20170228#cs231n#5.Neural Networks Part 1神经网络1 /Assignment1-NeuralNetwork
2017-02-28 10:28
246 查看
Neural Networks Part 1: Setting up the Architecture
这个是NeuralNetwork的计算公式s=W2max(0,W1x)x [3072×1] W1[100×3072] W2 [10×100]
max函数是一个非线性函数,与我们之前的不同,正是因为这个改变使得其与线性函数不同。
参数W1,W2将通过SGD随机梯度下降来学习,用bakcpropagation反向传播通过链式法则来求得梯度
s=W3max(0,W2max(0,W1x))
可以看做是一个三层神经网络,中间隐层的尺寸是一个超参数
生物表示
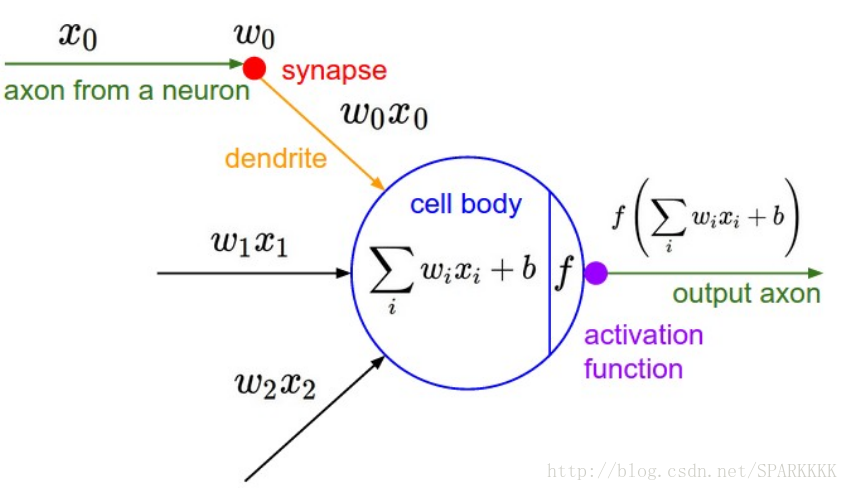
这个模型其实是和生物学关系不是特别大的
在神经元输出端有一个合适的LossFunction的话,就能让这单一的神经元变为线性分类器
Activation Function 神经网络的激活函数
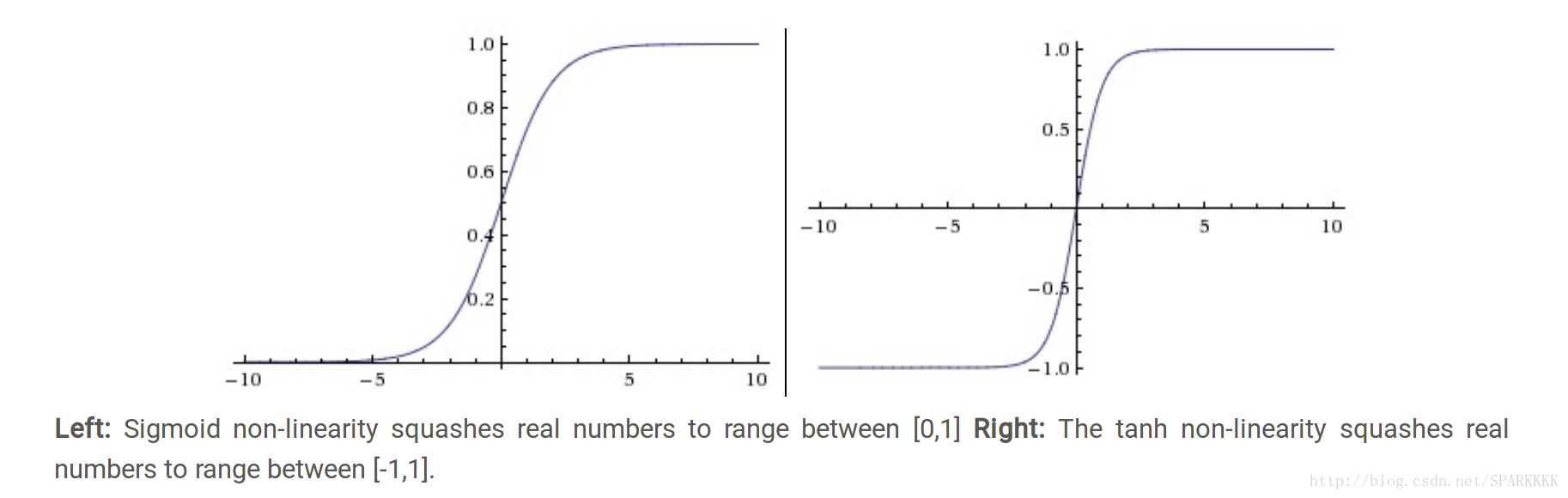
Sigmoid
上面左图。这个函数曾经十分受欢迎,因为他对神经元的激活率有很好地解释,从完全不激活(0)到完全饱和的激活(1)。但现在已经不常用了因为有两个缺点。Sigmoid函数饱和使梯度消失。当函数值接近0或1时局部梯度将会几乎为0,当进行反向传播的时候,乘以一个趋于0的数会使反向传播过程中的梯度在这一层被杀死(即消失)。几乎就没有信号数据通过神经元传到权重再到数据了。初始化矩阵W的时候还要特别注意因为如果W的过大,那么大多数神经元将会饱和,导致网络不学习失去意义
Sigmoid函数的输出不是以零为中心的。因为输入数据总是正数,那么梯度就可能全为正或全为负,这样会导致权重W更新时出现Z字型下降,但一个batch的数据梯度加起来后,权重W的最终更新就会有不同的正负,这就从一定程度上减轻了这个问题。这相对于神经元饱和只是个小问题
