Java开源爬虫框架WebCollector—爬取新浪微博
2017-03-26 23:46
417 查看
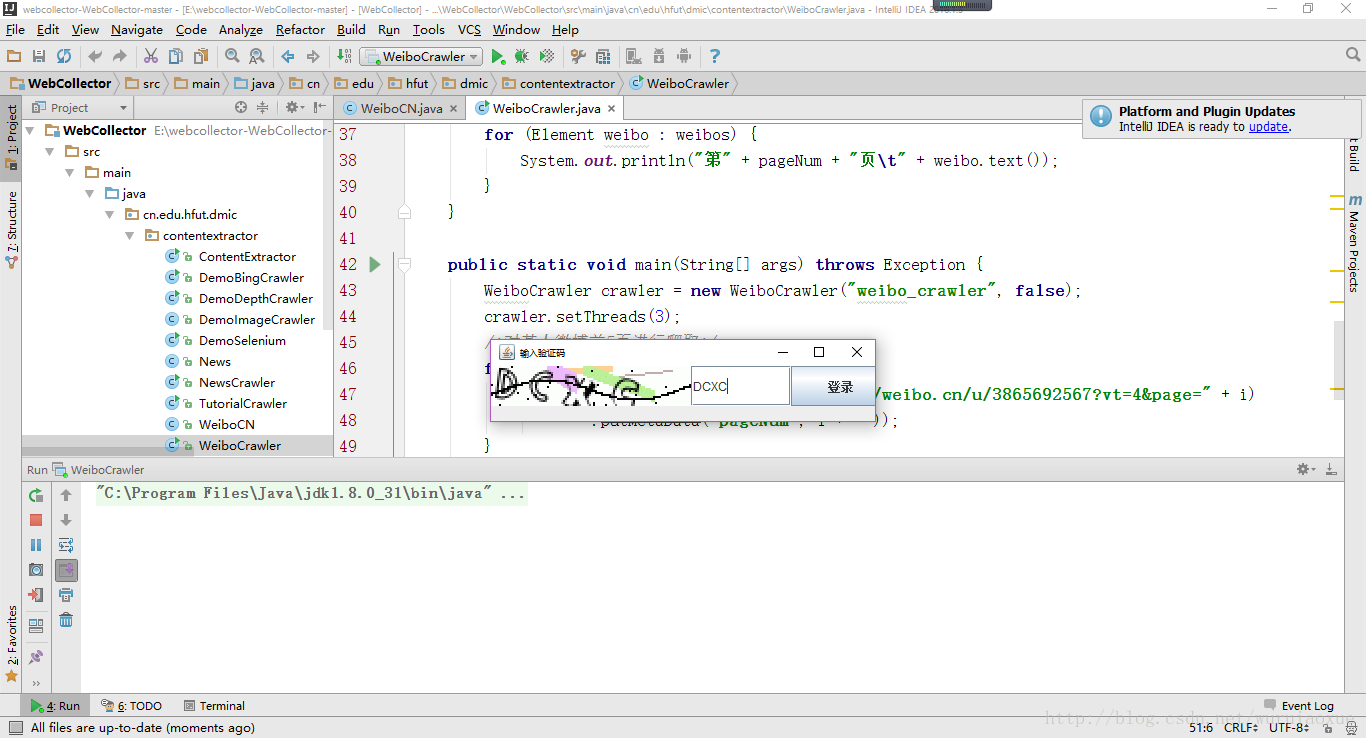
本教程给出了一个使用WebCollector模拟登陆并爬取新浪微博的示例.登录过程中会出现验证码.如图所示:
1.依赖jar包:
本教程需要两套jar包,WebCollector核心jar包和selenium的jar包。
WebCollector最新jar包可在WebCollector github主页下载。
selenium的maven依赖:
或者在百度网盘中链接:http://pan.baidu.com/s/1dE9af3z 密码:4z2d

2.代码:
(1)利用Selenium获取登陆新浪微博weibo.cn的cookie(WeiboCN.java)
(2)利用WebCollector和获取的cookie爬取新浪微博并抽取数据(WeiboCrawler.java)
WeiboCN.java
WeiboCrawler.java
这是对@最强大脑微博的爬取,通过修改爬取的页数,获取对应微博数据。在爬取的过程需要用户修改微博账号和密码,最好使用小号进行爬取,因为爬取过程使用明文传输。
运行后结果如图所示:
与其对应的网页如图所示:
我们可以通过修改如图所示的地址来爬取对应微博数据:
至此关于新浪微博的爬取就讲完了,希望对大家有所帮助!
