C#批量插入数据到Sqlserver中的四种方式
2017-03-30 00:00
363 查看
本篇,我将来讲解一下在Sqlserver中批量插入数据。
先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引。GUID必然是比自增长要快的,因为你生成一个GUID算法所花的时间肯定比你从数据表中重新查询上一条记录的ID的值然后再进行加1运算要少。而如果存在索引的情况下,每次插入记录都会进行索引重建,这是非常耗性能的。如果表中无可避免的存在索引,我们可以通过先删除索引,然后批量插入,最后再重建索引的方式来提高效率。
我们通过SQL脚本来插入数据,常见如下四种方式。
方式一:一条一条插入,性能最差,不建议使用。
方式二:insert bulk
语法如下:
相关参数说明:
方式三:INSERT INTO xx select...
方式四:拼接SQL
在C#中通过ADO.NET来实现批量操作存在四种与之对应的方式。
运行结果如下:
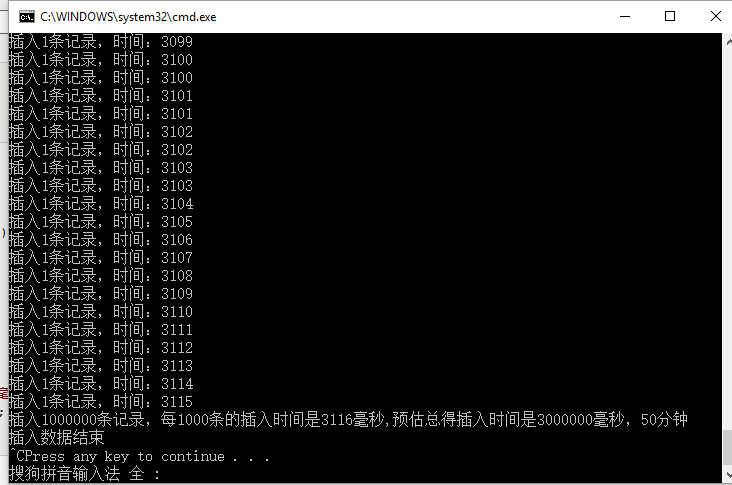
我们会发现插入100w条记录,预计需要50分钟时间,每插入一条记录大概需要3毫秒左右。
运行结果如下:
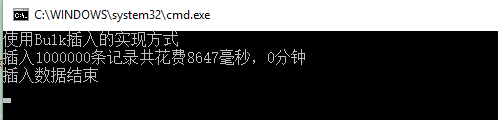
插入100w条记录才8s多,是不是很溜。
打开Sqlserver Profiler跟踪,会发现执行的是如下语句:
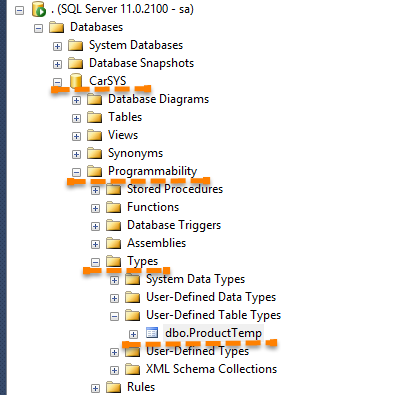
执行完成之后,会发现在数据库CarSYS下面多了一张缓存表ProductTemp
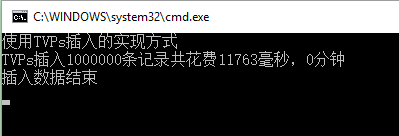
可见插入100w条记录共花费了11秒多。
运行结果如下:
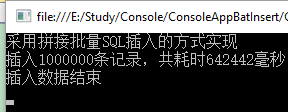
我们可以看到大概花费了10分钟。虽然在方式一的基础上,性能有了较大的提升,但是显然还是不够快。
总结:大数据批量插入方式一和方式四尽量避免使用,而方式二和方式三都是非常高效的批量插入数据方式。其都是通过构建DataTable的方式插入的,而我们知道DataTable是存在内存中的,所以当数据量特别特别大,大到内存中无法一次性存储的时候,可以分段插入。比如需要插入9千万条数据,可以分成9段进行插入,一次插入1千万条。而在for循环中直接进行数据库操作,我们是应该尽量避免的。每一次数据库的连接、打开和关闭都是比较耗时的,虽然在C#中存在数据库连接池,也就是当我们使用using或者conn.Close(),进行释放连接时,其实并没有真正关闭数据库连接,它只是让连接以类似于休眠的方式存在,当再次操作的时候,会从连接池中找一个休眠状态的连接,唤醒它,这样可以有效的提高并发能力,减少连接损耗。而连接池中的连接数,我们都是可以配置的。
源码下载:http://pan.baidu.com/s/1slm1wPv
先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引。GUID必然是比自增长要快的,因为你生成一个GUID算法所花的时间肯定比你从数据表中重新查询上一条记录的ID的值然后再进行加1运算要少。而如果存在索引的情况下,每次插入记录都会进行索引重建,这是非常耗性能的。如果表中无可避免的存在索引,我们可以通过先删除索引,然后批量插入,最后再重建索引的方式来提高效率。
create database CarSYS; go use CarSYS; go CREATE TABLE Product( Id UNIQUEIDENTIFIER PRIMARY KEY, NAME VARCHAR(50) NOT NULL, Price DECIMAL(18,2) NOT NULL )
我们通过SQL脚本来插入数据,常见如下四种方式。
方式一:一条一条插入,性能最差,不建议使用。
INSERT INTO Product(Id,Name,Price) VALUES(newid(),'牛栏1段',160); INSERT INTO Product(Id,Name,Price) VALUES(newid(),'牛栏2段',260); ......
方式二:insert bulk
语法如下:
