zookeeper+Kafka集群部署
2017-03-24 15:50
519 查看
一 准备工作
准备3台机器,IP地址分别为:192.168.46.130(131,132)
下载 jdk-8u121-linux-x64.tar.gz zookeeper-3.4.6.tar.gz kafka_2.11-0.10.1.0.tgz
1.修改主机名 /etc/hosts 及/etc/sysconfig/network
hosts:
192.168.46.130 kafka1
192.168.46.131 kafka2
192.168.46.132 kafka3
network
分别将network中的主机名修改为 kafka1 kafka2 kafka3
2.jdk安装配置省略
3.zookeeper部署
1) 解压zookeeper-3.4.6.tar.gz
2) tar -zxvf zookeeper-3.4.6.tar.gz
3) 建立myid 在/usr/local/目录下建立 zkData目录,即/usr/local/zkData,
4) 并执行 echo 1 >myid (kafka1服务器上) echo
2 >myid (kafka2服务器上) echo 3 >myid (kafka3服务器上)
5)
三台服务器的zoo.cfg配置文件为
zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zkData
clientPort=2181
server.1=192.168.46.130:2888:3888
server.2=192.168.46.131:2888:3888
server.3=192.168.46.132:2888:3888
4.kafka部署(解压kafka_2.11-0.10.1.0.tgz文件)
1).进入config目录,修改server.properties(逐个机器修改)
broker.id=1 (其他服务器2/3)
zookeeper.connect=192.168.46.130:2181,192.168.46.131:2181,192.168.46.132:2181
zookeeper.connection.timeout.ms=6000
port
= 9092
host.name = 192.168.46.131
5.启动每台服务器上的zookeeper
1) 启动前关闭各台服务器的防火墙:service iptables stop
2) bin/zkServer.sh start 启动
3) bin/zkServer.sh status 查看状态
6 启动每台服务器的kafka:
> bin/kafka-server-start.sh config/server.properties &
7.集群测试
1.创建一个topic
> bin/kafka-topics.sh --create --zookeeper 192.168.46.130:2181 --replication-factor 3 --partitions 1
--topic test-topic
2.查看创建的topic
> bin/kafka-topics.sh --describe --zookeeper 192.168.46.130:2181 --topic test-topic
Topic:test-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: test-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
3.查看topic列表
> bin/kafka-topics.sh --list --zookeeper 192.168.46.130 :2181
test-topic
查看列表及具体信息
> bin/kafka-topics.sh --zookeeper localhost --describe
4.查看集群情况:
>bin/kafka-topics.sh --describe --zookeeper 192.168.46.131:2181 --topic test-topic
>bin/kafka-topics.sh --describe --zookeeper 192.168.46.132:2181 --topic test-topic
发现都能看到test-topic。
5.生产消息(定义不同的生产者)
> bin/kafka-console-producer.sh --broker-list 192.168.46.130:9092 -topic test-topic
接着输入生产的内容:如 haha
6.消费消息(在不同的服务器上执行下面的命令后都可接受到生产的消息)
> bin/kafka-console-consumer.sh --zookeeper 192.168.46.131:2181 --from-beginning --topic test-topic
> bin/kafka-console-consumer.sh --zookeeper 192.168.46.132:2181 --from-beginning --topic test-topic
消费端的内容:haha
每个节点既可以作为生产者也可以作为消费者,一个节点要么为生产者要么为消费者
8 客户端调用(参考:http://blog.csdn.net/u011622226/article/details/53520382)
maven 引入
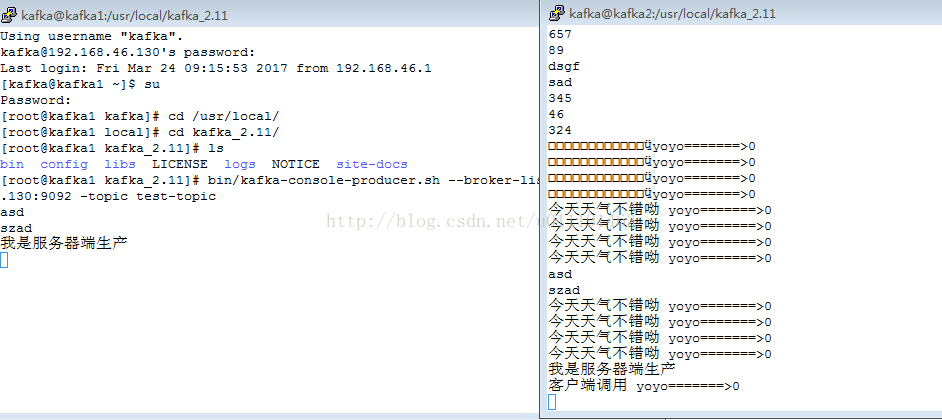
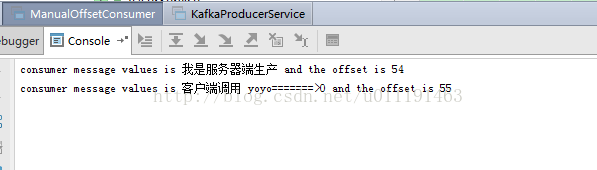
下图为服务器端进行消息生产和客户端调用生产的执行情况(这里只讲kafka1设置为生产者,kafka2为消费者,也可以将kafka3设置生产或消费者)

准备3台机器,IP地址分别为:192.168.46.130(131,132)
下载 jdk-8u121-linux-x64.tar.gz zookeeper-3.4.6.tar.gz kafka_2.11-0.10.1.0.tgz
1.修改主机名 /etc/hosts 及/etc/sysconfig/network
hosts:
192.168.46.130 kafka1