1.依赖jar包:
本教程需要两套jar包,WebCollector核心jar包和selenium的jar包。
WebCollector最新jar包可在WebCollector github主页下载。
selenium的maven依赖:
<dependency> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-java</artifactId> <version>2.44.0</version> </dependency>
或者在百度网盘中链接:http://pan.baidu.com/s/1dE9af3z 密码:4z2d
2.代码:
(1)利用Selenium获取登陆新浪微博weibo.cn的cookie(WeiboCN.java)
(2)利用WebCollector和获取的cookie爬取新浪微博并抽取数据(WeiboCrawler.java)
WeiboCN.java
package cn.edu.hfut.dmic.contentextractor;
import cn.edu.hfut.dmic.webcollector.net.HttpRequest;
import cn.edu.hfut.dmic.webcollector.net.HttpResponse;
import java.io.ByteArrayInputStream;
import java.io.File;
import java.util.Set;
import javax.imageio.ImageIO;
import org.openqa.selenium.Cookie;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
import java.awt.BorderLayout;
import java.awt.Container;
import java.awt.Dimension;
import java.awt.Graphics;
import java.awt.Toolkit;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.image.BufferedImage;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JPanel;
import javax.swing.JTextField;
/**
* 利用Selenium获取登陆新浪微博weibo.cn的cookie
*
* @author hu
*/
public class WeiboCN {
/**
* 获取新浪微博的cookie,这个方法针对weibo.cn有效,对weibo.com无效 weibo.cn以明文形式传输数据,请使用小号
*
* @param username 新浪微博用户名
* @param password 新浪微博密码
* @return
* @throws Exception
*/
public static String getSinaCookie(String username, String password) throws Exception {
StringBuilder sb = new StringBuilder();
HtmlUnitDriver driver = new HtmlUnitDriver();
driver.setJavascriptEnabled(true);
driver.get("http://login.weibo.cn/login/");
WebElement ele = driver.findElementByCssSelector("img");
String src = ele.getAttribute("src");
