Python 爬虫入门(三) HTTP协议请求方式
2017-03-15 17:59
633 查看
Python 爬虫入门(三)
HTTP协议请求方式
在爬虫中,经常会用到的两类请求方法分别是GET方法和POST方法。通常来说,直接通过浏览器在浏览器的网址处输入网站链接访问的方式成为GET方法。
而一般登录某些网站,进入个人中心的,网站常常采用POST方法。
接下来就一些比较简单基础的例子来介绍GET和POST方法。
GET方法
首先,我们打开浏览器,在浏览器地址栏中输入百度的网址https://www.baidu.com。打开网站后,点击鼠标右键,选择“检查”或者“审查元素”(不同浏览器可能不同)。
然后右侧或者浏览器下方会弹出一个界面。
在这个界面中,选择Network标签后,刷新页面,重新加载页面。
然后就可以在下方看到www.baidu.com这个页面文件
点击该页面文件,可以看到右侧的一些参数。
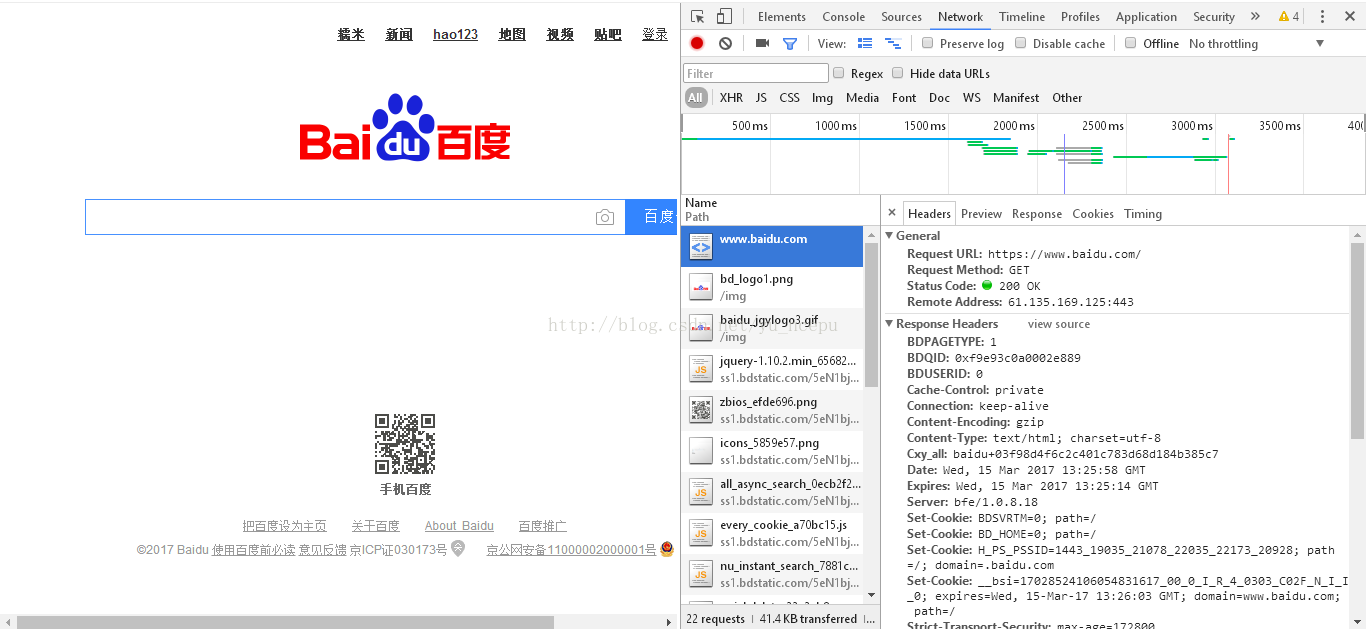
可以看到,在General栏,里面有我们的请求链接URL(Request URL)、请求方法:GET(Request Method)、状态码(Status Code):200 OK、远程地址(Remote Address):61.135.169.121:443
继续往下,可以看到我们的回复头(Response Headers)和请求头(Request Headers)。
关于请求头的作用,我们可以这样通俗的描述。由于http是个无状态的协议,所以,需要在请求头和响应头中包括自身的一些信息和想要执行的动作,这样,对方在收到信息后,就可以知道你是谁,你想干什么。
另外,请求头的一些内容我们会在以后的章节详细说明。
然后,我们在百度一下的编辑框里,键入我们需要查询的信息,这个时候,我们就跳转到另外一个连接地址。可以看到,地址栏的信息变成了如下:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&ch=15&tn=56060048_4_pg&wd=12306&oq=xxx&rsv_pq=eaade694000148cd&rsv_t=4f931tCYmcOWQ6piZUjDA+upsXK/d2xGYsd8Q1qjVhWjoTHkYCG3H/6ON+guWR2NAp039A&rqlang=cn&rsv_enter=1&inputT=7213&rsv_sug3=14&rsv_sug1=11&rsv_sug7=100&rsv_sug2=0&rsv_sug4=7214
观察上述网址,结合第二节Python HTTP初步中的内容,我们可以看到,从问号“?”以后,都是一些xx=xxx的格式,并且用“&”符号来进行分割。而之前说到过,"?"后面的是GET方法传入的参数,用于服务器进行选择判断查询的一些参数。
因此,看到这里,我们可以大致了解GET方法需要的几大版块,分别是带有GET参数(非查询型访问也可以不带GET参数)的URL、带有一些自身信息和要执行操作的请求头(Request Headers)
POST方法
同样,和GET中的方法一样,我们在浏览器中输入12306的购票URL,https://kyfw.12306.cn/otn/。访问该网站。点击鼠标右键,点击“审查元素”或者“检查”,选中Network标签,然后填写需要购票的一些信息,点击查询购票。然后点击init页面文件。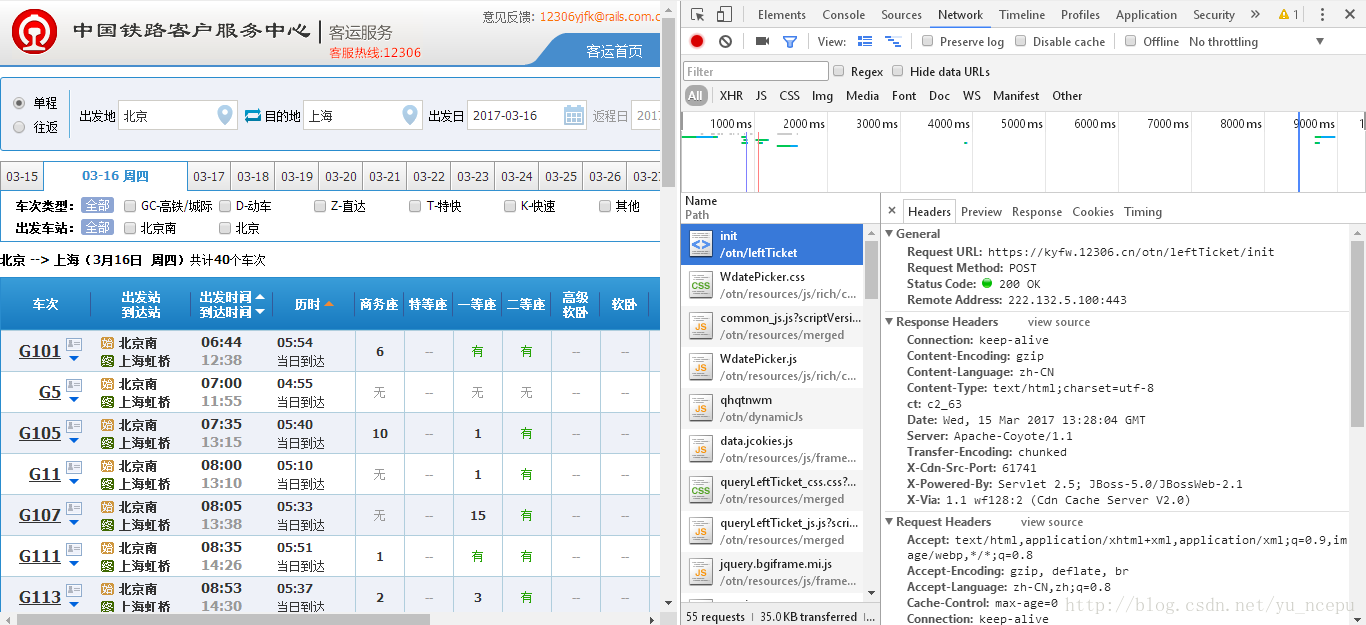
