导出SQL运行结果的方法总结
2017-03-15 11:09
274 查看
本文通过几个例子,介绍了几种下载MaxCompute SQL计算结果的方法。为了减少篇幅,所有的SDK部分都只举例介绍Java的例子。
SQLTask是SDK直接调用MaxCompute SQL的接口,能很方便得运行SQL并获得其返回结果。
从文档可以看到,SQLTask.getResult(i); 返回的是一个List。用户可以循环迭代这个List,获得完整的SQL计算返回结果。不过这个方法有个缺陷,可以参考这里这里提到的SetProject
READ_TABLE_MAX_ROW的功能。目前Select语句返回给客户端的数据条数最大可以调整到1万。也就是说如果在客户端上(包括SQLTask)直接Select,那相当于查询结果上最后加了个Limit N(如果是CREATE TABLE XX AS SELECT或者用INSERT INTO/OVERWRITE TABLE把结果固化到具体的表里就没关系)。
如果需要导出的查询结果就是某张表的全部内容(或者是具体的某个分区的全部内容),可以用Tunnel来做。官网提供了命令行工具和基于SDK编写的Tunnl
SDK。为了简单起见,这里就只提供一个命令行导出数据的例子,Tunnel SDK的编写是在有一些命令行没办法支持的情况下才需要考虑。具体需要用的时候看下文档好了。
可以看到,SQLTask不能处理超过1万条记录,但是Tunnel刚好可以,两者存在互补。所以可以基于两者实现数据的导出。以下用一个代码的例子来实现:
有时候我们希望把数据导出后用文本文件来保存,但是有时候会希望保存到数据库或者其他的别的什么地方。为了避免重复造轮子,阿里开源了工具DataX。通过配置配置文件,可以很方便的导出MaxCompute里的数据到目标数据源。
工具的安装自不必多说,关于插件的配置,可以看到有分为Reader和Writer,还有一个用来配置整个任务的诸如速度并发限制的Setting。通过配置Reader和Writer,可以很方便地适配不同的数据源。
细心的你可能已经发现,这个解掉了数据下载后保存的问题,但是还是没解决数据的生成以及两个步骤之间的调度依赖的问题。
这里隆重为大家介绍阿里云大数据开发套件这个产品,我们可以在里面运行SQL、配置任务同步(基于dataX实现),还可以设置自动周期性运行还有多任务之间的依赖,彻底解决了前面的所有烦恼。
我们先创建一个工作流,里面可以有一个SQL节点和一个数据同步节点。如图
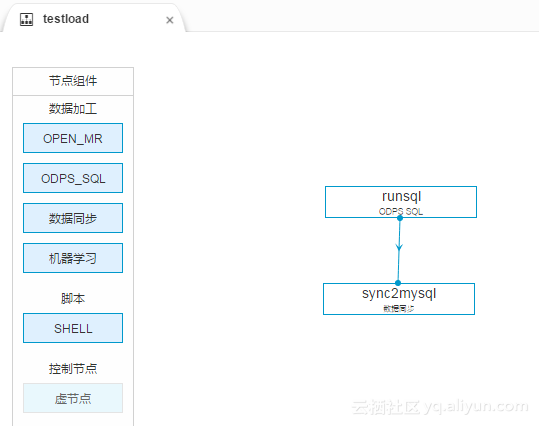
里面配置的SQL作业和同步作业的配置如图:
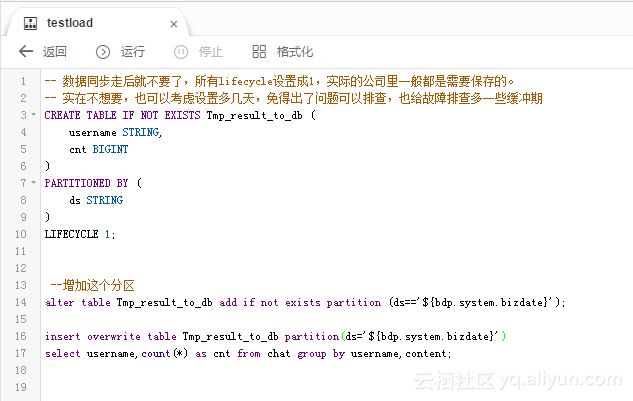
注意SQL这里的创建表我先执行了一下再去配置同步(否则表都没有,同步任务没办法配置)
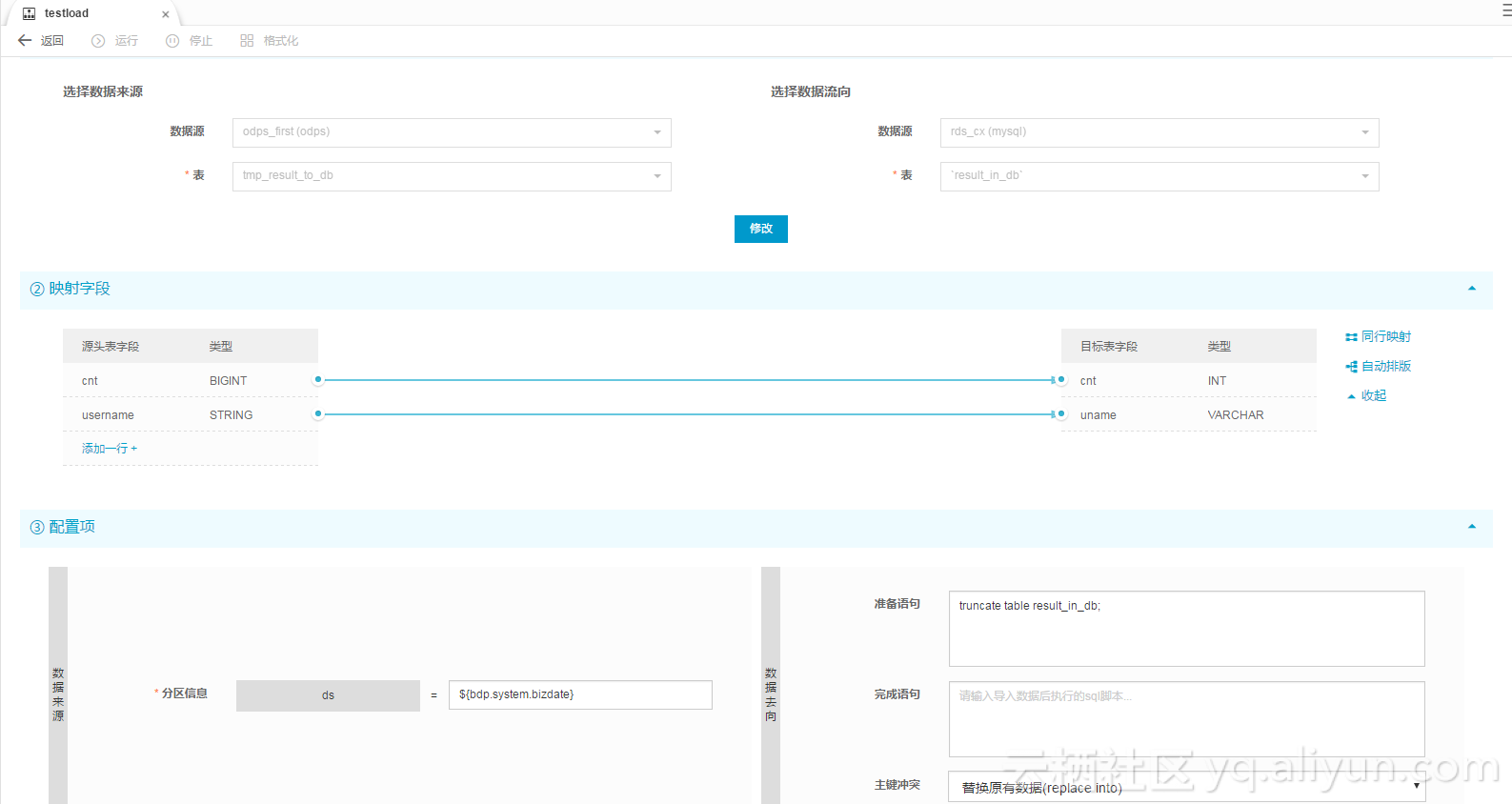
运行测试后,可以看到日志里显示
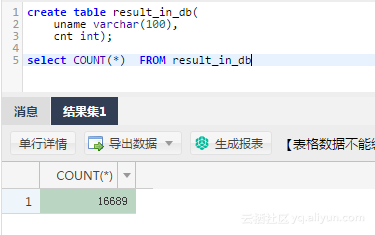
到mysql里查一下,数据也进去了。
如果数据比较少,我们可以直接用SQLTask得到全部的查询结果。
如果只是想导出某个表或者分区,可以用Tunnel直接导出数据。
如果SQL比较复杂,需要Tunnel和SQL相互配合才行。
开源工具DataX能帮助我们很方便把MaxCompute里的数据导出到目标数据源。
