JDK 1.8 HashMap 源码阅读一
2017-03-09 19:06
483 查看
HashMap中数据的存储模式
一般数据结构均由数组和链表组成,HashMap的存储模式也不列外:数组+链表在JDK1.8中不同于之前的版本,其数据存储在内置类Node或TreeNode中。
实际上通过源码可以发现,TreeNode是Node的子类。也就是说,数据实际上还是存储在Node中。
Node的定义:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
......
}TreeNode的定义:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
.......
}在源代码中我们能看到如下的定义:
transient Node<K,V>[] table;
当我们往HashMap放入数据时,他会根据KEY的hash值与数组容量进行计算(hash%Capacity)来确定数据应属于数组中哪个bucket。若是没冲突,这数组就是第一层数据存储的地方。若是有冲突这数组则成为了链表的头结点,新元素以链表的形式接续其后。用如下代码,在DEBUG模式下查看table中数据的存储形式:
public class Main {
public static void main(String[] args) {
HashMap<Integer,String> map = new HashMap<Integer,String>();
map.put(1, "1");
map.put(2, "2");
map.put(17, "17");
map.put(18, "18");
for(Integer i: map.keySet()){
System.out.println(map.get(i));
}
}
}如下图所示:
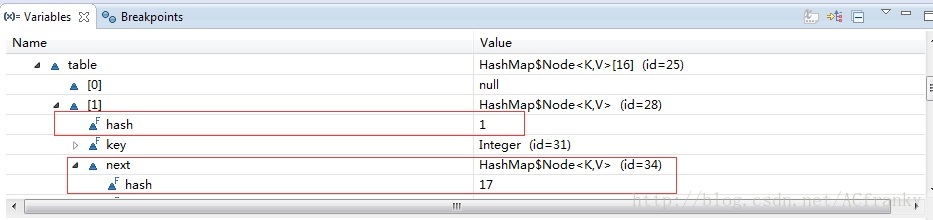
在JDK1.8中当HashMap中数组长度的达到一个门阀值并且其单一链表长度也超过一个门阀值时,其将会改用TreeNode来保存数据,并构建红黑树组织该原链表中的元素。用如下代码,在DEBUG模式下查看table中数据的存储形式:
public static void main(String[] args) {
HashMap<Integer,String> map = new HashMap<Integer,String>();
for(int i = 1, value = 0 ; i <= 200 ; i ++, value += 16){
map.put(value, Integer.toString(value));
}
for(Integer i: map.keySet()){
System.out.println(map.get(i));
}
}如下图所示,通过table的类就可得知该情况下其改用了红黑树的结构来存储数据。
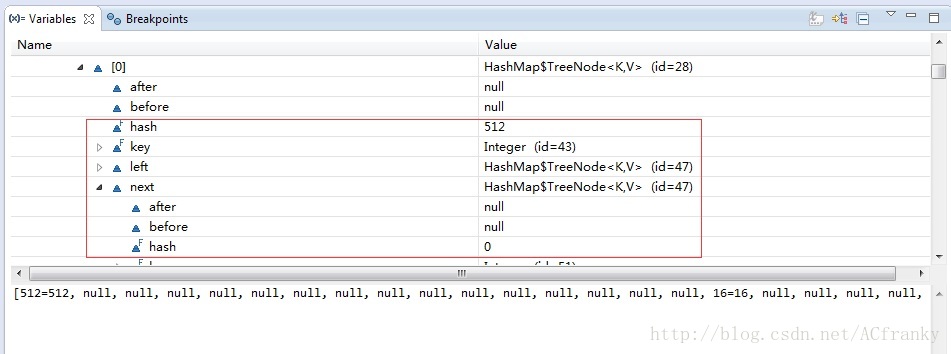
HashMap中一些关键属性值
那么HashMap是如何决策其bucket大小?如何将单链表改成黑红树呢?下面是一些HashMap的关键熟悉
DEFAULT_INITIAL_CAPACITY
/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
该值定义了HashMap中bucket的默认大小为16.通过注释我们知道bucket的大小必须为2的次幂数。这是为什么呢?在下面的模块在加以说明。
MAXIMUM_CAPACITY
static final int MAXIMUM_CAPACITY = 1 << 30;
限定了bucket大小的上限为2的30次方。
DEFAULT_LOAD_FACTOR
/** * The load factor used when none specified in constructor. */ static final float DEFAULT_LOAD_FACTOR = 0.75f;
负载因子默认为0.75,可以在创建是更改。当bucket的容量使用3/4时,bucket就会扩容为原来的2倍。
TREEIFY_THRESHOLD
/** * The bin count threshold for using a tree rather than list for a * bin. Bins are converted to trees when adding an element to a * bin with at least this many nodes. The value must be greater * than 2 and should be at least 8 to mesh with assumptions in * tree removal about conversion back to plain bins upon * shrinkage. */ static final int TREEIFY_THRESHOLD = 8;
限定了单链表的上限值。当单链表长度超过8时,就将考虑通过扩容bucket或改用红黑树来组织数据了。
MIN_TREEIFY_CAPACITY
/** * The smallest table capacity for which bins may be treeified. * (Otherwise the table is resized if too many nodes in a bin.) * Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts * between resizing and treeification thresholds. */ static final int MIN_TREEIFY_CAPACITY = 64;
限定了改用树形组织数据的最小元素值。与TREEIFY_THRESHOLD配合使用,当单链表长度超过8并且该map中有64个元素以上时,将原本超过8长度的单链表该为树形结构。
HashMap的Put方法的实现
在JDK1.8版本中,实际上的增加元素方法不是put而是putVal。个人觉得,之所以嵌套一个是为了向下兼容。public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}如下putVal的源码,我们会发现他多了3个参数值:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict)
c0e7
{
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) //插入第一个元素时,建bucket
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)//定位的bucket为空时,直接新建节点
tab[i] = newNode(hash, key, value, null);
else { //bucket不为空时,若e为空则不存在相同hashcode且相同key的元素
