Keepalived+Nginx实现高可用(HA)
2017-04-05 22:16
387 查看
keepalived的HA分为抢占模式和非抢占模式,抢占模式即MASTER从故障中恢复后,会将VIP从BACKUP节点中抢占过来。非抢占模式即MASTER恢复后不抢占BACKUP升级为MASTER后的VIP。下面分别介绍CentOS7下抢占模式和非抢占模式的配置方式:
两台服务器的VIP为:192.168.1.210
分别在两台WEB服务器安装nginx和keepalived:
1、安装Nginx,请参考《Nginx源码安装》
2、安装Keepalived,请参考《Keepalived安装与配置》
3、防火墙添加arrp组播规则,或关闭防火墙
1> iptables
2

1
2
2> firewall
2
1
2
4、关闭selinux
2
3
4

1
2
3
4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
9
2
3
4
5
6
1
2
3
4
5
6
如果看到如上进程信息,表示keepalived已经启动成功。下面用
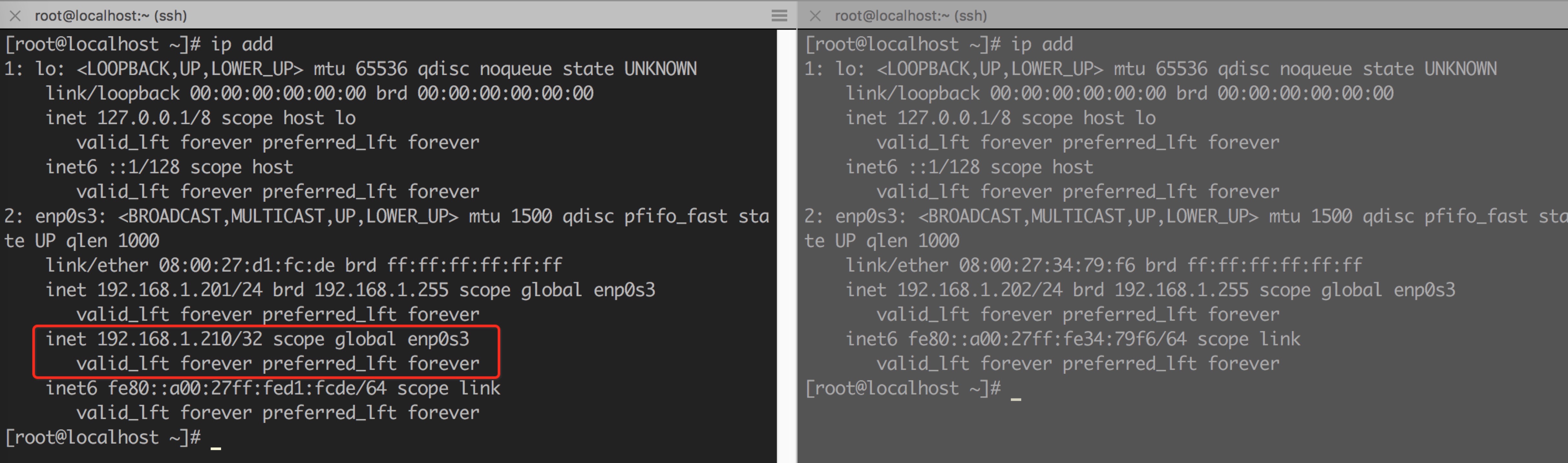
从上图可以看出,vip地址192.168.1.210绑定在MASTER(192.168.1.201)的enp0s3网卡上。
停止201的keepalived服务:
2
1
2
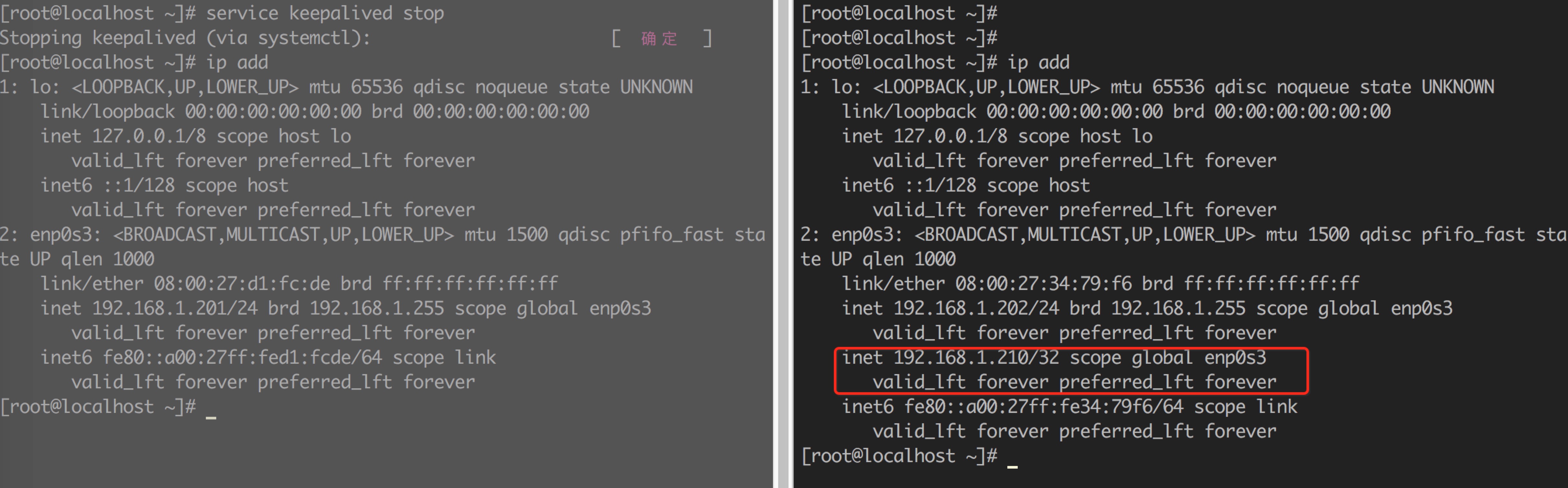
从上图可以看出,vip已经成功从201漂移到了202。此时再将201的keepalived服务启动后,由于201是MASTER,所以会将202的VIP抢占过来。
启动201的keepalived服务:
1
结果VIP又回到了201,如下图所示:
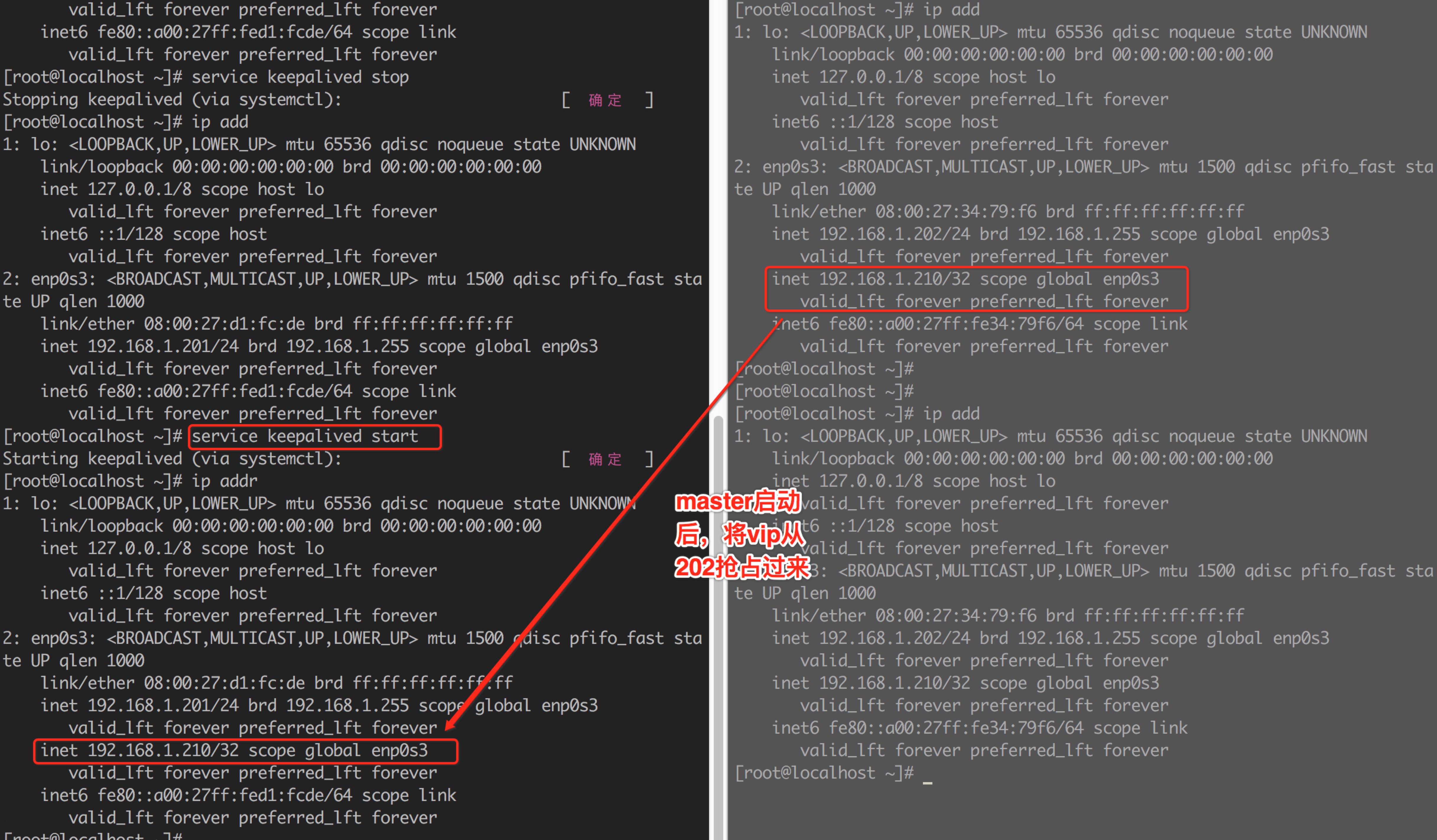
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
和非抢占模式的配置相比,只改了两个地方:
1> 在vrrp_instance块下两个节点各增加了nopreempt指令,表示不争抢vip
2> 节点的state都为BACKUP
两个keepalived节点都启动后,默认都是BACKUP状态,双方在发送组播信息后,会根据优先级来选举一个MASTER出来。由于两者都配置了nopreempt,所以MASTER从故障中恢复后,不会抢占vip。这样会避免VIP切换可能造成的服务延迟。
1、方案规划
| VIP | IP | 主机名 | Nginx端口 |
|---|---|---|---|
| 192.168.1.210 | 192.168.1.201 | nginx-01 | 80 |
| 192.168.1.210 | 192.168.1.202 | nginx-02 | 80 |
分别在两台WEB服务器安装nginx和keepalived:
1、安装Nginx,请参考《Nginx源码安装》
2、安装Keepalived,请参考《Keepalived安装与配置》
3、防火墙添加arrp组播规则,或关闭防火墙
1> iptables
shell> vi /etc/sysconfig/iptables -A INPUT -p vrrp -d 224.0.0.18/32 -j ACCEPT1
2
1
2
2> firewall
firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 --in-interface enp4s0 --destination 224.0.0.18 --protocol vrrp -j ACCEPT firewall-cmd --reload1
2
1
2
4、关闭selinux
shell> vi /etc/sysconfig/selinux #修改: SELINUX=disabled #setenforce 01
2
3
4
1
2
3
4
2、抢占模式配置
编辑/etc/keepalived/keepalived.conf配置文件
1> MASTER(192.168.1.201):
global_defs {
router_id nginx_01 #标识本节点的名称,通常为hostname
}
## keepalived会定时执行脚本并对脚本执行的结果进行分析,动态调整vrrp_instance的优先级。
##如果脚本执行结果为0,并且weight配置的值大于0,则优先级相应的增加。如果脚本执行结果非0,
##并且weight配置的值小于 0,则优先级相应的减少。其他情况,维持原本配置的优先级,即配置文件中priority对应的值。
vrrp_script chk_nginx {
script "/etc/keepalived/nginx_check.sh"
interval 2 #每2秒检测一次nginx的运行状态
weight -20 #失败一次,将自己的优先级-20
}
vrrp_instance VI_1 {
state MASTER # 状态,主节点为MASTER,备份节点为BACKUP
interface enp0s3 # 绑定VIP的网络接口,通过ifconfig查看自己的网络接口
virtual_router_id 51 # 虚拟路由的ID号,两个节点设置必须一样,可选IP最后一段使用,相同的VRID为一个组,他将决定多播的MAC地址
mcast_src_ip 192.168.1.201 # 本机IP地址
priority 100 # 节点优先级,值范围0~254,MASTER要比BACKUP高
advert_int 1 # 组播信息发送时间间隔,两个节点必须设置一样,默认为1秒
# 设置验证信息,两个节点必须一致
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟IP,两个节点设置必须一样。可以设置多个,一行写一个
virtual_ipaddress {
192.168.1.210
}
track_script {
chk_nginx # nginx存活状态检测脚本
}
}12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2> BACKUP(192.168.1.202)
global_defs {
router_id nginx_02
}
vrrp_script chk_nginx {
script "/etc/keepalived/nginx_check.sh"
interval 2
weight -20
}
vrrp_instance VI_1 {
state BACKUP
interface enp0s3
virtual_router_id 51
mcast_src_ip 192.168.1.202
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.210
}
