜索条件,选择相应的条目,选择搜索之后,页面通过JQuery的AJAX进行请求封装,而每次页面仅显示30条记录,选择下页将再次触发AJAX请求,进行页面的异步刷新。同时,利用浏览器的调试器中Network可以发现,每次页面请求为POST请求,返回的则是一个JSON对象;JSON对象中包含了下载文件链接的必要参数。到此可知本次下载主要分两个过程:
1.通过POST方式获取到查询结果的所有JSON对象;
2.提取JSON对象中的相应参数,构造下载URL字段;
3.通过GET方式下载文件;
通过POST方式获取JSON
查看网页请求中的post参数,主要有category,trade,pagenum, pageSize,showTitle,seDate等,因此可以根据参数构造post请求。在HttpURLConnection中post请求实质是一个字符串,因此可以按照如下构造请求Content:String content = "stock=&searchkey=&plate=&category=category_ndbg_szsh;&trade="+URLEncoder.encode("信息传输、软件和信息技术服务业;", "utf-8")+"&column=szse&columnTitle="+URLEncoder.encode("历史公告查询","utf-8")+"&pageNum="+pagenum+"&pageSize=30&tabName=fulltext&sortName=code&sortType=asc&limit=&showTitle="+URLEncoder.encode("信息传输、软件和信息技术服务业/trade/信息传输、软件和信息技术服务业;category_ndbg_szsh/category/年度报告&seDate=请选择日期","utf-8");此处使用了URLEncoder解决url地址中的中文编码问题,在网络编程中也是最常使用的。
URLDecoder.decode("测试", "UTF-8");//解码
URLEncoder.encode("测试", "UTF-8");//编码之后便是构造POST请求的代码
URL url = new URL(urlStr);//利用urlStr字符串构造URL对象
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
conn.setConnectTimeout(50000);//设置超时
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36");//设置请求头部User-Agent,防止对方服务器屏蔽程序
//设置post,HttpURLConnection的post设置
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setRequestMethod("POST");
conn.setUseCaches(false);
conn.setInstanceFollowRedirects(true);
conn.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
conn.setChunkedStreamingMode(5);提交post请求
conn.connect(); DataOutputStream out = new DataOutputStream(conn.getOutputStream());//封装conn的post字节流 //发送post请求 out.writeUTF(content); out.flush(); out.close();
获取Response,即JSON数据流
InputStream inputStream = conn.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(inputStream,"UTF-8"));//此处利用InputStreanReader()对返回的字节流做了utf-8编码处理,正是为了完美解决中文乱码问题,利用BufferedReaeder进行流读取,也是java最常见的多写方式
while((line=br.readLine())!=null){
bw.append(line);//bw = new BufferedWriter(new FileWriter("file"));
}通过GET请求获取文件
假设我们用JSON-Lib(下节介绍)已经处理返回的JSON文件,并得到想要的参数构造了GET请求的url地址,此时发起HttpURLConnection的GET请求:URL url = new URL(urlStr);//urlStr此时为get请求url
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
conn.setConnectTimeout(500000);
conn.setRequestProperty("User-Agent",
4000
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36");//同post请求
//通过连接头部截取文件名
String contentDisposition = new String(conn.getHeaderField("Content-Disposition").getBytes("ISO-8859-1"), "GBK");//获取中文文件名
contentDisposition = URLDecoder.decode(contentDisposition,"utf-8");
String filename = contentDisposition.substring(contentDisposition.indexOf('\"') + 1, contentDisposition.lastIndexOf("\""));
//保存文件
File saveDir = new File(savePath);
if(!saveDir.exists())
saveDir.mkdir();
filename = filename.replace("*", "");
File file = new File(saveDir+File.separator+filename);
FileOutputStream fos = null;
InputStream inputStream = null;
if(!file.exists()){
inputStream = conn.getInputStream();
System.out.println(filename);
byte[] getData = readInputStream(inputStream);//此处采用ByteArrayOutputStream方式进行流的写,同样用其他流读写也可以,如BuffedWriter,同上
fos = new FileOutputStream(file);
fos.write(getData);
//readInutStream function
public static byte[] readInputStream(InputStream inputStream) throws IOException {
byte[] buffer = new byte[1024];
int len = 0;
ByteArrayOutputStream bos = new ByteArrayOutputStream();
while((len = inputStream.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