大数据开发套件可以方便地帮我们运行SQL,同步数据,并有定时调度,配置任务依赖的功能。
原文链接:
SQLTask
SQLTask是SDK直接调用MaxCompute SQL的接口,能很方便得运行SQL并获得其返回结果。从文档可以看到,SQLTask.getResult(i); 返回的是一个List。用户可以循环迭代这个List,获得完整的SQL计算返回结果。不过这个方法有个缺陷,可以参考这里这里提到的SetProject
READ_TABLE_MAX_ROW的功能。目前Select语句返回给客户端的数据条数最大可以调整到1万。也就是说如果在客户端上(包括SQLTask)直接Select,那相当于查询结果上最后加了个Limit N(如果是CREATE TABLE XX AS SELECT或者用INSERT INTO/OVERWRITE TABLE把结果固化到具体的表里就没关系)。
Tunnel
如果需要导出的查询结果就是某张表的全部内容(或者是具体的某个分区的全部内容),可以用Tunnel来做。官网提供了命令行工具和基于SDK编写的TunnlSDK。为了简单起见,这里就只提供一个命令行导出数据的例子,Tunnel SDK的编写是在有一些命令行没办法支持的情况下才需要考虑。具体需要用的时候看下文档好了。
>tunnel d wc_out c:\wc_out.dat; 2016-12-16 19:32:08 - new session: 201612161932082d3c9b0a012f68e7 total lines: 3 2016-12-16 19:32:08 - file [0]: [0, 3), c:\wc_out.dat downloading 3 records into 1 file 2016-12-16 19:32:08 - file [0] start 2016-12-16 19:32:08 - file [0] OK. total: 21 bytes download OK
SQLTask+Tunnel
可以看到,SQLTask不能处理超过1万条记录,但是Tunnel刚好可以,两者存在互补。所以可以基于两者实现数据的导出。以下用一个代码的例子来实现:private static final String accessId = "userAccessId";
private static final String accessKey = "userAccessKey";
private static final String endPoint = "http://service.odps.aliyun.com/api";
private static final String project = "userProject";
private static fi
4000
nal String sql = "userSQL";
private static final String table = "Tmp_" + UUID.randomUUID().toString().replace("-", "_");//其实也就是随便找了个随机字符串作为临时表的名字
private static final Odps odps = getOdps();
public static void main(String[] args) {
System.out.println(table);
runSql();
tunnel();
}
/*
* 把SQLTask的结果下载过来