我们可以看到,这次HTTP请求方式采用的是POST方法,同样具有回复头和请求头,继续往下,我们可以看到具有与GET方法不同的一栏:Form Data
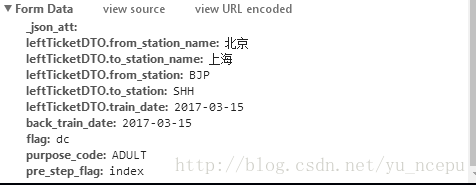
观测其中的字段和数据信息,我们可以看到和我们填写的购票信息一致。
因此我们可以知道POST方法是需要向服务器提交一部分Data数据来获得回复网页数据。
因此,如果我们想抓取火车票票额信息的话,我们就得用python实现POST方法,提交我们的查询的列车信息。
GET和POST的简单的区别:
| GET | POST | |
| 点击返回/刷新按钮 | 没有影响 | 数据会重新发送(浏览器将会提示用户“数据被从新提交”) |
| 添加书签 | 可以 | 不可以 |
| 缓存 | 可以 | 不可以 |
| 编码类型(Encoding type) | application/x-www-form-urlencoded | application/x-www-form-urlencoded or multipart/form-data. 请为二进制数据使用multipart编码 |
| 历史记录 | 有 | 没有 |
| 长度限制 | 有 | 没有 |
| 数据类型限制 | 只允许ASCII字符类型 | 没有限制。允许二进制数据 |
| 安全性 | 查询字符串会显示在地址栏的URL中,不安全,请不要使用GET请求提交敏感数据 | 因为数据不会显示在地址栏中,也不会缓存下来或保存在浏览记录中,所以看POST求情比GET请求安全,但也不是最安全的方式。如需要传送敏感数据,请使用加密方式传输 |
| 可见性 | 查询字符串显示在地址栏的URL中,可见 | 查询字符串不会显示在地址栏中,不可见 |
状态码在HTTP协议中的有着比较重要的作用,用于告诉浏览器服务器是否做出正确响应,是否出现相关问题。
常见的状态码如下:
200 – 服务器成功返回网页
404 – 请求的网页不存在
503 – 服务不可用
1xx(临时响应)
表示临时响应并需要请求者继续执行操作的状态代码。
附一些简单的状态码说明:
代码 说明
100 (继续) 请求者应当继续提出请求。 服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。
101 (切换协议) 请求者已要求服务器切换协议,服务器已确认并准备切换。
2xx (成功)
表示成功处理了请求的状态代码。
代码 说明
200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。
201 (已创建) 请求成功并且服务器创建了新的资源。
202 (已接受) 服务器已接受请求,但尚未处理。
203 (非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。
204 (无内容) 服务器成功处理了请求,但没有返回任何内容。
205 (重置内容) 服务器成功处理了请求,但没有返回任何内容。
206 (部分内容) 服务器成功处理了部分 GET 请求。
3xx (重定向)
表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。
代码 说明