192.168.46.131 kafka2
192.168.46.132 kafka3
network
分别将network中的主机名修改为 kafka1 kafka2 kafka3
2.jdk安装配置省略
3.zookeeper部署
1) 解压zookeeper-3.4.6.tar.gz
2) tar -zxvf zookeeper-3.4.6.tar.gz
3) 建立myid 在/usr/local/目录下建立 zkData目录,即/usr/local/zkData,
4) 并执行 echo 1 >myid (kafka1服务器上) echo
2 >myid (kafka2服务器上) echo 3 >myid (kafka3服务器上)
5)
三台服务器的zoo.cfg配置文件为
zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zkData
clientPort=2181
server.1=192.168.46.130:2888:3888
server.2=192.168.46.131:2888:3888
server.3=192.168.46.132:2888:3888
4.kafka部署(解压kafka_2.11-0.10.1.0.tgz文件)
1).进入config目录,修改server.properties(逐个机器修改)
broker.id=1 (其他服务器2/3)
zookeeper.connect=192.168.46.130:2181,192.168.46.131:2181,192.168.46.132:2181
zookeeper.connection.timeout.ms=6000
port
= 9092
host.name = 192.168.46.131
5.启动每台服务器上的zookeeper
1) 启动前关闭各台服务器的防火墙:service iptables stop
2) bin/zkServer.sh start 启动
3) bin/zkServer.sh status 查看状态
6 启动每台服务器的kafka:
> bin/kafka-server-start.sh config/server.properties &
7.集群测试
1.创建一个topic
> bin/kafka-topics.sh --create --zookeeper 192.168.46.130:2181 --replication-factor 3 --partitions 1
--topic test-topic
2.查看创建的topic
> bin/kafka-topics.sh --describe --zookeeper 192.168.46.130:2181 --topic test-topic
Topic:test-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: test-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
3.查看topic列表
> bin/kafka-topics.sh --list --zookeeper 192.168.46.130 :2181
test-topic
查看列表及具体信息
> bin/kafka-topics.sh --zookeeper localhost --describe
4.查看集群情况:
>bin/kafka-topics.sh --describe --zookeeper 192.168.46.131:2181 --topic test-topic
>bin/kafka-topics.sh --describe --zookeeper 192.168.46.132:2181 --topic test-topic
发现都能看到test-topic。
5.生产消息(定义不同的生产者)
> bin/kafka-console-producer.sh --broker-list 192.168.46.130:9092 -topic test-topic
接着输入生产的内容:如 haha
6.消费消息(在不同的服务器上执行下面的命令后都可接受到生产的消息)
> bin/kafka-console-consumer.sh --zookeeper 192.168.46.131:2181 --from-beginning --topic test-topic
> bin/kafka-console-consumer.sh --zookeeper 192.168.46.132:2181 --from-beginning --topic test-topic
消费端的内容:haha
每个节点既可以作为生产者也可以作为消费者,一个节点要么为生产者要么为消费者
8 客户端调用(参考:http://blog.csdn.net/u011622226/article/details/53520382)
maven 引入
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>0.10.1.0</version> </dependency>
package com.fuliwd.kafka;
import java.util.Properties;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class KafkaProducerService {
private static Logger LOG = LoggerFactory
.getLogger(KafkaProducerService.class);
public static void main(String[] args) {
Properties props = new Properties();
//zookeeper地址
props.put("bootstrap.servers", "192.168.46.130:9092,192.168.46.131:9092,192.168.46.132:9092");
props.put("retries", 3);
props.put("linger.ms", 1);
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(
