后端c++知识点总结
2017-02-21 20:18
239 查看
这一篇是C++的一些面试点的总结。
1、一个String类的完整实现必须很快速写出来(注意:赋值构造,operator=是关键)
如果对C++String不熟悉的话,先看http://www.cplusplus.com/reference/去了解一下String类常用的方法,如果想了解C语言的实现,去看一下《C语言接口与实现》(十五章 低级字符串)。
Scott Meyers在《effecive STL》中提到了std::string有多种实现方式。
总结起来有三类(代码来源《Linux多线程服务端编程》):
1. 无特殊处理,使用类似std::vector的数据结构。start到end之间存储数据,start到end_of_storage之间是容量大小,这样能减少扩容时数据复制的概率。后面两个成员变量还可以使用整数代替,如果字符串大小有限,可以使用u32等来表示end和end_of_storage,减小对象的大小。
2
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
9
2. Copy-on-Write。对象里只放一个指针。
2
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
9
3.短字符优化,利用字符串对象本身的空间存储短字符串,通常阈值是15字节。当定义比较短的字符串对象时,不需要再次申请分配内存。
2
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
9
这里给出关键的赋值函数
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
这个问题在《深度探索C++对象模型》中有非常详细的讲解。
这里只简单的说一下原理。如果你不知道虚函数和多态的概念,先去看看《C++primer》之类的语言书。
首先,如果一个类中含有虚函数,那么每一个类就会有一个virtual table,这个表中放置着各个虚函数的地址。然后每一个类对象(就是实例)中会被安插一个由编译器产生的指针vptr,该指针指向一个virtual table,class所关联的type_info,会放在vitrual table的第一个slot中,用来表示class的类型。
识别多态的方式是查看类中是否有虚函数,实现就是通过指针取用相应的函数。例如
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
当我们调用z()的时候,并不知道ptr所指向的对象的真正类型,这个是在执行期确定的。但是我们可以知道ptr可以访问到改对象的virtual table。
虽然不知道具体哪一个z()实例会被调用,是基类的,还是继承类的,但是我们可以确定每一个z()函数地址所存放的slot,它在virtual table中的位置是确定的。
通过这些信息编译器可以在编译器将该调用转化成:
1
通过执行期获取到ptr的具体类型,就实现了多态。
上面是比较美好的单一继承的情况,多继承下需要考虑this指针的调整问题,可以选择使用thunk技术(以适当offset调整this指针,跳到virtual function 去),或者像cfont编译器的做法一样,将每一个virtual table slot调整成含有offset的集合体。
Derived class中会含有额外的virtual table来识别base1,base2…baseN。每一个virtual table的slot中放置原始的地址或者thunk地址。
虚拟继承还需要考虑到virtual base类的offset调整,已经繁琐到让人不愿谈了。
直接给一个例子,大致覆盖一下这些情况。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
总的来说,编译器会自动加上一些额外的data members,用以支持某些语言特性,并会做边界的对齐调整。这里没有对多重继承,虚继承做详细讲解,我觉得自己猜测内存布局的情况,并且动手测一下效果更好。
已经是问烂的问题了,除了可以用来间接的引用其他对象,基本没什么共同点。参考《more effecive c++》
1. 首先,引用的值不能为空,它必须总是指向某些对象。但是记住你可以声明一个指针变量,赋值为空,然后把变量声明为引用。
2
1
2
2. 因为引用肯定会指向一个对象,因此必须初始化,其实和1是一回事。指针无此限制,但是,其实指针的未初始化,过不了coverity这些工具的检测。
3. 指针可以重新赋值,引用不可以,初始化后就不可改变。
4. sizeof结果不同,指针返回的是指针本身大小,引用返回的是引用对象的大小
5.引用既然限制这么多,为什么不干脆都用指针,因为引用不占用空间,它只是个别名
如果你指向对象可能为空或者需要改变指向的时候,使用指针,如果指向一个对象后不会改变指向或者重载某个操作符的时候,使用引用。
顺序就是构造时候基类的先构造,析构的时候继承类的先析构。析构的调用顺序和构造相反。
参考《STL源码剖析》,或者自己用code Insight查看一下STL的类的实现。
简单的提一下吧。
STL中的容器大致分为两类:序列式容器和关联式容器,涵盖了常用的各种数据结构。
序列是指容器中的元素可序,但未必有序。除了C++提供的array之外,STL另外提供了vector,list,deque,stack,queue等。
vector:与array相似,采用线性连续空间,但是提供了扩容的功能,当新的元素加入,且原空间不足的时候,它内部会自动分配空间,移动拷贝数据,释放旧空间。注意vector有容量的概念,为了防止频繁的分配拷贝,因此申请的空间比需求的要更大一些。