300 (多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。
301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
303 (查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。
304 (未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。
305 (使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。
307 (临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
4xx(请求错误)
这些状态代码表示请求可能出错,妨碍了服务器的处理。
代码 说明
400 (错误请求) 服务器不理解请求的语法。
401 (未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
403 (禁止) 服务器拒绝请求。
404 (未找到) 服务器找不到请求的网页。
405 (方法禁用) 禁用请求中指定的方法。
5xx(服务器错误)
这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。
代码 说明
500 (服务器内部错误) 服务器遇到错误,无法完成请求。
501 (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。
502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。
504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505 (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
有关状态码的相关详细信息可以访问w3对状态码的定义
https://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html

相关文章推荐
- Python3爬虫从入门到自残(一):基本连接和请求
- python爬虫入门教程--快速理解HTTP协议(一)
- Python 爬虫入门(二) HTTP协议初步
- Python爬虫入门2--请求(HTTP)
- 03精通Python网络爬虫——HTTP协议请求实战
- python爬虫入门-发送请求
- 菜鸟python入门爬虫手记
- python网络爬虫入门(一)——简单的博客爬虫
- Android 以Http协议 使用get和post方式请求站点
- [Python]网络爬虫(12):爬虫框架Scrapy的第一个爬虫示例入门教程
- HTTP协议请求的几种方式
- Python 爬虫如何入门学习?
- Python 爬虫如何入门学习?
- python的get和post方式请求详解
- python爬虫入门教程之糗百图片爬虫代码分享
- python爬虫入门教程之点点美女图片爬虫代码分享
- python Scrapy 框架做爬虫 ——入门地图
- Python 学习入门(6)—— 网页爬虫
- python的get和post方式请求详解
- Python 学习入门(6)—— 网页爬虫