BULK INSERT [ [ 'database_name'.][ 'owner' ].]{ 'table_name' FROM 'data_file' } WITH ( [ BATCHSIZE [ = batch_size ] ], [ CHECK_CONSTRAINTS ], [ CODEPAGE [ = 'ACP' | 'OEM' | 'RAW' | 'code_page' ] ], [ DATAFILETYPE [ = 'char' | 'native'| 'widechar' | 'widenative' ] ], [ FIELDTERMINATOR [ = 'field_terminator' ] ], [ FIRSTROW [ = first_row ] ], [ FIRE_TRIGGERS ], [ FORMATFILE = 'format_file_path' ], [ KEEPIDENTITY ], [ KEEPNULLS ], [ KILOBYTES_PER_BATCH [ = kilobytes_per_batch ] ], [ LASTROW [ = last_row ] ], [ MAXERRORS [ = max_errors ] ], [ ORDER ( { column [ ASC | DESC ] } [ ,...n ] ) ], [ ROWS_PER_BATCH [ = rows_per_batch ] ], [ ROWTERMINATOR [ = 'row_terminator' ] ], [ TABLOCK ], )相关参数说明:
BULK INSERT
[ database_name . [ schema_name ] . | schema_name . ] [ table_name | view_name ]
FROM 'data_file'
[ WITH ( [ [ , ] BATCHSIZE = batch_size ] --BATCHSIZE指令来设置在单个事务中可以插入到表中的记录的数量
[ [ , ] CHECK_CONSTRAINTS ] --指定在大容量导入操作期间,必须检查所有对目标表或视图的约束。若没有 CHECK_CONSTRAINTS 选项,则所有 CHECK 和 FOREIGN KEY 约束都将被忽略,并且在此操作之后表的约束将标记为不可信。
[ [ , ] CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ] --指定该数据文件中数据的代码页
[ [ , ] DATAFILETYPE = { 'char' | 'native'| 'widechar' | 'widenative' } ] --指定 BULK INSERT 使用指定的数据文件类型值执行导入操作。
[ [ , ] FIELDTERMINATOR = 'field_terminator' ] --标识分隔内容的符号
[ [ , ] FIRSTROW = first_row ] --指定要加载的第一行的行号。默认值是指定数据文件中的第一行
[ [ , ] FIRE_TRIGGERS ] --是否启动触发器
[ [ , ] FORMATFILE = 'format_file_path' ] [ [ , ] KEEPIDENTITY ] --指定导入数据文件中的标识值用于标识列
[ [ , ] KEEPNULLS ] --指定在大容量导入操作期间空列应保留一个空值,而不插入用于列的任何默认值
[ [ , ] KILOBYTES_PER_BATCH = kilobytes_per_batch ] [ [ , ] LASTROW = last_row ] --指定要加载的最后一行的行号
[ [ , ] MAXERRORS = max_errors ] --指定允许在数据中出现的最多语法错误数,超过该数量后将取消大容量导入操作。
[ [ , ] ORDER ( { column [ ASC | DESC ] } [ ,...n ] ) ] --指定数据文件中的数据如何排序
[ [ , ] ROWS_PER_BATCH = rows_per_batch ] [ [ , ] ROWTERMINATOR = 'row_terminator' ] --标识分隔行的符号
[ [ , ] TABLOCK ] --指定为大容量导入操作持续时间获取一个表级锁
[ [ , ] ERRORFILE = 'file_name' ] --指定用于收集格式有误且不能转换为 OLE DB 行集的行的文件。
)]方式三:INSERT INTO xx select...