bos.close();
return bos.toByteArray();
}至此,利用HttpURLConnection已经解决了模拟POST和GET请求
JSON-Lib
JSON-Lib是java常用的解析json或者json文件转换的工具包,类似的工具类jar包很多,可以上Apache官网上找。使用JSON-Lib较为简单,这也是本项目的原则。JSON-Lib现在版本已经2.4,但引用它前,需要导入相应的jar包(如果运行出错,基本是关联jar包版本不对,建议下个旧版的)
json-lib-2.4-jdk15.jar commons-beanutils-1.9.3.jar commons-logging-1.2.jar ezmorph-1.0.6.jar commons-lang-2.6.jar commons-collections-3.2.1.jar
此处仅介绍JSON-Lib解析json字符串命令,代码如下
public static List<String> parse(String jsonstring){
JSONObject jb = JSONObject.fromObject(jsonstring);//通过json字符串获取到json对象
JSONArray ja = jb.getJSONArray("announcements"); //截取json对象中的某个属性,封装成k-v数组
String pre = "http://three.cninfo.com.cn/new/announcement/download";//目标网站下载链接的get请求前缀,最后url = pre+"?bulletinId="+id+"&announceTime="+t;
try{
for(int i=0;i<ja.size();i++){
String id = ja.getJSONObject(i).getString("announcementId");//获取id
SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd");//格式化时间
String time = ja.getJSONObject(i).getString("announcementTime");
String title = ja.getJSONObject(i).getString("announcementTitle");
String secname = ja.getJSONObject(i).getString("secName");
if(title.contains("摘要")||title.contains("2009"))//剔除不需要的对象
continue;
long l = new Long(time);
Date date = new Date(l);
String t = formatter.format(date);//2017-04-02格式化
String result = pre+"?bulletinId="+id+"&announceTime="+t;
url.add(result);//保存构造的url,此处url为List<String>对象
}}catch(Exception e){
e.printStackTrace();
}
return url;
}线程池,同步
为了让程序充分利用cpu(虽然加重对方服务器压力),开启多线程,同时对相应的GET请求的url进行同步操作。此处采用java中的线程池完成并发。首先构造基础的线程类DownloadThread,实现Runnable接口
public class DownloadThread implements Runnable{
public List<String> url;//get请求的url
private int index = 0;
public DownloadThread(List<String> l,int i){//构造函数,传入url集合,以及同步需要同步的信号量index,该index指代url list中的第i条记录
url = l;
index = i;
}
public DownloadThread(int i){//测试使用
index = i;
}
@Override
public void run() {
synchronized(this){
index++;//同步index,保证多线程在遍历url list时候不重复遍历
}
DownLoadFile.downloadFile(url.get(index),"AnnualReport//");//调用静态函数downloadFile(par1,par2)开始下载,par1为urlStr,par2为文件保存目录
System.out.println(Thread.currentThread().getName()+":"+index);
}
}java提供了四种线程池的实现方式(后续会深入java线程池原理),包括
newCachedThreadPool:创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。 newFixedThreadPool:创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。 newScheduledThreadPool:创建一个定长线程池,支持定时及周期性任务执行。 newSingleThreadExecutor:创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行
本实例采用newFixedThreadPool创建一个定长的线程池,线程池大小为5
DownloadThread t = new DownloadThread(url,-1);//实例化自定义的线程类DownloadThread
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(5); //线程池打开
for (int i=0;i < 1430; i++) { //1430为此次下载文件的总个数,意味让线程执行1430次run函数
fixedThreadPool.execute(t); //将自定义线程交由线程池让调度和管理
}本实战至此已经完成了主要的逻辑部分的介绍,下面贴出项目的所有源代码。
源代码
DownLoadThread.jar
import java.util.List;
public class DownloadThread implements Runnable{
public List<String> url;
private int index = 0;
public DownloadThread(List<String> l,int i){
url = l;
index = i;
}
public DownloadThread(int i){
index = i;
}
@Override
public void run() {
synchronized(this){
index++;
}
DownLoadFile.downloadFile(url.get(index),"AnnualReport//");
System.out.println(Thread.currentThread().getName()+":"+index);
}
}DownLoadJson.java
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLDecoder;
import java.net.URLEncoder;