Tanh
上面右图。他也存在神经元饱和的问题,但是结果是以零为中心的。所以tanh比sigmoid更常被使用。其实tanh就是类似于一个放大版本的sigmoid。tanh(x)=2σ(2x)−1Rectified linear unit,ReLU 修正线性单元
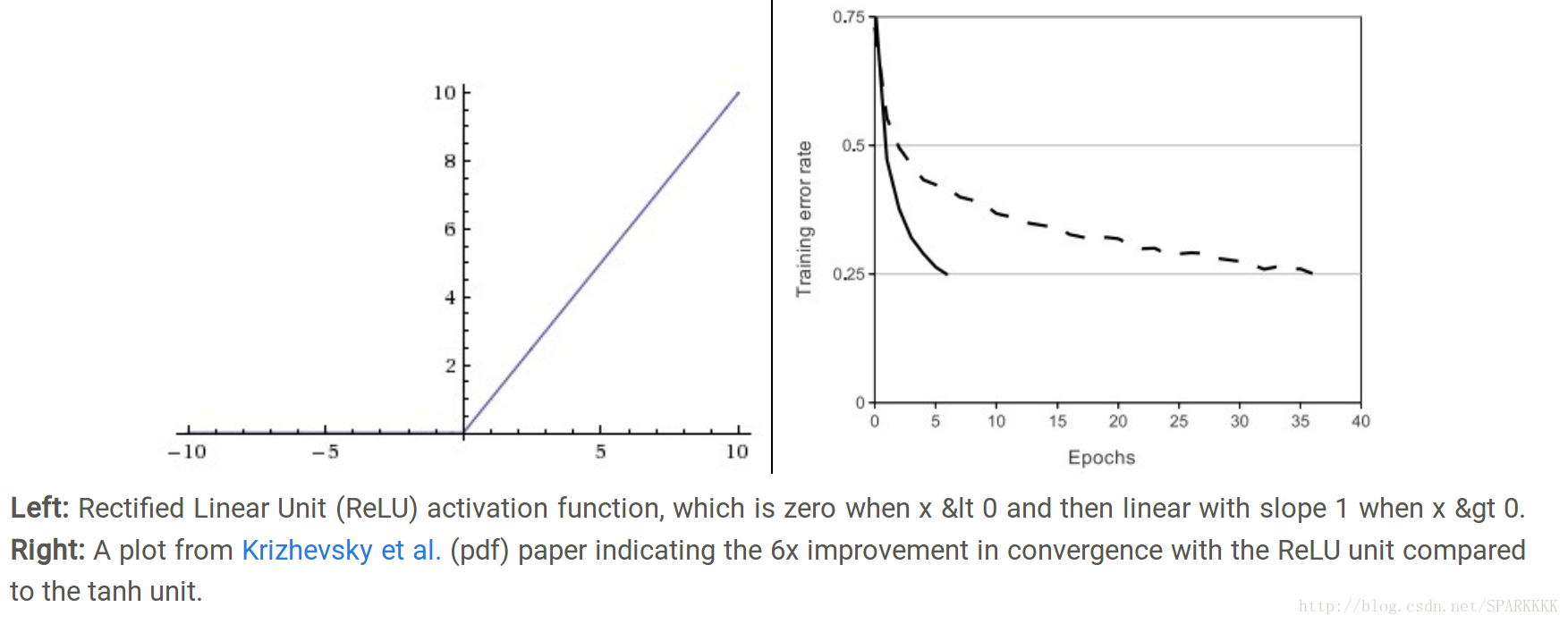
如上图左。公式为:f(x)=max(0,x)
优点:如上图右。相比于sigmoid/tanh函数,它对SGD随机梯度下降收敛有巨大加速效果(Krizhevsky论文指出有6倍之多)。据称这是由它的线性,非饱和的公式导致的。
优点:相比于tanh/sigmoid这种包含运算量大(例如指数运算等)的操作的函数,ReLU可以对一个矩阵由简单的阈值操作得到
缺点:不是零均值输出
缺点:可能会导致梯度更新至一种特别的状态而无法被其他任何数据点激活,使得流过这个神经元的梯度都变为0,导致这个ReLU神经元不可逆转的死亡,特别是learningrates太高的时候。所以需要选择一个合适的learnningrates就可以降低神经元死亡发生的频率。
个人觉得就是梯度值太大然后LearningRates也太大导致W参数更新后值变为≤0,使得f(x)=max(0,x)中x的系数1瞬间变为非正数,而输入值x又可能恒大于0,所以f(x)恒为0,所以局部梯度也恒为0,导致其再也不会对其他input的值x有反应了,也就是die死亡了…..
Unfortunately, ReLU units can be fragile during training and can “die”. For example, a large gradient flowing through a ReLU neuron could cause the weights to update in such a way that the neuron will never activate on any datapoint again. If this happens, then the gradient flowing through