INSERT INTO Product(Id,Name,Price) SELECT NEWID(),'牛栏1段',160 UNION ALL SELECT NEWID(),'牛栏2段',[b]180 UNION ALL ...... [/b]
方式四:拼接SQL
INSERT INTO Product(Id,Name,Price) VALUES (newid(),'牛栏1段',160) ,(newid(),'牛栏2段',[b]260) ......[/b]
在C#中通过ADO.NET来实现批量操作存在四种与之对应的方式。
方式一:逐条插入
#region 方式一
static void InsertOne() { Console.WriteLine("采用一条一条插入的方式实现"); Stopwatch sw = new Stopwatch(); using (SqlConnection conn = new SqlConnection(StrConnMsg)) //using中会自动Open和Close 连接。
{ string sql = "INSERT INTO Product(Id,Name,Price) VALUES(newid(),@p,@d)"; conn.Open(); for (int i = 0; i < totalRow; i++) { using (SqlCommand cmd = new SqlCommand(sql, conn)) { cmd.Parameters.AddWithValue("@p", "商品" + i); cmd.Parameters.AddWithValue("@d", i); sw.Start(); cmd.ExecuteNonQuery(); Console.WriteLine(string.Format("插入一条记录,已耗时{0}毫秒", sw.ElapsedMilliseconds)); } if (i == getRow) { sw.Stop(); break; } } } Console.WriteLine(string.Format("插入{0}条记录,每{4}条的插入时间是{1}毫秒,预估总得插入时间是{2}毫秒,{3}分钟",
totalRow, sw.ElapsedMilliseconds, ((sw.ElapsedMilliseconds / getRow) * totalRow), GetMinute((sw.ElapsedMilliseconds / getRow * totalRow)), getRow)); } static int GetMinute(long l) { return (Int32)l / 60000; } #endregion运行结果如下:
我们会发现插入100w条记录,预计需要50分钟时间,每插入一条记录大概需要3毫秒左右。
方式二:使用SqlBulk
#region 方式二
static void InsertTwo() { Console.WriteLine("使用Bulk插入的实现方式"); Stopwatch sw = new Stopwatch(); DataTable dt = GetTableSchema(); using (SqlConnection conn = new SqlConnection(StrConnMsg)) { SqlBulkCopy bulkCopy = new SqlBulkCopy(conn); bulkCopy.DestinationTableName = "Product"; bulkCopy.BatchSize = dt.Rows.Count; conn.Open(); sw.Start(); for (int i = 0; i < totalRow;i++ ) { DataRow dr = dt.NewRow(); dr[0] = Guid.NewGuid(); dr[1] = string.Format("商品", i); dr[2] = (decimal)i; dt.Rows.Add(dr); } if (dt != null && dt.Rows.Count != 0) { bulkCopy.WriteToServer(dt); sw.Stop(); } Console.WriteLine(string.Format("插入{0}条记录共花费{1}毫秒,{2}分钟", totalRow, sw.ElapsedMilliseconds, GetMinute(sw.ElapsedMilliseconds))); } } static DataTable GetTableSchema() { DataTable dt = new DataTable(); dt.Columns.AddRange(new DataColumn[] { new DataColumn("Id",typeof(Guid)), new DataColumn("Name",typeof(string)), new DataColumn("Price",typeof(decimal))}); return dt; } #endregion运行结果如下:
插入100w条记录才8s多,是不是很溜。
打开Sqlserver Profiler跟踪,会发现执行的是如下语句:
insert bulk Product ([Id] UniqueIdentifier, [NAME] VarChar(50) COLLATE Chinese_PRC_CI_AS, [Price] Decimal(18,2))
方式三:使用TVPs(表值参数)插入数据
从sqlserver 2008起开始支持TVPs。创建缓存表ProductTemp ,执行如下SQL。CREATE TYPE ProductTemp AS TABLE( Id UNIQUEIDENTIFIER PRIMARY KEY, NAME VARCHAR(50) NOT NULL, Price DECIMAL(18,2) NOT NULL )
执行完成之后,会发现在数据库CarSYS下面多了一张缓存表ProductTemp
可见插入100w条记录共花费了11秒多。
方式四:拼接SQL
此种方法在C#中有限制,一次性只能批量插入1000条,所以就得分段进行插入。#region 方式四 static void InsertFour() { Console.WriteLine("采用拼接批量SQL插入的方式实现"); Stopwatch sw = new Stopwatch(); using (SqlConnection conn = new SqlConnection(StrConnMsg)) //using中会自动Open和Close 连接。 { conn.Open(); sw.Start(); for (int j = 0; j < totalRow / getRow;j++ ) { StringBuilder sb = new StringBuilder(); sb.Append("INSERT INTO Product(Id,Name,Price) VALUES"); using (SqlCommand cmd = new SqlCommand()) { for (int i = 0; i < getRow; i++) { sb.AppendFormat("(newid(),'商品{0}',{0}),", j*i+i); } cmd.Connection = conn; cmd.CommandText = sb.ToString().TrimEnd(','); cmd.ExecuteNonQuery(); } } sw.Stop(); Console.WriteLine(string.Format("插入{0}条记录,共耗时{1}毫秒",totalRow,sw.ElapsedMilliseconds)); } } #endregion运行结果如下:
我们可以看到大概花费了10分钟。虽然在方式一的基础上,性能有了较大的提升,但是显然还是不够快。
总结:大数据批量插入方式一和方式四尽量避免使用,而方式二和方式三都是非常高效的批量插入数据方式。其都是通过构建DataTable的方式插入的,而我们知道DataTable是存在内存中的,所以当数据量特别特别大,大到内存中无法一次性存储的时候,可以分段插入。比如需要插入9千万条数据,可以分成9段进行插入,一次插入1千万条。而在for循环中直接进行数据库操作,我们是应该尽量避免的。每一次数据库的连接、打开和关闭都是比较耗时的,虽然在C#中存在数据库连接池,也就是当我们使用using或者conn.Close(),进行释放连接时,其实并没有真正关闭数据库连接,它只是让连接以类似于休眠的方式存在,当再次操作的时候,会从连接池中找一个休眠状态的连接,唤醒它,这样可以有效的提高并发能力,减少连接损耗。而连接池中的连接数,我们都是可以配置的。
源码下载:http://pan.baidu.com/s/1slm1wPv

相关文章推荐
- C#批量插入数据到Sqlserver中的四种方式 - 转
- C#批量插入数据到Sqlserver中的四种方式
- C#批量插入数据到Sqlserver中的四种方式
- C#_批量插入数据到Sqlserver中的四种方式
- C#批量插入数据到Sqlserver中的三种方式
- 详解C#批量插入数据到Sqlserver中的四种方式
- sqlserver中数据的四种插入方式
- SQLServer中批量插入数据方式的性能对比
- sqlserver 创建表后插入数据,可以用这样的方式来插入数据。
- SQLServer中批量插入数据方式的性能对比
- SQLServer中批量插入数据方式的性能对比
- MyBatis与Oracle,MySql,SqlServer插入数据返回主键方式
- SQLServer中批量插入数据方式的性能对比
- SQLServer中批量插入数据方式的性能对比
- SQLServer中批量插入数据方式的性能对比
- SQLServer中批量插入数据方式的性能对比
- SQLServer中批量插入数据方式的性能对比
- SQLServer中批量插入数据方式
- SQLServer中批量插入数据方式的性能对比(转)
- SQLServer中批量插入数据方式的性能对比