程序的实现过程(编译、链接、执行)
2017-03-14 17:48
211 查看
在ANSI C的任何一种实现中,存在两个不同的环境
第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令。
第2种是执行环境,它用于实际执行代码。
标准明确说明:这两种环境不必位于同一台机器上。
例如,交叉编译器就是在同一台机器上运行,但它所产生的可执行代码运行于不同类型的机器上。操作系统也是这样。
在翻译阶段,程序实现过程如下图:
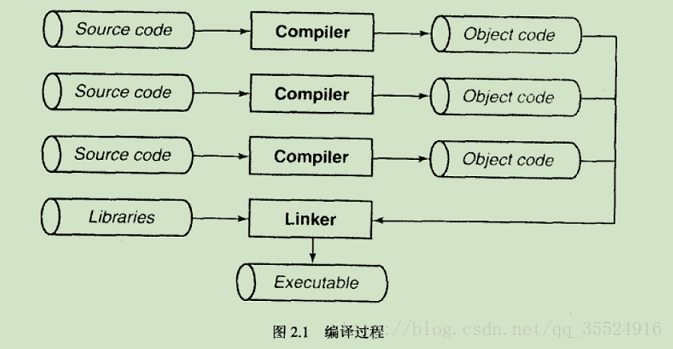
翻译阶段的两个步骤:
组成一个程序的每个源文件(source code)通过编译过程分别转换成目标代码(object code)。
每个目标文件由
链接器(linker)捆绑在一起,形成一个单一而完整的可执行程序(executable)。
注:链接器同时也会引入标准C函数库中任何被该程序所用到的函数,并且它可以搜索程序员个人的程序库,将其需要的函数也链接到程序中。
而编译本身也分为三个阶段组成:
预处理器(preprocessor)处理--预编译。 在这个阶段,预处理器在源代码上执行一些文本操作。
源代码经过解析,判断它的语句的意思。这个阶段产生绝大多数的错误和警告。
形成符号表,产生目标代码。
下面截图表示程序在翻译阶段的具体功能:
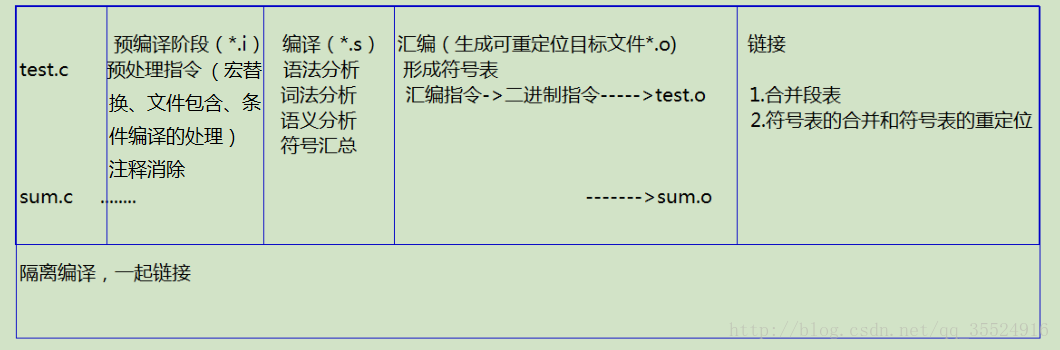
注:
①文件后缀名*.i、*.s、*.o在类unix系统中,可通过gcc相关命令生成对应文件。
②符号表:在计算机科学中,符号表是一种用于语言翻译器(例如编译器和解释器)中的数据结构。在符号表中,程序源代码中的每个标识符都和它的声明或使用信息绑定在一起,比如其数据类型、作用域以及内存地址。符号表在编译程序工作的过程中需要不断收集、记录和使用源程序中一些语法符号的类型和特征等相关信息。这些信息一般以表格形式存储于系统中。如常数表、变量名表、数组名表、过程名表、标号表等等,统称为符号表。
程序执行的过程:
程序必须载入内存中(由冯曼依诺计算机体系决定)。在有操作系统的环境中:一般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
程序的执行便开始。接着便调用main函数。
开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留他们的值。
终止程序。正常终止main函数;也有可能是意外终止。
运行时和编译时的本质:
像标志符(类型名、变量名、函数名等)、类型定义、const关键字、访问限定符(public/private/protected)、引用(&)等只是存在于源码中,他们不会被带入二进制可执行程序中,这是“编译时”的本质。
存在于二进制可执行程序中的只是指令、地址和数据,没有别的东西(实际上地址也是数据的一种),这就是“运行时”的本质。
C/C++源代码中的语句、指针和变量都将被转化成二进制程序中的指令、地址和数据。因此,通过名字直接引用一个变量、对象即其成员,这样的代码在编译和链接完成后,实际上都被转换成了通过变量、对象或成员变量的地址(即内存元的地址)进行访问。
第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令。
第2种是执行环境,它用于实际执行代码。
标准明确说明:这两种环境不必位于同一台机器上。
例如,交叉编译器就是在同一台机器上运行,但它所产生的可执行代码运行于不同类型的机器上。操作系统也是这样。
在翻译阶段,程序实现过程如下图:
翻译阶段的两个步骤:
组成一个程序的每个源文件(source code)通过编译过程分别转换成目标代码(object code)。
每个目标文件由
链接器(linker)捆绑在一起,形成一个单一而完整的可执行程序(executable)。
注:链接器同时也会引入标准C函数库中任何被该程序所用到的函数,并且它可以搜索程序员个人的程序库,将其需要的函数也链接到程序中。
而编译本身也分为三个阶段组成:
预处理器(preprocessor)处理--预编译。 在这个阶段,预处理器在源代码上执行一些文本操作。
源代码经过解析,判断它的语句的意思。这个阶段产生绝大多数的错误和警告。
形成符号表,产生目标代码。
下面截图表示程序在翻译阶段的具体功能:
注:
①文件后缀名*.i、*.s、*.o在类unix系统中,可通过gcc相关命令生成对应文件。
②符号表:在计算机科学中,符号表是一种用于语言翻译器(例如编译器和解释器)中的数据结构。在符号表中,程序源代码中的每个标识符都和它的声明或使用信息绑定在一起,比如其数据类型、作用域以及内存地址。符号表在编译程序工作的过程中需要不断收集、记录和使用源程序中一些语法符号的类型和特征等相关信息。这些信息一般以表格形式存储于系统中。如常数表、变量名表、数组名表、过程名表、标号表等等,统称为符号表。
程序执行的过程:
程序必须载入内存中(由冯曼依诺计算机体系决定)。在有操作系统的环境中:一般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
程序的执行便开始。接着便调用main函数。
开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留他们的值。
终止程序。正常终止main函数;也有可能是意外终止。
运行时和编译时的本质:
像标志符(类型名、变量名、函数名等)、类型定义、const关键字、访问限定符(public/private/protected)、引用(&)等只是存在于源码中,他们不会被带入二进制可执行程序中,这是“编译时”的本质。
存在于二进制可执行程序中的只是指令、地址和数据,没有别的东西(实际上地址也是数据的一种),这就是“运行时”的本质。
C/C++源代码中的语句、指针和变量都将被转化成二进制程序中的指令、地址和数据。因此,通过名字直接引用一个变量、对象即其成员,这样的代码在编译和链接完成后,实际上都被转换成了通过变量、对象或成员变量的地址(即内存元的地址)进行访问。

相关文章推荐
- C/C++——程序实现过程之编译、链接和执行
- 【编译原理】程序的编译链接执行过程
- 简单汇编程序编译链接执行过程
- Linux程序编译执行原理之一:预处理-编译-汇编-链接过程分析
- 菜鸟C++精髓学习笔记--C++程序内部执行过程(预处理、编译、链接过程的作用)
- 深度剖析一个典型的C/C++程序的编译、链接以及执行的过程
- VC++程序编译链接的原理与过程
- C/C++程序从编译到最终生成可执行文件的过程分析
- C程序编译执行过程
- VC++程序编译链接的原理与过程(QQ dhms)
- VC如何在编译链接程序过程中在输出窗口看到链接的顺序
- C程序编译执行过程
- VC++程序编译链接的原理与过程
- PL/0语言编译程序整理实现:(8)、代码执行
- 详细分析make uboot 最后的编译链接的具体执行过程
- C程序编译执行过程
- 代码文件-预编译-编译-汇编-链接-可执行程序
- 详细分析make uboot 最后的编译链接的具体执行过程
- C++程序从编译到链接然后再到调用的整个过程
- C程序编译执行过程