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)//树形结构插入节点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { //bucket中未匹配到,开始单链表的匹配直至该链表最后一元素
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { //最后一节点仍未匹配到,为新元素建节点兵连接
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash); //查过门阀值,考虑树形存储
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value; //找到hashcode与key相同的元素,覆盖原值
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold) //当前map中元素个数超过门阀值,扩容bucket大小。
resize();
afterNodeInsertion(evict);
return null;
}从上面源码与我的注解中,我们可以得到如下结论:
- HashMap未对KEY做null过滤,即我们能够用null做为key值。(null的hash值为0)
- HashMap对VALUE知识做简单的赋值和对比,也未做null过滤,即我们能够用null作为value值
- HashMap判断元素时,是同时通过其hash值和KEY值本身的。(同时用到hashcode和equals方法)
- HashMap中不存在完全相同的键值对,如遇到,后加入的将覆盖前者
- HashMap中数据在单一链表中的存储顺序即插入顺序
对于第6行代码,定位bucket的计算简而言之即为hashcode%CAPACITY-1(bucket容量)。
算法如下,根据定义CAPACITY的值总是2的次幂数如16,32,64等。
减1后其二进制表示为1111,11111,111111,一连串的低位1。
以16为例,任何数与1111做与操作得到的为原数二进制表示的低四位。
众所周知,在二进制表示时高位的1总是低位的1倍数:
如1010中,左数第一个1表示8,第二个1表示2,8是2的倍数。
无论高位值是什么数,只要其低2位为0,其就是4的倍数。只要其低3位为0,其就是8倍数,以此类推。
所以有如下结论,一个数二进制表示时其低N位的值就是该数对2^(n+1)取模值。
这也就是限定bucket容量值为2的次幂数的一个原因。(个人见解)
另一原因在于如下函数:(个人见解)
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}该函数用以返回一个比给定数大且最接近给定数的2次方数。实现按已有元素个数重置bucket大小。该方法通过5次补零左移来找到该数。
从n >>> 1可知该操作使原数二进制表示的次高位置为1, 在与本身与即使二进制表示时最高2位置为1;
在最高2位均为1的前提下 n |= n >>> 2;就是将高4位都置为1,依次类推。
上述的5次补零左移实现了将n在二进制表示下从最高位直至最低位均置为1。
如n = 64 = 1000000
n |= n >>> 1:
| n | 1000000 |
|---|---|
| n>>>1 | 0100000 |
| 新n | 1100000 |
| n | 1100000 |
|---|---|
| n>>>2 | 0011000 |
| 新n | 1111000 |
| n | 1111000 |
|---|---|
| n>>>4 | 0000111 |
| 新n | 1111111 |
所以5次操作后n为1111111。加1后为10000000=128。
符合函数定义要求。
HashMap中bucket扩容操作
HashMap中在完成插入操作后会决定是否将bucket扩容。既然bucket扩容了,也就意味着元素的移动。
如下是是元素移动的关键代码:
for (int j = 0; j < oldCap; ++j) {//对bucket循环处理
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null) //当前链表仅一个元素时
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode) //树形情况下的拆分
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//单链表下的拆分
Node<K,V> loHead = null, loTail = null; //保存低位置的新单链表
Node<K,V> hiHead = null, hiTail = null; //保存高位置的新单链表
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//将新链表放到bucket上。
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}为什么是拆分成2个链表呢?
因为扩容是容量翻倍,即16到32,32到64.
那么对于同一链表中的hashcode值,对新值取模时就只有2中情况。保持原样-加上久容量值。
例如 hashcode值为5,21,37,53的单链表,对16取模时均为5再同一链表上。
当扩容时,对新值32取模时值为5,21,5,21。 其值只有2种可能5 和 5 + 16。
所以只需拆分成2个链表。
我们注意到,在拆分时是顺序遍历链表的也是后链方式生成新链表的。也就是说即使拆分后的新链表,也保证了同一链表中的顺序即插入顺序。
由上诉代码可知:
扩容后的有值bucket数量最多是扩容前的2倍。
扩容过程中同一链表中始终保持这元素的插入顺序
时间有限,今天先学习到此。
以上均为个人学习理解,如有错误拜谢指教。:-)

相关文章推荐
- JDK 1.8 HashMap 源码阅读二
- jdk 1.8 hashmap resize 源码阅读
- Java Jdk1.8 HashMap源码阅读
- Java Jdk1.8 HashMap源码阅读笔记二
- Java Jdk1.8 HashMap源码阅读笔记一
- [JDK1.7源码阅读]HashMap
- JDK1.8 HashMap 源码分析
- 【集合框架】JDK1.8源码分析之HashMap(一)
- HashMap源码和JDK1.8以后的一些变化
- JDK1.8 HashMap源码分析
- HashMap源码分析(jdk1.8)
- JDK1.8源码阅读系列之二:LinkedList
- JDK 1.7源码阅读笔记(七)集合类之HashMap
- Java类集框架之HashMap(JDK1.8)源码剖析
- JDK1.8 HashMap源码分析
- jdk1.8 J.U.C并发源码阅读------ReentrantReadWriteLock源码解析
- 【JDK1.8】JDK1.8集合源码阅读——IdentityHashMap
- 【集合框架】JDK1.8源码分析之HashMap & LinkedHashMap迭代器(三)
- JDK1.8源码学习之ConcurrentHashMap.java
- HashMap 源码分析(JDK1.8)