public class DownLoadJson {
public static int totalAnnouncement = 0;
public static BufferedWriter bw = null;
/* 下载 url 指向的网页 */
public static void downloadFile(String urlStr,int pagenum) {
try{
URL url = new URL(urlStr);
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
conn.setConnectTimeout(50000);
//防止屏蔽程序抓取而返回403错误
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36");
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setRequestMethod("POST");
conn.setUseCaches(false);
conn.setInstanceFollowRedirects(true);
conn.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
conn.setChunkedStreamingMode(5);
conn.connect();
DataOutputStream out = new DataOutputStream(conn.getOutputStream());
String content = "stock=&searchkey=&plate=&category=category_ndbg_szsh;&trade="+URLEncoder.encode("信息传输、软件和信息技术服务业;", "utf-8")
+"&column=szse&columnTitle="+URLEncoder.encode("历史公告查询","utf-8")+"&pageNum="+pagenum+"&pageSize=30&tabName=fulltext&sortName=code&sortType=asc&limit=&showTitle="
+URLEncoder.encode("信息传输、软件和信息技术服务业/trade/信息传输、软件和信息技术服务业;category_ndbg_szsh/category/年度报告&seDate=请选择日期","utf-8");
out.writeUTF(content);
out.flush();
out.close();
f1c1
/*Map<String,List<String>> map = conn.getHeaderFields();
for(String s:map.keySet()){
for(String t:map.get(s))
System.out.println(s+":"+t);
}*/
InputStream inputStream = conn.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(inputStream,"UTF-8"));
String line = null;
while((line=br.readLine())!=null){
line = line.replace("“", "\'");
line = line.replace("”", "\'");
//line = new String(line.getBytes("GBK"),"UTF-8");
bw.append(URLDecoder.decode(line, "utf-8"));
bw.append("\n");
}
/*byte[] getData = readInputStream(inputStream);
File saveDir = new File(savePath);
if(!saveDir.exists())
saveDir.mkdir();
File file = new File(saveDir+File.separator+"json");
FileOutputStream fos = new FileOutputStream(file);
fos.write(getData);
if(fos!=null){
fos.close();
}
if(inputStream!=null){
inputStream.close();
} */
}catch(Exception e){
e.printStackTrace();
}
}
public static byte[] readInputStream(InputStream inputStream) throws IOException {
byte[] buffer = new byte[1024];
int len = 0;
ByteArrayOutputStream bos = new ByteArrayOutputStream();
while((len = inputStream.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
bos.close();
return bos.toByteArray();
}
public static void main(String[] args){
try{
totalAnnouncement = 2880;
bw = new BufferedWriter(new FileWriter("json//json",true));
for(int i=1;i<totalAnnouncement/30+2;i++){
downloadFile("http://www.cninfo.com.cn/cninfo-new/announcement/query",i);
System.out.println(i);
}
bw.flush();
bw.close();
}catch(Exception e){
e.printStackTrace();
}
}
}DownLoadFile.jar
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLDecoder;
public class DownLoadFile {
/* 下载 url 指向的网页 */
public static void downloadFile(String urlStr, String savePath) {
try{
URL url = new URL(urlStr);
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
conn.setConnectTimeout(500000);
//防止屏蔽程序抓取而返回403错误
conn.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
// 文件名
String contentDisposition = new String(conn.getHeaderField("Content-Disposition").getBytes("ISO-8859-1"), "GBK");
contentDisposition = URLDecoder.decode(contentDisposition,"utf-8");
String filename = contentDisposition.substring(contentDisposition.indexOf('\"') + 1, contentDisposition.lastIndexOf("\""));
