go语言的官方包sync.Pool
2017-03-30 10:38
239 查看
已经使用golang有一段时间,go的协程和gc垃圾回收特性的确会提高程序的开发效率。但是毕竟是一门新语言,如果对于它的机制不了解,用起来可能会蹦出各种潘多拉盒子。今天就讲讲我在项目中用到的sync包的Pool类的使用,以免大家混淆使用。
众所周知,go是自动垃圾回收的(garbage collector),这大大减少了程序编程负担。但gc是一把双刃剑,带来了编程的方便但同时也增加了运行时开销,使用不当甚至会严重影响程序的性能。因此性能要求高的场景不能任意产生太多的垃圾(有gc但又不能完全依赖它挺恶心的),如何解决呢?那就是要重用对象了,我们可以简单的使用一个chan把这些可重用的对象缓存起来,但如果很多goroutine竞争一个chan性能肯定是问题.....由于golang团队认识到这个问题普遍存在,为了避免大家重造车轮,因此官方统一出了一个包Pool。但为什么放到sync包里面也是有的迷惑的,先不讨论这个问题。
先来看看如何使用一个pool:
1、缓存对象的数量和期限
上面我们可以看到pool创建的时候是不能指定大小的,所有sync.Pool的缓存对象数量是没有限制的(只受限于内存),因此使用sync.pool是没办法做到控制缓存对象数量的个数的。另外sync.pool缓存对象的期限是很诡异的,先看一下src/pkg/sync/pool.go里面的一段实现代码:
可以看到pool包在init的时候注册了一个poolCleanup函数,它会清除所有的pool里面的所有缓存的对象,该函数注册进去之后会在每次gc之前都会调用,因此sync.Pool缓存的期限只是两次gc之间这段时间。例如我们把上面的例子改成下面这样之后,输出的结果将是0
0。正因gc的时候会清掉缓存对象,也不用担心pool会无限增大的问题。
这是很多人错误理解的地方,正因为这样,我们是不可以使用sync.Pool去实现一个socket连接池的。
2、缓存对象的开销
如何在多个goroutine之间使用同一个pool做到高效呢?官方的做法就是尽量减少竞争,因为sync.pool为每个P(对应cpu,不了解的童鞋可以去看看golang的调度模型介绍)都分配了一个子池,如下图:
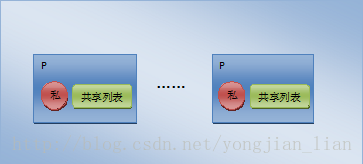
当执行一个pool的get或者put操作的时候都会先把当前的goroutine固定到某个P的子池上面,然后再对该子池进行操作。每个子池里面有一个私有对象和共享列表对象,私有对象是只有对应的P能够访问,因为一个P同一时间只能执行一个goroutine,因此对私有对象存取操作是不需要加锁的。共享列表是和其他P分享的,因此操作共享列表是需要加锁的。
获取对象过程是:
1)固定到某个P,尝试从私有对象获取,如果私有对象非空则返回该对象,并把私有对象置空;
2)如果私有对象是空的时候,就去当前子池的共享列表获取(需要加锁);
3)如果当前子池的共享列表也是空的,那么就尝试去其他P的子池的共享列表偷取一个(需要加锁);
4)如果其他子池都是空的,最后就用用户指定的New函数产生一个新的对象返回。
可以看到一次get操作最少0次加锁,最大N(N等于MAXPROCS)次加锁。
归还对象的过程:
1)固定到某个P,如果私有对象为空则放到私有对象;
2)否则加入到该P子池的共享列表中(需要加锁)。
可以看到一次put操作最少0次加锁,最多1次加锁。
由于goroutine具体会分配到那个P执行是golang的协程调度系统决定的,因此在MAXPROCS>1的情况下,多goroutine用同一个sync.Pool的话,各个P的子池之间缓存的对象是否平衡以及开销如何是没办法准确衡量的。但如果goroutine数目和缓存的对象数目远远大于MAXPROCS的话,概率上说应该是相对平衡的。
总的来说,sync.Pool的定位不是做类似连接池的东西,它的用途仅仅是增加对象重用的几率,减少gc的负担,而开销方面也不是很便宜的。
本文来自:CSDN博客
感谢作者:yongjian_lian
查看原文:go语言的官方包sync.Pool的实现原理和适用场景
Go 1.3 的sync包中加入一个新特性:Pool。
官方文档可以看这里http://golang.org/pkg/sync/#Pool
这个类设计的目的是用来保存和复用临时对象,以减少内存分配,降低CG压力。
type Pool
Get返回Pool中的任意一个对象。
如果Pool为空,则调用New返回一个新创建的对象。
如果没有设置New,则返回nil。
还有一个重要的特性是,放进Pool中的对象,会在说不准什么时候被回收掉。
所以如果事先Put进去100个对象,下次Get的时候发现Pool是空也是有可能的。
不过这个特性的一个好处就在于不用担心Pool会一直增长,因为Go已经帮你在Pool中做了回收机制。
这个清理过程是在每次垃圾回收之前做的。垃圾回收是固定两分钟触发一次。
而且每次清理会将Pool中的所有对象都清理掉!
