MongoDB 存储引擎说明
2017-03-20 08:10
323 查看
#MongoDB 存储引擎说明
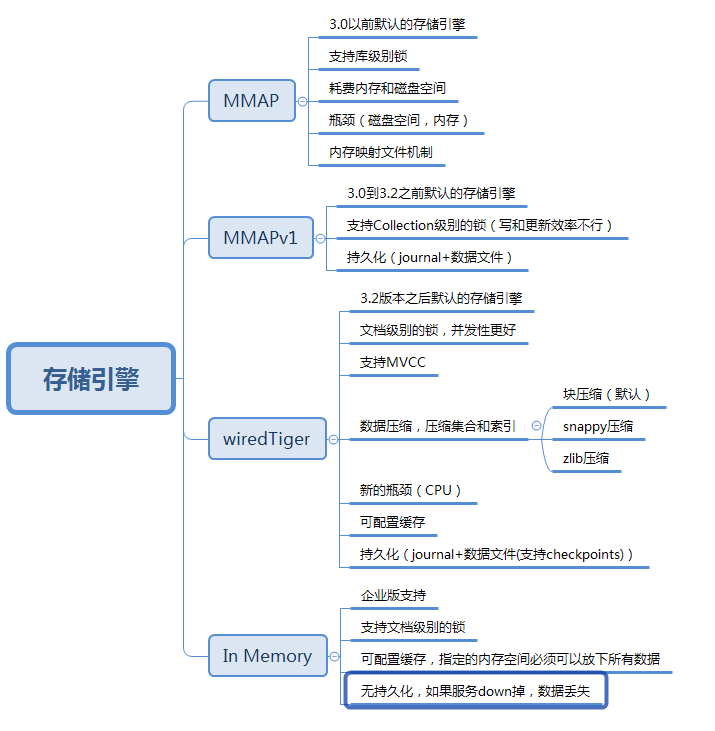
MongoDB 存储引擎可以插件化(3.0开始提供插件化API),根据不同的场景选择不同的存储引擎,跟Mysql有点类似。
MongoDB 常用存储引擎:
#MongoDB 存储引擎之WiredTiger
3.2版本开始WiredTiger已经是MongoDB的默认存储引擎。
WiredTiger支持文档级别的锁,检查点(checkpoint),压缩,等功能。企业版支持Rest加密。
##WiredTiger 特性
####并发模型
WiredTiger带来最显著的改进之一就是锁粒度的细化,它通过MVCC(通过copyOnWrite的方式实现的多版本并发控制)实现了文档级别的锁(多个客户端可以并发的修改一个集合中多个不同的文档),大大提高了并发读写的性能。
####数据压缩
WiredTiger带来的另一个显著提升是:通过使用高效的压缩算法对数据进行压缩,数据占用磁盘空间大大减少(最大能压缩80%的空间)。
压缩是以CPU计算为代价而减少了存储量,不过相比压缩带来的好处,牺牲这点CPU时间是值得的。
MongoDb支持对所有集合和索引(前缀)进行压缩。默认情况,WiredTiger通过snappy压缩算法对所有集合进行块压缩并对所有索引进行前缀压缩。Journal默认也会压缩。
####内存使用
MongoDB不仅利用WiredTiger内部缓存同时也利用文件系统缓存。在WiredTiger中可以自己指定内部缓存使用大小。
通过文件系统缓存,MongoDB自动使用所有未被WiredTiger缓存使用的或其他进程使用的空闲内存
####Snapshots和Checkpoints
WiredTiger通过类似copyOnWrite的方式实现了多版本并发控制(MVCC):在一个操作开始时,WiredTiger会拷贝该时间点的事务数据快照(snapshot)。快照表示的是内存中数据的一份一致性的视图。WiredTiger也会以数据一致的方式将快照中的所有数据写到磁盘所有数据文件中,并且记录一个检查点(checkpoint),这个检查点还可以扮演恢复点(recovery points)的角色,当MongoDB崩溃重启后,MongoDB可以从最后有效的检查点进行恢复。
####Journaling
虽然说checkpoint已经可以用于MongoDB意外情况下的数据恢复,但是在WiredTiger中,Journaling仍然有存在的意义。如果MongoDB在两个checkpoints之间意外退出,只能恢复到上个checkpoint。而上次checkpoint以来的修改,则需要通过Journaling来进行恢复。
#MongoDB 存储引擎之MMAPv1
MMAPv1是MMAP的升级版,是MongoDB官方最初开发的存储引擎。
MMAPv1是3.2版本之前的默认存储引擎。
##MMAPv1特性
####并发模型
MMAPv1很大一个问题是,锁粒度太粗,这严重影响了高并发下的读写性能。在version < 2.2的时候,只支持进程级别锁,即一个mongod实例一个锁。而2.2<= version < 2.8的时候,支持库级别锁,即一个DB一个锁。3.0 <= version的时候,支持集合级别的锁,即一个collection一个锁。
####内存使用
MMAPv1存储引擎使用内存映射文件的方式将所有的数据文件映射到内存中(至少要保证热数据(索引,数据及系统其它开销)都能装进内存),然后操作系统会托管所有数据刷新磁盘,以及管理内存页交换。MMAPv1会尽可能的使用系统中的所有空闲内存作为其缓存。
####Journal
MongoDB默认情况下会将所有修改先刷写到一个磁盘上的journal日志文件中,然后再刷写数据文件(刷写journaling相比刷写数据文件更为频繁)。Journaling因为是采用顺序写的方式,减少了随机IO,并且因为数据会先写到这个预写日志中,当MongoDB意外崩溃,重启时可以根据这个journaling文件进行数据恢复。
#MongoDB 存储引擎之In Memory
企业版才支持的存储引擎
默认存储在内存中
推荐在复制集中设置多个In Memory引擎节点+多个WiredTiger引擎的Hide节点存储,Hide节点主要用来做数据热备,保证数据不会丢失。
##In Memory特性
####并发模型
in-memory存储引擎使用文档级别锁来控制并发写操作,因此,多个客户端可以同时修改集合中不同的文档。
####内存使用