props);
//test-topic为队列名称
for (int i = 0; i < 1; i++) {
ProducerRecord<String, String> record = new ProducerRecord<String, String>(
"test-topic", "11", "客户端调用 yoyo=======>" + i);
producer.send(record, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception e) {
// TODO Auto-generated method stub
if (e != null)
System.out.println("the producer has a error:"
+ e.getMessage());
else {
System.out
.println("The offset of the record we just sent is: "
+ metadata.offset());
System.out
.println("The partition of the record we just sent is: "
+ metadata.partition());
}
}
});
try {
Thread.sleep(1000);
// producer.close();
} catch (InterruptedException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
}
}
}package com.fuliwd.kafka;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* @author Joker
* 自己控制偏移量提交
* 很多时候,我们是希望在获得消息并经过一些逻辑处理后,才认为该消息已被消费,这可以通过自己控制偏移量提交来实现。
*/
public class ManualOffsetConsumer {
private static Logger LOG = LoggerFactory.getLogger(ManualOffsetConsumer.class);
public static void main(String[] args) {
// TODO Auto-generated method stub
Properties props = new Properties();
//设置brokerServer(kafka)ip地址 zookeeper地址
props.put("bootstrap.servers", "192.168.46.130:9092,192.168.46.131:9092,192.168.46.132:9092");
//设置consumer group name
props.put("group.id","mygroup11");
props.put("enable.auto.commit", "false");
//设置使用最开始的offset偏移量为该group.id的最早。如果不设置,则会是latest即该topic最新一个消息的offset
//如果采用latest,消费者只能得道其启动后,生产者生产的消息
props.put("auto.offset.reset", "earliest");
//设置心跳时间
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String ,String> consumer = new KafkaConsumer<String ,String>(props);
consumer.subscribe(Arrays.asList("test-topic"));//队列名称
final int minBatchSize = 5; //批量提交数量
List<ConsumerRecord<String, String>> buffer = new ArrayList<ConsumerRecord<String, String>>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println("consumer message values is "+record.value()+" and the offset is "+ record.offset());
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
System.out.println("now commit offset"+buffer.size());
consumer.commitSync();
buffer.clear();
}
}
}
}下图为服务器端进行消息生产和客户端调用生产的执行情况(这里只讲kafka1设置为生产者,kafka2为消费者,也可以将kafka3设置生产或消费者)

相关文章推荐
- kafka集群和zookeeper集群的部署,kafka的java代码示例
- 生产环境实战spark (11)分布式集群 5台设备 Zookeeper集群、Kafka集群安装部署
- zookeeper+kafka集群部署
- kafka学习总结之集群部署和zookeeper
- Kafka集群搭建01-Zookeeper 集群部署
- zookeeper+kafka集群安装部署
- 消息中间件 kafka+zookeeper 集群部署、测试与应用(1)
- 在单机上实现ZooKeeper伪集群部署
- Hadoop+Flume+Kafka+Zookeeper集群环境搭建(一)
- zookeeper如何做集群部署
- kafka集群部署以及java客户端测试
- kafka集群部署以及java客户端测试
- 防火墙未开端口导致zookeeper集群异常,kafka起不来
- zookeeper+kafka 集群和高可用
- zookeeper+kafka 集群和高可用
- Kafka linux集群部署
- zookeeper 单ip 集群部署
- zookeeper+kafka集群搭建
- zookeeper+kafka集群搭建
- Zookeeper集群部署与配置(三)