package main
import(
)
func main(){
}
// 输出
2014/09/30 15:43:30 Hello,World!
2014/09/30 15:43:30 Hello,BeiJing
众所周知,go是自动垃圾回收的(garbage collector),这大大减少了程序编程负担。但gc是一把双刃剑,带来了编程的方便但同时也增加了运行时开销,使用不当甚至会严重影响程序的性能。因此性能要求高的场景不能任意产生太多的垃圾(有gc但又不能完全依赖它挺恶心的),如何解决呢?那就是要重用对象了,我们可以简单的使用一个chan把这些可重用的对象缓存起来,但如果很多goroutine竞争一个chan性能肯定是问题.....由于golang团队认识到这个问题普遍存在,为了避免大家重造车轮,因此官方统一出了一个包Pool。但为什么放到sync包里面也是有的迷惑的,先不讨论这个问题。
先来看看如何使用一个pool:
package main
import(
"fmt"
"sync"
)
func main() {
p := &sync.Pool{
New: func() interface{} {
return 0
},
}
a := p.Get().(int)
p.Put(1)
b := p.Get().(int)
fmt.Println(a, b)
}上面创建了一个缓存int对象的一个pool,先从池获取一个对象然后放进去一个对象再取出一个对象,程序的输出是0 1。创建的时候可以指定一个New函数,获取对象的时候如何在池里面找不到缓存的对象将会使用指定的new函数创建一个返回,如果没有new函数则返回nil。用法是不是很简单,我们这里就不多说,下面来说说我们关心的问题:1、缓存对象的数量和期限
上面我们可以看到pool创建的时候是不能指定大小的,所有sync.Pool的缓存对象数量是没有限制的(只受限于内存),因此使用sync.pool是没办法做到控制缓存对象数量的个数的。另外sync.pool缓存对象的期限是很诡异的,先看一下src/pkg/sync/pool.go里面的一段实现代码:
func init() {
runtime_registerPoolCleanup(poolCleanup)
}可以看到pool包在init的时候注册了一个poolCleanup函数,它会清除所有的pool里面的所有缓存的对象,该函数注册进去之后会在每次gc之前都会调用,因此sync.Pool缓存的期限只是两次gc之间这段时间。例如我们把上面的例子改成下面这样之后,输出的结果将是0
0。正因gc的时候会清掉缓存对象,也不用担心pool会无限增大的问题。
a := p.Get().(int) p.Put(1) runtime.GC() b := p.Get().(int) fmt.Println(a, b)
这是很多人错误理解的地方,正因为这样,我们是不可以使用sync.Pool去实现一个socket连接池的。
2、缓存对象的开销
如何在多个goroutine之间使用同一个pool做到高效呢?官方的做法就是尽量减少竞争,因为sync.pool为每个P(对应cpu,不了解的童鞋可以去看看golang的调度模型介绍)都分配了一个子池,如下图:
当执行一个pool的get或者put操作的时候都会先把当前的goroutine固定到某个P的子池上面,然后再对该子池进行操作。每个子池里面有一个私有对象和共享列表对象,私有对象是只有对应的P能够访问,因为一个P同一时间只能执行一个goroutine,因此对私有对象存取操作是不需要加锁的。共享列表是和其他P分享的,因此操作共享列表是需要加锁的。
获取对象过程是:
1)固定到某个P,尝试从私有对象获取,如果私有对象非空则返回该对象,并把私有对象置空;
2)如果私有对象是空的时候,就去当前子池的共享列表获取(需要加锁);
3)如果当前子池的共享列表也是空的,那么就尝试去其他P的子池的共享列表偷取一个(需要加锁);
4)如果其他子池都是空的,最后就用用户指定的New函数产生一个新的对象返回。