String cookie = concatCookie(driver);
HttpRequest request = new HttpRequest(src);
request.setCookie(cookie);
HttpResponse response = request.getResponse();
ByteArrayInputStream is = new ByteArrayInputStream(response.getContent());
BufferedImage img = ImageIO.read(is);
is.close();
ImageIO.write(img, "png", new File("result.png"));
String userInput = new CaptchaFrame(img).getUserInput();
WebElement mobile = driver.findElementByCssSelector("input[name=mobile]");
mobile.sendKeys(username);
WebElement pass = driver.findElementByCssSelector("input[name^=password]");
pass.sendKeys(password);
WebElement code = driver.findElementByCssSelector("input[name=code]");
code.sendKeys(userInput);
WebElement rem = driver.findElementByCssSelector("input[name=remember]");
rem.click();
WebElement submit = driver.findElementByCssSelector("input[name=submit]");
submit.click();
String result = concatCookie(driver);
driver.close();
if (result.contains("gsid_CTandWM")) {
return result;
} else {
throw new Exception("weibo login failed");
}
}
public static String concatCookie(HtmlUnitDriver driver) {
Set<Cookie> cookieSet = driver.manage().getCookies();
StringBuilder sb = new StringBuilder();
for (Cookie cookie : cookieSet) {
sb.append(cookie.getName() + "=" + cookie.getValue() + ";");
}
String result = sb.toString();
return result;
}
public static class CaptchaFrame {
JFrame frame;
JPanel panel;
JTextField input;
int inputWidth = 100;
BufferedImage img;
String userInput = null;
public CaptchaFrame(BufferedImage img) {
this.img = img;
}
public String getUserInput() {
frame = new JFrame("输入验证码");
final int imgWidth = img.getWidth();