list:list相对于vector这种线性空间的好处就是利用率高,插入删除一个元素,就分配释放一个元素的空间,元素的插入和删除是常数时间。STL的list就是一个环形的双向链表,使用bidirection Iterators,就是具备前移,后移能力的迭代器,注意stl中的几种不同型别迭代器。其操作就是一些指针操作。
deque:deque是双向开口的连续线性空间,vector也可以做成双向的,但是其头部的操作效率奇差,需要大量的移动后面的数据。deque通过动态的分段的连续空间的组合,完成头端常数时间内的插入删除操作。deque内部通过对各种指针操作的重载,完成缓冲区边缘的处理。
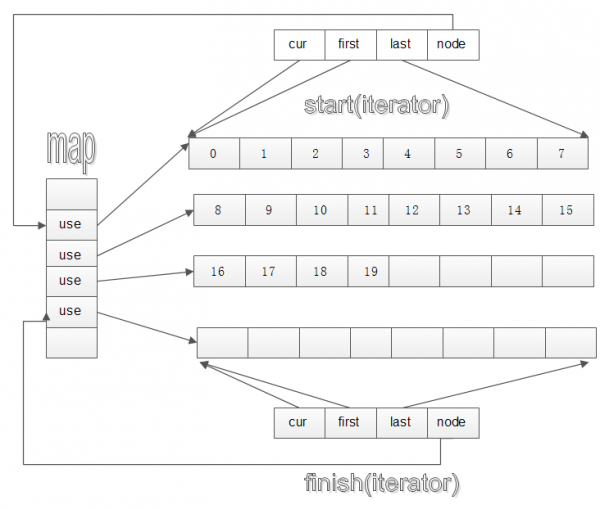
deque的大致结构如图所示:
stack:stack是先进后出的数据结构,只有一个出口,结构就是以deque为底部结构,然后封闭其头端开口,形成单向结构。这种改法称为适配器。
queue:queue就是队列了,两个出口,先进先出。元素的操作都在顶端和底端,最顶端取出,最底端加入。结构同样是以deque为底部结构,然后封闭底端出口和顶端的入口。至于怎么封闭,你不给出相对应接口函数就好了嘛。
priority_queue:拥有权值观念的queue。权值最高的排在队列头部,元素入队的时候会按照权值排列。priority_queue缺省情况下用vector作为容器,然后使用堆的一些泛型算法实现。
关联容器的每笔数据都有一个key和value。当元素插入容器时,容器内部依照键值的大小和某种规则将其放置到合适位置。
STL中关联式容器分为set和map两大类。
set:set所有元素会根据键值自动排序,set的key就是value。并且不允许两个元素有相同的key。set的底层就是红黑树,这里不对红黑树做直接的介绍了。注意set的插入使用了RB-tree的insert_unique()函数来保证没有重复的key,其结构本身是不限制key的重复的。
multiset:和set主要的区别就是允许有重复的key值,用法和其他特性和set相同。插入操作使用insert-equal()。
map:map的元素都是一对pair,同时拥有key和value,不允许同key。注意map的key不可更改,value可更改。map的数据类型是pair,结构底层使用RB-tree。
multimap:类似set和multiset,差别只是插入函数的不同。
hash_set:使用hashtable为底层机制,就是一个vector+list的开链法的hash结构。
hash_map:同样是以hashtable为底层,转调用其操作。只是数据节点的类型是map而已。
hash_multiset:和hash_set插入函数不同。
hash_multimap:和hash_map插入函数不同。
c++编译器为了支持重载,会对函数的名称进行特殊的处理,在编译函数的过程中会将函数的参数类型也添加到编译后的代码中。
使用backtrace等函数打印堆栈时,就会显示被修改过后的函数名字_Z3foov,使用c++filt可以将名称转化成正常的形式。
然而C语言不支持函数的重载,编译C语言代码时函数不应带上函数的参数,以此保证在C++中能够正确调用C开发的库,能够找到对应的函数,使用extern C可以抑制函数的name mangling。
extern C的主要含义:
1.告诉编译器其函数或者变量的声明在其他模块中,并且在链接阶段从其他模块中找到次函数。
2.函数按照C语言的方式编译和链接。
当对象的值可能在程序的控制或者检测之外被改变时,应该将对象声明为volatile。告诉编译器不应该对这样的对象进行优化。当要求使用其声明的变量值得时候,需要从它所在的内存地址中读取数据,而不是从CPU的寄存器中读取。因为编译器可能会将变量从内存装入cpu寄存器中作为缓存,提高读取速度。
static声明外部对象时,可以达到隐藏外部对象的目的,限定其作用域为被编译源文件的剩余部分。
static声明局部变量时,它将一直存在,不像自动变量一样随函数的退出而消失。static类型的内部变量时一种只能在某个特定函数中使用单一直占据存储空间的变量。
const是一种语义约束,而编译器会强制实施这项约束,它允许你告诉编译器和其他程序员某值应该保持不变。《effictive c++》中有一条是尽可能使用const。
const可修饰的东西非常多,常量,文件,函数,类内的static和non-static成员变量。
在《C++primer》中使用顶层和底层const限定来区别const修饰的是指针自身还是指针所指物。
其实很好区分,const出现在星号左边,表示被指物是常量,出现在右边,表示指针自身是常量。
2
3
1
2
3
const可以在函数声明时使用,与函数返回值,参数,函数自身产生关联。
1.令函数返回一个常量值,可以防止返回值被当成左值被修改。
2.如果没有赋值的意思,应使用const修饰参数,以区别输入和输出。
3.const修饰成员函数,一是声明那个函数可改动对象内容,二是使其可以操作const对象。注意两个成员函数如果只是常量性不同,可以被重载。
const还可以把引用绑定到const对象上,对常量的引用不能被用作修改它所绑定的对象。
最后,使用const_cast可以解除对象的const限定。
1、一个String类的完整实现必须很快速写出来(注意:赋值构造,operator=是关键)
如果对C++String不熟悉的话,先看http://www.cplusplus.com/reference/去了解一下String类常用的方法,如果想了解C语言的实现,去看一下《C语言接口与实现》(十五章 低级字符串)。