in-memory存储引擎需要将其所有数据(包括索引,oplog如果mongod是副本集的成员的话,等等)保存在内存中。通过–inMemorySizeGB或storage.inMemory.engineConfig.inMemorySizeGB 指定使用的内存大小,而上述的数据必须适合这个大小。否则,当一个写操作导致数据超出了指定的内存大小,MongoDB就会返回错误。
####持久化
因为In-Memory存储引擎将所有数据都保存在内存中(除了一些元数据和诊断数据),所以In-Memory不存在数据刷写到磁盘的流程,因此也没有Journaling之类的机制和日志文件。
####部署架构
如果只是单机部署以In-Memory作为存储引擎的MongoDB,由于数据不会持久化,如果作为数据库来考虑,对于大多数应用来说,这都是无法接受的。好在In-Memory也可以作为副本集或分片集群的一部分。比如,部署2台In-Memory节点作为主从节点,再部署一台WiredTiger作为隐藏的从节点,构成一个副本集,两台In-Memory节点承担业务的读写请求,另外一台WiredTiger则对用户透明,只作为从节点复制数据。这样既保留了In-Memory的低延迟读写特性,又使得数据不至于在In-Memory节点挂掉后彻底丢失。
MongoDB 存储引擎可以插件化(3.0开始提供插件化API),根据不同的场景选择不同的存储引擎,跟Mysql有点类似。
MongoDB 常用存储引擎:
WiredTiger,
MMAPv1,
In Memory
#MongoDB 存储引擎之WiredTiger
3.2版本开始WiredTiger已经是MongoDB的默认存储引擎。
WiredTiger支持文档级别的锁,检查点(checkpoint),压缩,等功能。企业版支持Rest加密。
##WiredTiger 特性
####并发模型
WiredTiger带来最显著的改进之一就是锁粒度的细化,它通过MVCC(通过copyOnWrite的方式实现的多版本并发控制)实现了文档级别的锁(多个客户端可以并发的修改一个集合中多个不同的文档),大大提高了并发读写的性能。
####数据压缩
WiredTiger带来的另一个显著提升是:通过使用高效的压缩算法对数据进行压缩,数据占用磁盘空间大大减少(最大能压缩80%的空间)。
压缩是以CPU计算为代价而减少了存储量,不过相比压缩带来的好处,牺牲这点CPU时间是值得的。
MongoDb支持对所有集合和索引(前缀)进行压缩。默认情况,WiredTiger通过snappy压缩算法对所有集合进行块压缩并对所有索引进行前缀压缩。Journal默认也会压缩。
####内存使用
MongoDB不仅利用WiredTiger内部缓存同时也利用文件系统缓存。在WiredTiger中可以自己指定内部缓存使用大小。
通过文件系统缓存,MongoDB自动使用所有未被WiredTiger缓存使用的或其他进程使用的空闲内存
####Snapshots和Checkpoints
WiredTiger通过类似copyOnWrite的方式实现了多版本并发控制(MVCC):在一个操作开始时,WiredTiger会拷贝该时间点的事务数据快照(snapshot)。快照表示的是内存中数据的一份一致性的视图。WiredTiger也会以数据一致的方式将快照中的所有数据写到磁盘所有数据文件中,并且记录一个检查点(checkpoint),这个检查点还可以扮演恢复点(recovery points)的角色,当MongoDB崩溃重启后,MongoDB可以从最后有效的检查点进行恢复。
####Journaling
虽然说checkpoint已经可以用于MongoDB意外情况下的数据恢复,但是在WiredTiger中,Journaling仍然有存在的意义。如果MongoDB在两个checkpoints之间意外退出,只能恢复到上个checkpoint。而上次checkpoint以来的修改,则需要通过Journaling来进行恢复。
#MongoDB 存储引擎之MMAPv1
MMAPv1是MMAP的升级版,是MongoDB官方最初开发的存储引擎。
MMAPv1是3.2版本之前的默认存储引擎。
##MMAPv1特性
####并发模型
MMAPv1很大一个问题是,锁粒度太粗,这严重影响了高并发下的读写性能。在version < 2.2的时候,只支持进程级别锁,即一个mongod实例一个锁。而2.2<= version < 2.8的时候,支持库级别锁,即一个DB一个锁。3.0 <= version的时候,支持集合级别的锁,即一个collection一个锁。
####内存使用