final int imgHeight = img.getHeight();
int width = imgWidth * 2 + inputWidth * 2;
int height = imgHeight * 2+50;
Dimension dim = Toolkit.getDefaultToolkit().getScreenSize();
int startx = (dim.width - width) / 2;
int starty = (dim.height - height) / 2;
frame.setBounds(startx, starty, width, height);
Container container = frame.getContentPane();
container.setLayout(new BorderLayout());
panel = new JPanel() {
@Override
public void paintComponent(Graphics g) {
super.paintComponent(g);
g.drawImage(img, 0, 0, imgWidth * 2, imgHeight * 2, null);
}
};
panel.setLayout(null);
container.add(panel);
input = new JTextField(6);
input.setBounds(imgWidth * 2, 0, inputWidth, imgHeight * 2);
panel.add(input);
JButton btn = new JButton("登录");
btn.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
userInput = input.getText().trim();
synchronized (CaptchaFrame.this) {
CaptchaFrame.this.notify();
}
}
});
btn.setBounds(imgWidth * 2 + inputWidth, 0, inputWidth, imgHeight * 2);
panel.add(btn);
frame.setVisible(true);
synchronized (this) {
try {
this.wait();
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}
frame.dispose();
return userInput;
}
}
}WeiboCrawler.java
package cn.edu.hfut.dmic.contentextractor;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.net.HttpRequest;
import cn.edu.hfut.dmic.webcollector.net.HttpResponse;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* 利用WebCollector和获取的cookie爬取新浪微博并抽取数据
* @author hu
*/
public class WeiboCrawler extends BreadthCrawler {
String cookie;
public WeiboCrawler(String crawlPath, boolean autoParse) throws Exception {
super(crawlPath, autoParse);
/*获取新浪微博的cookie,账号密码以明文形式传输,请使用小号*/
cookie = WeiboCN.getSinaCookie("小号的账号", "小号的密码");