track_script {
chk_nginx
}
}12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
3> 创建nginx服务检测脚本
分别在主备服务器/etc/keepalived目录下创建
nginx_check.sh脚本,并为其添加执行权限
chmod +x /etc/keepalived/nginx_check.sh。用于keepalived定时检测nginx的服务状态,如果nginx停止了,会尝试重新启动nginx,如果启动失败,会将keepalived进程杀死,将vip漂移到备份机器上。
#!/bin/bash A=`ps -C nginx --no-header | wc -l` if [ $A -eq 0 ];then /opt/nginx/sbin/nginx #尝试重新启动nginx sleep 2 #睡眠2秒 if [ `ps -C nginx --no-header | wc -l` -eq 0 ];then killall keepalived #启动失败,将keepalived服务杀死。将vip漂移到其它备份节点 fi fi1
2
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
9
4> 启动keepalived服务
shell> service keepalived start shell> ps -ef | grep keepalived [root@localhost ~]# ps -ef | grep keepalived root 865 1 0 23:36 ? 00:00:00 keepalived -D root 869 865 0 23:36 ? 00:00:00 keepalived -D root 870 865 0 23:36 ? 00:00:00 keepalived -D1
2
3
4
5
6
1
2
3
4
5
6
如果看到如上进程信息,表示keepalived已经启动成功。下面用
ip add命令查看vip绑定的情况,如下图所示:
从上图可以看出,vip地址192.168.1.210绑定在MASTER(192.168.1.201)的enp0s3网卡上。
5> 测试故障转移
将MASTER上的keepalived停止,查看vip是否会漂移到192.168.2.202上。停止201的keepalived服务:
shell> service keepalived stop shell> ip addr1
2
1
2
从上图可以看出,vip已经成功从201漂移到了202。此时再将201的keepalived服务启动后,由于201是MASTER,所以会将202的VIP抢占过来。
启动201的keepalived服务:
shell> service keepalived start1
1
结果VIP又回到了201,如下图所示:
3、非抢占模式
master从故障中恢复后,不会抢占备份节点的vip1> MASTER(192.168.1.201):
global_defs {
router_id nginx_01 #标识本节点的名称,通常为hostname
}
vrrp_script chk_nginx {
script "/etc/keepalived/nginx_check.sh"
interval 2
weight -20
}
vrrp_instance VI_1 {
state BACKUP