* */
private static void tunnel() {
TableTunnel tunnel = new TableTunnel(odps);
try {
DownloadSession downloadSession = tunnel.createDownloadSession(
project, table);
System.out.println("Session Status is : "
+ downloadSession.getStatus().toString());
long count = downloadSession.getRecordCount();
System.out.println("RecordCount is: " + count);
RecordReader recordReader = downloadSession.openRecordReader(0,
count);
Record record;
while ((record = recordReader.read()) != null) {
consumeRecord(record, downloadSession.getSchema());
}
recordReader.close();
} catch (TunnelException e) {
e.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
/*
* 保存这条数据
* 数据量少的话直接打印后拷贝走也是一种取巧的方法。实际场景可以用Java.io写到本地文件,或者写到远端数据等各种目标保存起来。
* */
private static void consumeRecord(Record record, TableSchema schema) {
System.out.println(record.getString("username")+","+record.getBigint("cnt"));
}
/*
* 运行SQL,把查询结果保存成临时表,方便后面用Tunnel下载
* 这里保存数据的lifecycle为1天,所以哪怕删除步骤出了问题,也不会太浪费存储空间
* */
private static void runSql() {
Instance i;
StringBuilder sb = new StringBuilder("Create Table ").append(table)
.append(" lifecycle 1 as ").append(sql);
try {
System.out.println(sb.toString());
i = SQLTask.run(getOdps(), sb.toString());
i.waitForSuccess();
} catch (OdpsException e) {
e.printStackTrace();
}
}
/*
* 初始化MaxCompute(原ODPS)的连接信息
* */
private static Odps getOdps() {
Account account = new AliyunAccount(accessId, accessKey);
Odps odps = new Odps(account);
odps.setEndpoint(endPoint);
odps.setDefaultProject(project);