}
@Override
public HttpResponse getResponse(CrawlDatum crawlDatum) throws Exception {
HttpRequest request = new HttpRequest(crawlDatum);
request.setCookie(cookie);
return request.getResponse();
}
@Override
public void visit(Page page, CrawlDatums next) {
int pageNum = Integer.valueOf(page.getMetaData("pageNum"));
/*抽取微博*/
Elements weibos = page.select("div.c");
for (Element weibo : weibos) {
System.out.println("第" + pageNum + "页\t" + weibo.text());
}
}
public static void main(String[] args) throws Exception {
WeiboCrawler crawler = new WeiboCrawler("weibo_crawler", false);
crawler.setThreads(3);
/*对某人微博前5页进行爬取*/
for (int i = 1; i <= 50; i++) {
crawler.addSeed(new CrawlDatum("http://weibo.cn/u/3865692567?vt=4&page=" + i)
.putMetaData("pageNum", i + ""));
}
crawler.start(1);
}
}这是对@最强大脑微博的爬取,通过修改爬取的页数,获取对应微博数据。在爬取的过程需要用户修改微博账号和密码,最好使用小号进行爬取,因为爬取过程使用明文传输。
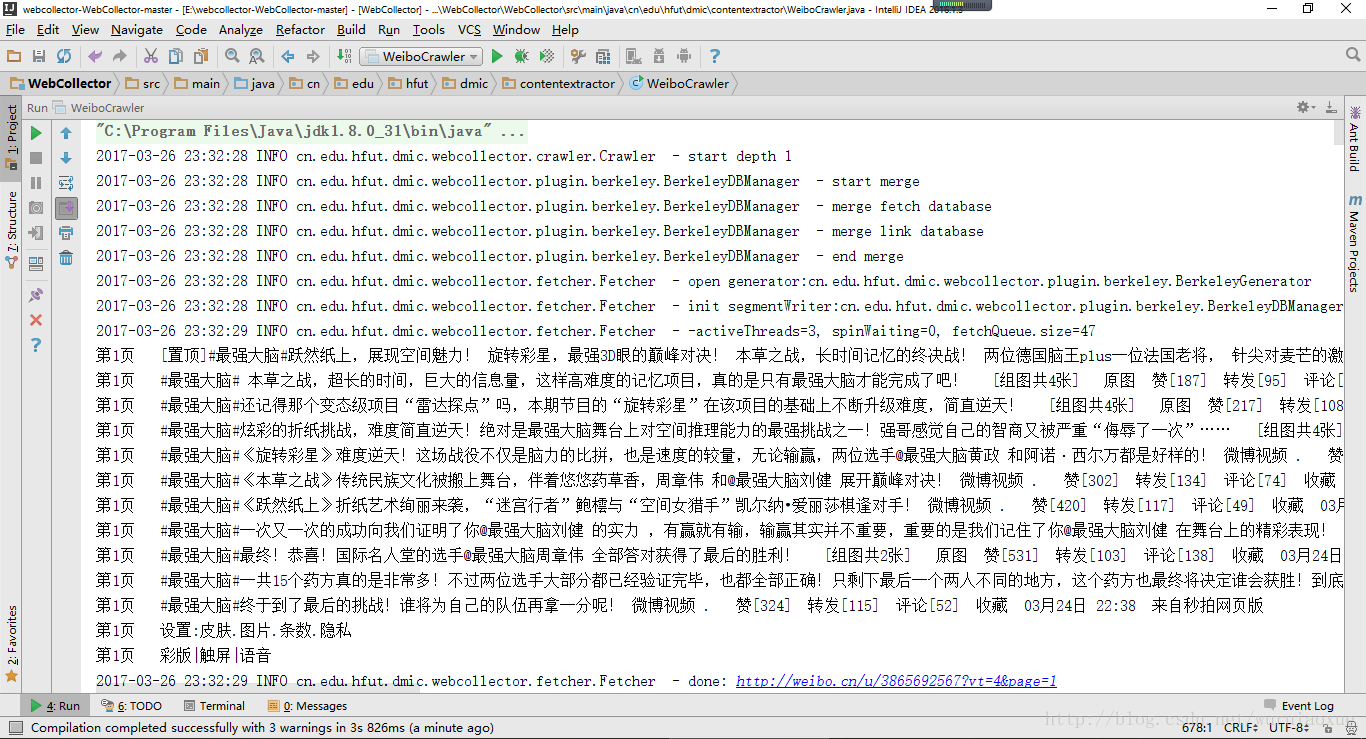
运行后结果如图所示:
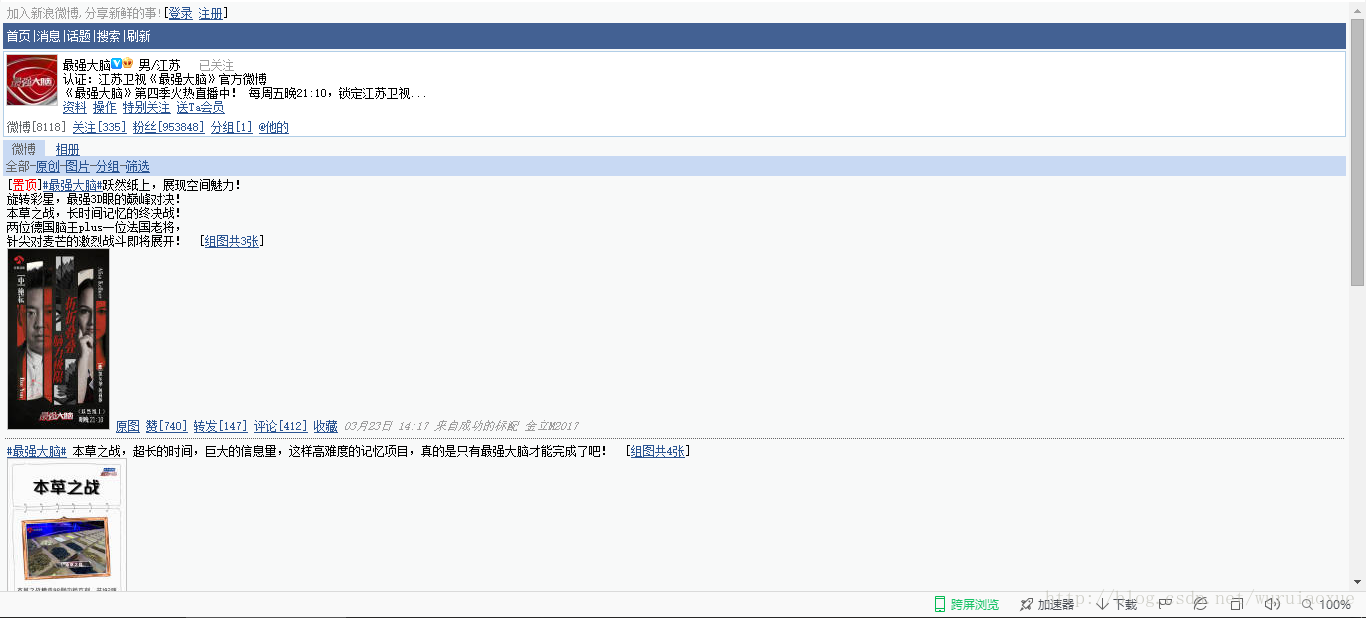
与其对应的网页如图所示:
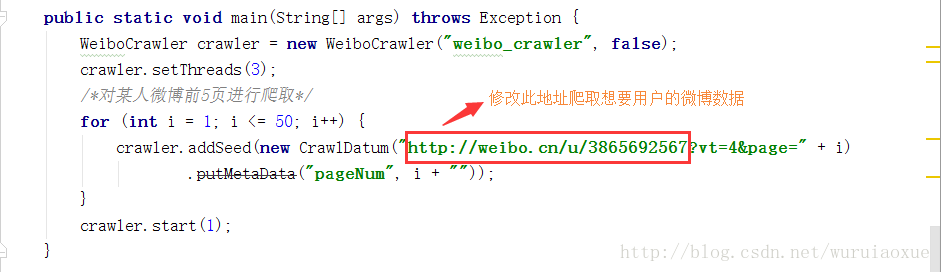
我们可以通过修改如图所示的地址来爬取对应微博数据:
至此关于新浪微博的爬取就讲完了,希望对大家有所帮助!

相关文章推荐
- Java开源爬虫框架WebCollector爬取CSDN博客
- webcollector 爬虫框架使用说明
- JAVA开源爬虫,WebCollector,简单易用,有界面。
- JAVA开源爬虫,WebCollector,简单易用,有界面。
- JAVA爬虫 WebCollector
- WebCollector爬虫爬取一个或多个网站
- 利用WebCollector爬虫内核定制自己的爬虫——任务生成器Generator
- JAVA爬虫Nutch、WebCollector的正则约束
- Java开源Web爬虫种类
- JAVA爬虫WebCollector
- 用WebCollector制作一个爬取《知乎》并进行问题精准抽取的爬虫(JAVA)
- WebCollector爬虫的种子
- Java开源Web框架
- Java开源Web框架
- 有了 Docker,用 JavaScript 框架开发的 Web 站点也能很好地支持网络爬虫的内容抓取
- 使用Python的Scrapy框架编写web爬虫的简单示例
- WebCollector爬虫使用内置的Jsoup进行网页抽取
- Java开源 Web开发框架 (三)
- Java开源 Web开发框架 (二)
- 用WebCollector爬取新浪微博数据