interface enp0s3
virtual_router_id 51
mcast_src_ip 192.168.1.201
priority 100
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.210
}
track_script {
chk_nginx # nginx存活状态检测脚本
}
}12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2> BACKUP(192.168.1.202)
global_defs {
router_id nginx_02
}
vrrp_script chk_nginx {
script "/etc/keepalived/nginx_check.sh"
interval 2
weight -20
}
vrrp_instance VI_1 {
state BACKUP
interface enp0s3
virtual_router_id 51
mcast_src_ip 192.168.1.202
priority 90
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.210
}
track_script {
chk_nginx
}
}12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
和非抢占模式的配置相比,只改了两个地方:
1> 在vrrp_instance块下两个节点各增加了nopreempt指令,表示不争抢vip
2> 节点的state都为BACKUP
两个keepalived节点都启动后,默认都是BACKUP状态,双方在发送组播信息后,会根据优先级来选举一个MASTER出来。由于两者都配置了nopreempt,所以MASTER从故障中恢复后,不会抢占vip。这样会避免VIP切换可能造成的服务延迟。

相关文章推荐
- Nginx + keepalived 实现高可用HA 【主从架构】
- Keepalived+Nginx实现高可用(HA)
- Keepalived+Nginx实现高可用(HA)
- Keepalived+Nginx实现高可用(HA)
- nginx+keepalived简单实现双击热备-高可用HA
- Keepalived+Nginx实现高可用(HA)
- Keepalived+Nginx实现高可用(HA)
- 使用Keepalived配置主从热备实现Nginx高可用(HA)
- cool-2018-03-09-lvs+nginx+keepalived实现高可用HA和负载均衡
- keepalived +nginx 实现HA 高可用的负载均衡
- 详解Keepalived+Nginx实现高可用(HA)
- Nginx + keepalived 实现高可用HA 【双主架构】
- Nginx+Keepalived 实现反代 负载均衡 高可用(HA)配置
- Keepalived+Nginx实现高可用(HA)
- 基于keepalived主从模型实现Nginx的高可用
- 如何实现Nginx+Keepalived中Nginx进程的高可用
- nginx+keepalived实现高可用负载均衡
- nginx+keepalived实现双机热备高可用
- keepalived+nginx实现nginx的高可用
- 基于keepalived 实现VIP转移,lvs,nginx的高可用