return odps;
}
工具实现
有时候我们希望把数据导出后用文本文件来保存,但是有时候会希望保存到数据库或者其他的别的什么地方。为了避免重复造轮子,阿里开源了工具DataX。通过配置配置文件,可以很方便的导出MaxCompute里的数据到目标数据源。工具的安装自不必多说,关于插件的配置,可以看到有分为Reader和Writer,还有一个用来配置整个任务的诸如速度并发限制的Setting。通过配置Reader和Writer,可以很方便地适配不同的数据源。
云产品
细心的你可能已经发现,这个解掉了数据下载后保存的问题,但是还是没解决数据的生成以及两个步骤之间的调度依赖的问题。这里隆重为大家介绍阿里云大数据开发套件这个产品,我们可以在里面运行SQL、配置任务同步(基于dataX实现),还可以设置自动周期性运行还有多任务之间的依赖,彻底解决了前面的所有烦恼。
我们先创建一个工作流,里面可以有一个SQL节点和一个数据同步节点。如图
里面配置的SQL作业和同步作业的配置如图:
注意SQL这里的创建表我先执行了一下再去配置同步(否则表都没有,同步任务没办法配置)
运行测试后,可以看到日志里显示
2016-12-17 23:43:46.394 [job-15598025] INFO JobContainer - 任务启动时刻 : 2016-12-17 23:43:34 任务结束时刻 : 2016-12-17 23:43:46 任务总计耗时 : 11s 任务平均流量 : 31.36KB/s 记录写入速度 : 1668rec/s 读出记录总数 : 16689 读写失败总数 : 0
到mysql里查一下,数据也进去了。
总结
如果数据比较少,我们可以直接用SQLTask得到全部的查询结果。如果只是想导出某个表或者分区,可以用Tunnel直接导出数据。
如果SQL比较复杂,需要Tunnel和SQL相互配合才行。
开源工具DataX能帮助我们很方便把MaxCompute里的数据导出到目标数据源。
大数据开发套件可以方便地帮我们运行SQL,同步数据,并有定时调度,配置任务依赖的功能。
原文链接:
| http://click.aliyun.com/m/13933/ |

相关文章推荐
- 导出SQL运行结果的方法总结
- 导出SQL运行结果的方法总结
- postgresql导出sql执行结果到文件的方法(转)
- 【总结】Oracle查看SQL执行计划和运行效率指标的方法
- 命令行下把SQL结果导出到文本文件的方法小结
- Oracle & SQL 查询结果导出到文本中方法
- postgresql导出sql执行结果到文件的方法
- SQL查询结果导出XML文件简单的方法
- SQL查询结果导出XML文件简单的方法
- 教你查找运行系统里低劣的SQL方法
- Transact-SQL进行数据导入导出方法
- 让程序只运行一个实例的方法总结[转]
- Transact-SQL进行数据导入导出方法
- MS SQL Server 2000版在windows server 2003企业版系统上运行时造成数据库suspect的解决方法
- 使用Transact-SQL进行数据导入导出方法详
- SQL数据导入导出总结
- SQL数据导入导出问题总结
- MS SQL Server 2000版在windows server 2003企业版系统上运行时造成数据库suspect的解决方法
- 关于SQL导入导出的方法大全(从网上摘抄)
- 关于SQL导入导出的方法大全(从网上摘抄)