MMAPv1存储引擎使用内存映射文件的方式将所有的数据文件映射到内存中(至少要保证热数据(索引,数据及系统其它开销)都能装进内存),然后操作系统会托管所有数据刷新磁盘,以及管理内存页交换。MMAPv1会尽可能的使用系统中的所有空闲内存作为其缓存。
####Journal
MongoDB默认情况下会将所有修改先刷写到一个磁盘上的journal日志文件中,然后再刷写数据文件(刷写journaling相比刷写数据文件更为频繁)。Journaling因为是采用顺序写的方式,减少了随机IO,并且因为数据会先写到这个预写日志中,当MongoDB意外崩溃,重启时可以根据这个journaling文件进行数据恢复。
#MongoDB 存储引擎之In Memory
企业版才支持的存储引擎
默认存储在内存中
推荐在复制集中设置多个In Memory引擎节点+多个WiredTiger引擎的Hide节点存储,Hide节点主要用来做数据热备,保证数据不会丢失。
##In Memory特性
####并发模型
in-memory存储引擎使用文档级别锁来控制并发写操作,因此,多个客户端可以同时修改集合中不同的文档。
####内存使用
in-memory存储引擎需要将其所有数据(包括索引,oplog如果mongod是副本集的成员的话,等等)保存在内存中。通过–inMemorySizeGB或storage.inMemory.engineConfig.inMemorySizeGB 指定使用的内存大小,而上述的数据必须适合这个大小。否则,当一个写操作导致数据超出了指定的内存大小,MongoDB就会返回错误。
####持久化
因为In-Memory存储引擎将所有数据都保存在内存中(除了一些元数据和诊断数据),所以In-Memory不存在数据刷写到磁盘的流程,因此也没有Journaling之类的机制和日志文件。
####部署架构
如果只是单机部署以In-Memory作为存储引擎的MongoDB,由于数据不会持久化,如果作为数据库来考虑,对于大多数应用来说,这都是无法接受的。好在In-Memory也可以作为副本集或分片集群的一部分。比如,部署2台In-Memory节点作为主从节点,再部署一台WiredTiger作为隐藏的从节点,构成一个副本集,两台In-Memory节点承担业务的读写请求,另外一台WiredTiger则对用户透明,只作为从节点复制数据。这样既保留了In-Memory的低延迟读写特性,又使得数据不至于在In-Memory节点挂掉后彻底丢失。
存储引擎配置
通过mongod启动的时候指定参数--storageEngine或在配置文件中配置
storage.engine。
对比图解:

相关文章推荐
- Mongo3.4 Storage Engines存储引擎(将MongoDB实例更改为WiredTiger存储引擎)
- mysql5.5 主从复制 (触发器,函数,存储引擎,事件处理)说明
- MongoDB 数据存储引擎
- mysql存储过程简介和引擎说明
- MongoDB源码概述——内存管理和存储引擎
- Mongo3.4 Storage Engines存储引擎(将MongoDB实例更改为WiredTiger存储引擎)
- MongoDb 的 MMAPv1 和 WiredTiger 存储引擎空间对比(800万文档 )
- Mongo3.4 Storage Engines存储引擎(将MongoDB实例更改为WiredTiger存储引擎)
- 把mmapv1存储引擎存储的mongodb3.0数据库数据复制到WiredTiger存储引擎的mongodb3.2中
- 存储引擎配置引发的MongoDB启动失败
- MongoDB 存储引擎Wiredtiger原理剖析
- MongoDB 存储引擎:WiredTiger和In-Memory
- Mongo3.4 Storage Engines存储引擎(将MongoDB实例更改为WiredTiger存储引擎)
- mysql5.5 主从复制 (触发器,函数,存储引擎,事件处理)说明
- MongoDB 存储引擎:WiredTiger和In-Memory
- MongoDB Wiredtiger存储引擎实现原理
- Mongodb WireTiger 新式牛逼存储引擎
- mongodb底层存储和索引原理——本质是文档数据库,无表设计,同时wiredTiger存储引擎支持文档级别的锁,MMAPv1引擎基于mmap,二级索引(二级是文档的存储位置信息『文件id + 文件内offset 』)
- Mongo3.4 Storage Engines存储引擎(将MongoDB实例更改为WiredTiger存储引擎)
- mysql5.5 主从复制 (触发器,函数,存储引擎,事件处理)说明