the unit will forever be zero from that point on. That is, the ReLU units can irreversibly die during training since they can get knocked off the data manifold. For example, you may find that as much as 40% of your network can be “dead” (i.e. neurons that never activate across the entire training dataset) if the learning rate is set too high. With a proper setting of the learning rate this is less frequently an issue.

Leaky ReLU
它可以尝试着解决ReLU的死亡问题f(x)=1(x<0)(αx)+1(x>=0)(x)
其中α是一个很小的常数。
有些研究者指出激活函数的表现不错但是不够稳定。
[Delving Deep into Rectifiers](https://arxiv.org/abs/1502.01852)论文提出了一种新的方法PReLU,把负区间的斜率当做神经元的一个参数,但不同任务中益处的一致性还不是特别清楚。
ELU
f(x)={xα(exp(x)−1)if x>0if x≤0有ReLU的所有优点
不会死亡
输出具有近似零均值的效果
但是计算量比较大因为有exp()
Maxout
不使用f(wTx+b)的形式而是使用max(wT1x+b1,wT2x+b2)在Goodfellow有介绍。
Maxout是对ReLU和LeakyReLU的一般化,可以注意到的是ReLU和LeakyReLU都是Maxout的一种特殊情况(ReLU中我们令w1,b=0),所以Maxout有了ReLU的所有优点(线性操作与不饱和),而且没有ReLU神经元会死亡的缺点。但是它和ReLU相比,在每个神经元的参数数量增加了一倍,导致了整体的参数数量增加。