File saveDir = new File(savePath);
if(!saveDir.exists())
saveDir.mkdir();
filename = filename.replace("*", "");
File file = new File(saveDir+File.separator+filename);
FileOutputStream fos = null;
InputStream inputStream = null;
if(!file.exists()){
inputStream = conn.getInputStream();
System.out.println(filename);
byte[] getData = readInputStream(inputStream);
fos = new FileOutputStream(file);
fos.write(getData);
}
if(fos!=null){
fos.close();
}
if(inputStream!=null){
inputStream.close();
}
}catch(Exception e){
e.printStackTrace();
}
}
public static byte[] readInputStream(InputStream inputStream) throws IOException {
byte[] buffer = new byte[1024];
int len = 0;
ByteArrayOutputStream bos = new ByteArrayOutputStream();
while((len = inputStream.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
bos.close();
return bos.toByteArray();
}
}DownloadMain.java
import java.io.BufferedReader;
import java.io.FileReader;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
public class DownloadMain {
public static List<String> json = new ArrayList<String>();
public static List<String> url = new ArrayList<String>();
public static List<String> parse(String jsonstring){
JSONObject jb = JSONObject.fromObject(jsonstring);
JSONArray ja = jb.getJSONArray("announcements");
String pre = "http://three.cninfo.com.cn/new/announcement/download";
try{
for(int i=0;i<ja.size();i++){
String id = ja.getJSONObject(i).getString("announcementId");
SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd");
String time = ja.getJSONObject(i).getString("announcementTime");
String title = ja.getJSONObject(i).getString("announcementTitle");
String secname = ja.getJSONObject(i).getString("secName");
if(title.contains("摘要")||title.contains("2009"))
continue;
long l = new Long(time);
Date date = new Date(l);
String t = formatter.format(date);
String result = pre+"?bulletinId="+id+"&announceTime="+t;
url.add(result);
System.out.println(secname+":"+title);
}}catch(Exception e){
e.printStackTrace();
}
//System.out.println(ja.size());
return url;
}
public static void readFile(String file){
try{
BufferedReader br = new BufferedReader(new FileReader(file));
String str = br.readLine();
while(str!=null){
json.add(str);
str = br.readLine();
}
}catch(Exception e){
e.printStackTrace();
}
}
public static void main(String[] args){
//下载pdf
readFile("json/json");
for(String s:json)
parse(s);
DownloadThread t = new DownloadThread(url,-1);
System.out.println(t.url.size());
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(5);
for (int i=0;i < 1430; i++) {
fixedThreadPool.execute(t);
}
/*for(String s:url){
DownLoadFile.downloadFile(s,"AnnualReport//");
}*/
}
}截图


相关文章推荐
- java爬虫实战(1):抓取信息门户网站中的图片及其他文件并保存至本地
- java爬虫框架——jsoup的简单使用(爬取电影天堂的所有电影的信息,包括下载的链接)
- Java爬虫实战(二):抓取一个视频网站上2015年所有电影的下载链接
- Java爬虫实战(二):抓取一个视频网站上2015年所有电影的下载链接
- Java爬虫,信息抓取的实现
- Python爬虫框架Scrapy实战之定向批量获取职位招聘信息
- 基于Java的简单网络爬虫的实现--下载Silverlight视频
- java网络爬虫——下载页面图片
- [零基础学JAVA]Java SE实战开发-37.MIS信息管理系统实战开发[JDBC](3) 推荐
- JAVA 语言客户信息管理系统解题报告
- Java爬虫,信息抓取的实现
- [零基础学JAVA]Java SE实战开发-37.MIS信息管理系统实战开发[JDBC](2) 推荐
- Java爬虫,信息抓取的实现(Jsoup)转载,仅用于学习
- Java爬虫,信息抓取的实现
- 多线程爬虫Java调用wget下载文件,独立线程读取输出缓冲区
- Java广度优先爬虫示例(抓取复旦新闻信息)
- Java下载文件 爬虫 超时处理解决方案
- [零基础学JAVA]Java SE实战开发-37.MIS信息管理系统实战开发[JDBC](1) 推荐
- java 网页爬虫(以扒取amazon网页信息为例)
- Python爬虫框架Scrapy实战教程---定向批量获取职位招聘信息