可以看到一次get操作最少0次加锁,最大N(N等于MAXPROCS)次加锁。
归还对象的过程:
1)固定到某个P,如果私有对象为空则放到私有对象;
2)否则加入到该P子池的共享列表中(需要加锁)。
可以看到一次put操作最少0次加锁,最多1次加锁。
由于goroutine具体会分配到那个P执行是golang的协程调度系统决定的,因此在MAXPROCS>1的情况下,多goroutine用同一个sync.Pool的话,各个P的子池之间缓存的对象是否平衡以及开销如何是没办法准确衡量的。但如果goroutine数目和缓存的对象数目远远大于MAXPROCS的话,概率上说应该是相对平衡的。
总的来说,sync.Pool的定位不是做类似连接池的东西,它的用途仅仅是增加对象重用的几率,减少gc的负担,而开销方面也不是很便宜的。
本文来自:CSDN博客
感谢作者:yongjian_lian
查看原文:go语言的官方包sync.Pool的实现原理和适用场景
Go 1.3 的sync包中加入一个新特性:Pool。
官方文档可以看这里http://golang.org/pkg/sync/#Pool
这个类设计的目的是用来保存和复用临时对象,以减少内存分配,降低CG压力。
type Pool
func (p *Pool) Get() interface{}
func (p *Pool) Put(x interface{})
New func() interface{}Get返回Pool中的任意一个对象。
如果Pool为空,则调用New返回一个新创建的对象。
如果没有设置New,则返回nil。
还有一个重要的特性是,放进Pool中的对象,会在说不准什么时候被回收掉。
所以如果事先Put进去100个对象,下次Get的时候发现Pool是空也是有可能的。
不过这个特性的一个好处就在于不用担心Pool会一直增长,因为Go已经帮你在Pool中做了回收机制。
这个清理过程是在每次垃圾回收之前做的。垃圾回收是固定两分钟触发一次。
而且每次清理会将Pool中的所有对象都清理掉!
package main
import(
"sync" "log"
)
func main(){
// 建立对象
var pipe = &sync.Pool{New:func()interface{}{return "Hello,BeiJing"}}
// 准备放入的字符串
val := "Hello,World!"
// 放入
pipe.Put(val)
// 取出
log.Println(pipe.Get())
// 再取就没有了,会自动调用NEW
log.Println(pipe.Get())}
// 输出
2014/09/30 15:43:30 Hello,World!
2014/09/30 15:43:30 Hello,BeiJing

相关文章推荐
- go语言的官方包sync.Pool的实现原理和适用场景
- Go语言学习之sync包(临时对象池Pool、互斥锁Mutex、等待Cond)(the way to go)
- Go语言中使用 buffered channel 实现线程安全的 pool
- Go 语言官方包函数中文翻译
- Go 语言sync中waitgroup使用.小实例
- go语言:sync.Once的用法
- 剖析Go1.3新特性:sync.Pool
- go语言_官方文档 godoc
- go语言中sync包和channel机制
- Go语言之并发示例-Pool(一)
- go语言中sync包和channel机制
- Go语言之并发示例-Pool(二)
- go语言sync包的学习(Mutex、WaitGroup、Cond)
- go语言使用官方的 log package 来记录日志
- Go语言的排它锁sync.Mutex
- Go语言官方文档
- GO语言官方中文教程!
- Go语言学习技巧之如何合理使用Pool
- Go语言实战--并发示例-Pool
- go的临时对象池--sync.Pool