同一个神经网络中,混合使用不同类型的神经元是很少见的即时没有什么根本性问题去让我们不去这么做
所以一般来讲使用ReLU,调控LearningRates然后监视神经元死亡率,如果这个问题一直没有解决那就尝试使用LeakyReLU和Maxout。不要使用sigmoid。tanh可以使用但是效果一般不如ReLU和Maxout
RELU 激活函数及其他相关的函数
修正线性单元(Rectified linear unit,ReLU)
神经网络结构
层与神经元模型N层神经网络的N是不计算input layer的,1层的神经网络表明没有hidden layers。所以有些人会说SVM和逻辑回归只是单层神经网络的一种特例。
人工神经网络(Artificial Neural Networks 缩写ANN)或者多层感知器(Multi-Layer Perceptrons 缩写MLP)均指代神经网络
一般使用units单元作为术语而不是neurons神经元
输出层一般没有activation function(或者说有一个线性相等的函数)。因为最后的输出层代表分类的scores
神经网络的大小:用神经元的数目或参数的数目去衡量神经网络的大小
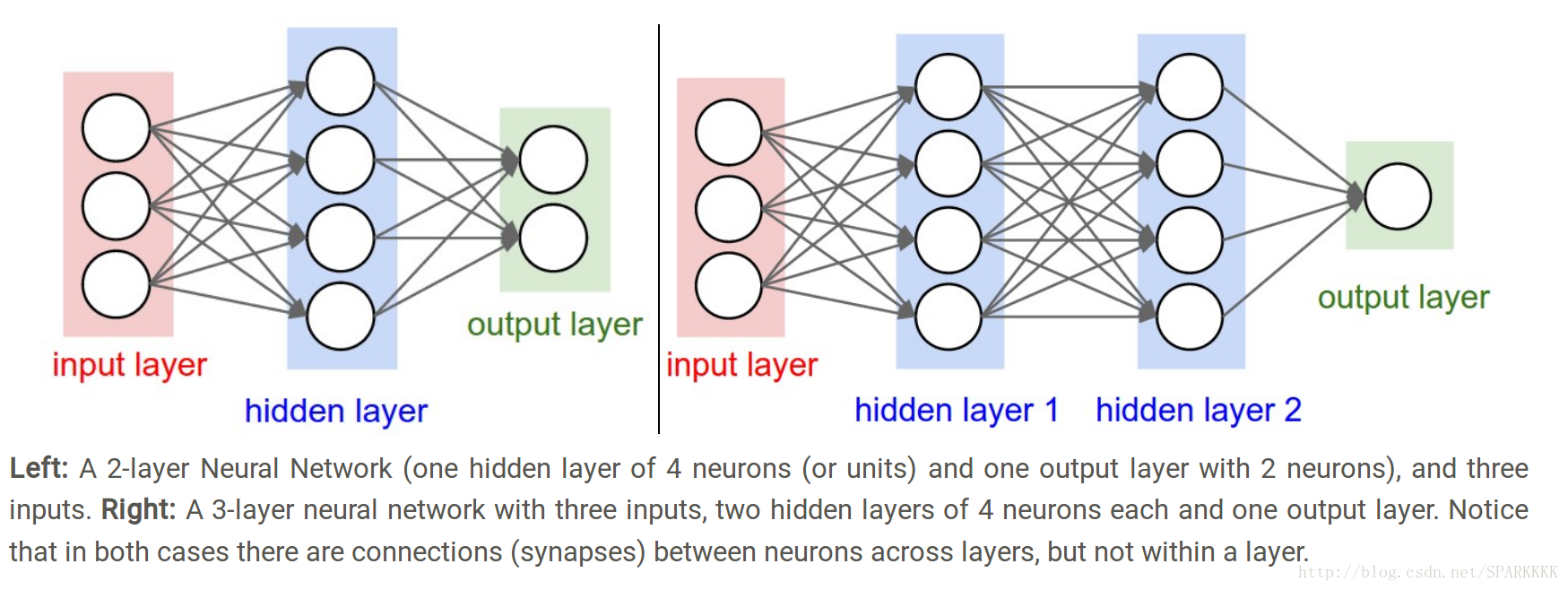
The first network (left) has 4 + 2 = 6 neurons (not counting the inputs), [3 x 4] + [4 x 2] = 20 weights and 4 + 2 = 6 biases, for a total of 26 learnable parameters.
The second network (right) has 4 + 4 + 1 = 9 neurons, [3 x 4] + [4 x 4] + [4 x 1] = 12 + 16 + 4 = 32 weights and 4 + 4 + 1 = 9 biases, for a total of 41 learnable parameters.
