Spring 实现数据库读写分离
2017-03-29 15:40
85 查看
现在大型的电子商务系统,在数据库层面大都采用读写分离技术,就是一个Master数据库,多个Slave数据库。Master库负责数据更新和实时数据查询,Slave库当然负责非实时数据查询。因为在实际的应用中,数据库都是读多写少(读取数据的频率高,更新数据的频率相对较少),而读取数据通常耗时比较长,占用数据库服务器的CPU较多,从而影响用户体验。我们通常的做法就是把查询从主库中抽取出来,采用多个从库,使用负载均衡,减轻每个从库的查询压力。
采用读写分离技术的目标:有效减轻Master库的压力,又可以把用户查询数据的请求分发到不同的Slave库,从而保证系统的健壮性。我们看下采用读写分离的背景。
随着网站的业务不断扩展,数据不断增加,用户越来越多,数据库的压力也就越来越大,采用传统的方式,比如:数据库或者SQL的优化基本已达不到要求,这个时候可以采用读写分离的策 略来改变现状。
具体到开发中,如何方便的实现读写分离呢?目前常用的有两种方式:
1 第一种方式是我们最常用的方式,就是定义2个数据库连接,一个是MasterDataSource,另一个是SlaveDataSource。更新数据时我们读取MasterDataSource,查询数据时我们读取SlaveDataSource。这种方式很简单,我就不赘述了。
2 第二种方式动态数据源切换,就是在程序运行时,把数据源动态织入到程序中,从而选择读取主库还是从库。主要使用的技术是:annotation,Spring AOP ,反射。下面会详细的介绍实现方式。
在介绍实现方式之前,我们先准备一些必要的知识,spring 的AbstractRoutingDataSource 类
AbstractRoutingDataSource这个类 是spring2.0以后增加的,我们先来看下AbstractRoutingDataSource的定义:
public abstract class AbstractRoutingDataSource extends AbstractDataSource implements InitializingBean {}
AbstractRoutingDataSource继承了AbstractDataSource ,而AbstractDataSource 又是DataSource 的子类。DataSource 是javax.sql 的数据源接口,定义如下:
View Code
好了,运行我们的Eclipse看看效果,输入用户名admin 登录看看效果
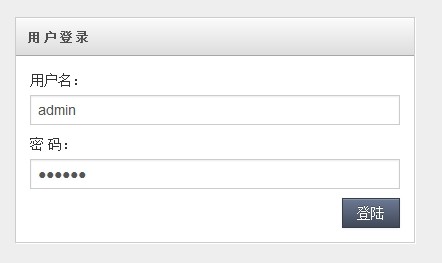
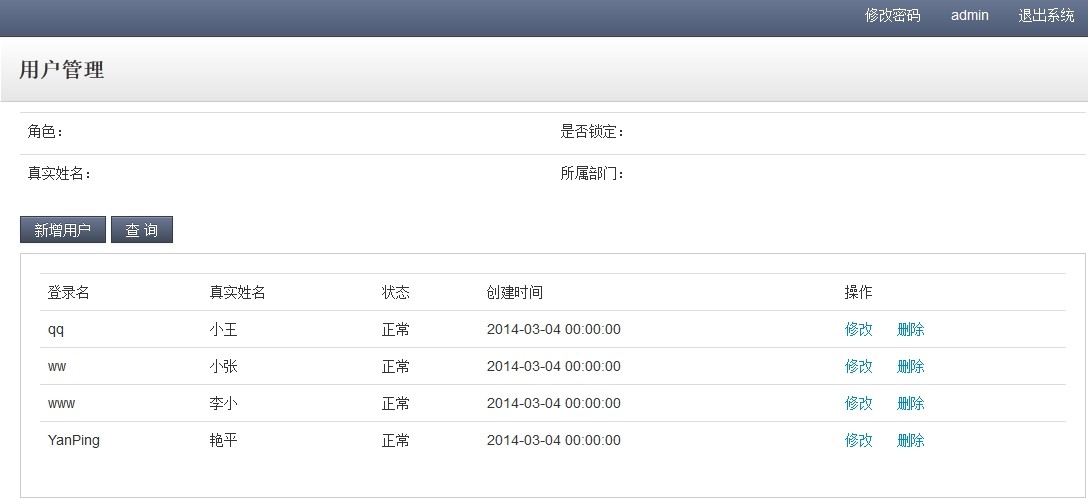
从图中可以看出,登录的用户和用户列表的数据是不同的,也验证了我们的实现,登录读取Master库,用户列表读取Slave库。
采用读写分离技术的目标:有效减轻Master库的压力,又可以把用户查询数据的请求分发到不同的Slave库,从而保证系统的健壮性。我们看下采用读写分离的背景。
随着网站的业务不断扩展,数据不断增加,用户越来越多,数据库的压力也就越来越大,采用传统的方式,比如:数据库或者SQL的优化基本已达不到要求,这个时候可以采用读写分离的策 略来改变现状。
具体到开发中,如何方便的实现读写分离呢?目前常用的有两种方式:
1 第一种方式是我们最常用的方式,就是定义2个数据库连接,一个是MasterDataSource,另一个是SlaveDataSource。更新数据时我们读取MasterDataSource,查询数据时我们读取SlaveDataSource。这种方式很简单,我就不赘述了。
2 第二种方式动态数据源切换,就是在程序运行时,把数据源动态织入到程序中,从而选择读取主库还是从库。主要使用的技术是:annotation,Spring AOP ,反射。下面会详细的介绍实现方式。
在介绍实现方式之前,我们先准备一些必要的知识,spring 的AbstractRoutingDataSource 类
AbstractRoutingDataSource这个类 是spring2.0以后增加的,我们先来看下AbstractRoutingDataSource的定义:
public abstract class AbstractRoutingDataSource extends AbstractDataSource implements InitializingBean {}
AbstractRoutingDataSource继承了AbstractDataSource ,而AbstractDataSource 又是DataSource 的子类。DataSource 是javax.sql 的数据源接口,定义如下:
public interface UserMapper {
@DataSource("master")
public void add(User user);
@DataSource("master")
public void update(User user);
@DataSource("master")
public void delete(int id);
@DataSource("slave")
public User loadbyid(int id);
@DataSource("master")
public User loadbyname(String name);
@DataSource("slave")
public List<User> list();
}View Code
好了,运行我们的Eclipse看看效果,输入用户名admin 登录看看效果
从图中可以看出,登录的用户和用户列表的数据是不同的,也验证了我们的实现,登录读取Master库,用户列表读取Slave库。

相关文章推荐
- Spring 实现数据库读写分离
- mysql+spring+mybatis实现数据库读写分离[代码配置]
- Spring 实现数据库读写分离
- Spring 配置多数据源实现数据库读写分离
- spring+mybatis+uncode-dal实现数据库读写分离
- Spring 实现数据库读写分离
- Spring实现数据库读写分离
- Spring实现数据库读写分离/spring事务配置解释(Annotation/Spring AOP/Reflection)
- Spring 配置多数据源实现数据库读写分离
- 使用spring的动态路由实现数据库读写分离【数据库读写分离(二) 】 .
- Spring 实现数据库读写分离
- Spring 实现数据库读写分离
- Spring 实现数据库读写分离
- Spring 实现数据库读写分离
- spring实现数据库读写分离
- Spring 配置多数据源实现数据库读写分离
- 未测试---- mysql+spring+mybatis实现数据库读写分离[代码配置]
- Spring实现数据库读写分离
- 使用spring的动态路由实现数据库读写分离【数据库读写分离(二) 】
- Spring 实现数据库读写分离