上图同时也为全连接层(fully-connected layer),即相邻两层之间的units两两连接,但同一层内的units不连接
前向传播
上图中,input为[3×1];第一隐层的weightW1是[4×3],biasb1为[4×1],这样每个前一层units对后一层的weight都在W1的一行中。这样np.dot(W1,x),就能计算该layer的所有units的激活数据;然后再把该layer的所有units的数据通过W2[4×4]传给第二个隐层;
W3是[1×4]的矩阵用于输出层。
所以3层神经网络的forward pass就是简单的3次matrix multiplications矩阵乘法,其中可能还有activation function的运用
# forward-pass of a 3-layer neural network: f = lambda x: 1.0/(1.0 + np.exp(-x)) # activation function (use sigmoid) x = np.random.randn(3, 1) # random input vector of three numbers (3x1) h1 = f(np.dot(W1, x) + b1) # calculate first hidden layer activations (4x1) h2 = f(np.dot(W2, h1) + b2) # calculate second hidden layer activations (4x1) out = np.dot(W3, h2) + b3 # output neuron (1x1)
W1,W2,W3,b1,b2,b3均为学习参数,而x作为input可以批量携带多个数据(不详说,和之前linear classifier一个道理)
全连接层的前向传播一般就是先进行一个矩阵乘法,然后加上偏置并运用激活函数。
神经网络的表达能力
拥有至少一层隐层(即两层)的神经网络可以作为一个通用近似器,也就是说神经网络可以近似代表任意连续函数。但两层神经网络的表达能力其实是相对比较差的。经验规律:虽然在理论上深层网络(使用了多个隐层)和单层网络的表达能力是一样的,但是就实践经验而言,深度网络效果比单层网络好。
在实践中,3层神经网络表现得比2层好,但如果继续加深(例如4,5,6层)则很少有太大帮助。但是ConvNN卷积神经网络则不同,深度会对结果造成巨大的影响。
设置层数和尺寸
增加大小和层数,神经网络的能力的确是可以增加的。更大的神经网络可以表示跟更加复杂的函数。每一层的units数目太多但容易过拟合,但需要用别的方法(如L2 regularization, dropout, input noise)去防止过拟合,而不是降低神经网络大小。
因为小的神经网络更难使用梯度下降等局部操作进行训练。虽然小型网络的损失函数的局部极小值更少,也比较容易收敛到这些局部极小值,但是这些最小值一般都很差,损失值很高。
正则化是控制过拟合的一种好方法
其实意思就是大的神经网络可以减少偶然性,然后也有比较好的方法去减小过拟合,所以要用大的网络而不是小的
neural networks: bigger = better (but might have to regularize more strongly)
参考资料:https://zhuanlan.zhihu.com/p/21462488?refer=intelligentunit
https://zhuanlan.zhihu.com/p/21513367?refer=intelligentunit
Assignment1–NeuralNetwork 2-Layer Net
http://blog.csdn.net/yc461515457/article/details/51944683这里面介绍的链式法则对矩阵求导的思路很值得学习,而且对矩阵求导的时候要注意链式法则乘法的顺序
http://blog.csdn.net/xieyi4650/article/details/53332988

相关文章推荐
- Stanford机器学习笔记-4. 神经网络Neural Networks (part one)
- Stanford机器学习笔记-5.神经网络Neural Networks (part two)
- Stanford机器学习笔记-5.神经网络Neural Networks (part two)
- 神经网络第二部分:神经元Neural Networks, Part 2: The Neuron
- Stanford机器学习笔记-4. 神经网络Neural Networks (part one)
- 神经网络第一部分:背景Neural Networks, Part 1: Background
- Neural Networks and Deep Learning 神经网络和深度学习book
- 机器学习(3)-神经网络_Neural Networks
- 今天开始学模式识别与机器学习(PRML),章节5.1,Neural Networks神经网络-前向网络。
- Neural Networks神经网络编程入门
- 建立神经网络:Part 0
- 线性神经网络Linear Neural Networks
- Coursera机器学习 week5 神经网络的学习 assignment
- 机器学习教程之5-神经网络:表述(Neural Networks:Representation)
- 机器学习笔记(五)----神经网络的学习(Neural Networks: Learning)
- Stanford机器学习---第五讲. 神经网络的学习 Neural Networks learning
- 斯坦福大学机器学习“神经网络的表示(Neural Networks: Representation)”
- 机器学习之神经网络模型-上(Neural Networks: Representation)
- Hinton Neural Networks课程笔记4a:使用神经网络做逻辑推理
- Neural Networks and Deep Learning 神经网络和深度学习