Scott Meyers在《effecive STL》中提到了std::string有多种实现方式。
总结起来有三类(代码来源《Linux多线程服务端编程》):
1. 无特殊处理,使用类似std::vector的数据结构。start到end之间存储数据,start到end_of_storage之间是容量大小,这样能减少扩容时数据复制的概率。后面两个成员变量还可以使用整数代替,如果字符串大小有限,可以使用u32等来表示end和end_of_storage,减小对象的大小。
class string{
public:
iterator begin() { return start; }
iterator end() { return end; }
private:
char* start;
char* end;
char* end_of_storage;
};12
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
9
2. Copy-on-Write。对象里只放一个指针。
class string{
struct Rep{
size_t size;
size_t capacity;
size_t refcount;
char* data[1];
};
char* start;
};12
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
9
3.短字符优化,利用字符串对象本身的空间存储短字符串,通常阈值是15字节。当定义比较短的字符串对象时,不需要再次申请分配内存。
class string{
char* start;
size_t size;
static const int kLocalSize = 15;
union{
char buffer[kLocalSize+1];
size_t capacity;
}data;
};12
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
9
这里给出关键的赋值函数
/*
如下为CMyString的声明,请为该类型添加赋值运算符
*/
#include<iostream>
#include<string.h>
class CMyString{
public:
CMyString(char *m_pData=NULL);
CMyString(const CMyString& str);
~CMyString(void);
CMyString& operator=(const CMyString& rhs);
private:
char * m_pData;
};
/*
考察几个知识点:
1.返回值类型为 X& 解决连续赋值时的左值问题
2.使用const &提高效率,避免传参数时的拷贝构造
3.在赋值和拷贝构造函数中,应该先释放原对象空间,重新申请,
避免两个指针指向同一内存,浅拷贝问题,避免内存泄漏。
4.可以使用swap的写法,先构造局部变量,在作用域之外释放掉。
5.字符串申请空间时。应该+1,为结束符'\0'留位置。
6.strcpy应该使用更安全的strncpy代替,避免缓冲区溢出。
*/
CMyString& CMyString::operator=(const CMyString& rhs){
if(this!=&rhs){
delete []m_pData;
m_pData=NULL;
m_pData=(char *)malloc(strlen(rhs.m_pData)+1);
strcpy(m_pData,rhs.m_pData);
//可用构造后交换防止异常
/* CMyString strTemp(rhs);
char *pTemp=strTemp.m_pData;
strTemp.m_pData=m_pData;
m_pData=pTemp;*/
}
return *this;
}12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
2、虚函数的作用和实现原理(必问必考,实现原理必须很熟)
这个问题在《深度探索C++对象模型》中有非常详细的讲解。 这里只简单的说一下原理。如果你不知道虚函数和多态的概念,先去看看《C++primer》之类的语言书。
首先,如果一个类中含有虚函数,那么每一个类就会有一个virtual table,这个表中放置着各个虚函数的地址。然后每一个类对象(就是实例)中会被安插一个由编译器产生的指针vptr,该指针指向一个virtual table,class所关联的type_info,会放在vitrual table的第一个slot中,用来表示class的类型。
识别多态的方式是查看类中是否有虚函数,实现就是通过指针取用相应的函数。例如
class Point{
public:
virtual ~Point();
//...其他操作
virtual float z() const { return 0; }
};
class Point3d{
public:
float z const{ return _z; }
protected:
float _z;
};
Point *ptr;
ptr = new Point3d;
ptr ->z();12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
当我们调用z()的时候,并不知道ptr所指向的对象的真正类型,这个是在执行期确定的。但是我们可以知道ptr可以访问到改对象的virtual table。
虽然不知道具体哪一个z()实例会被调用,是基类的,还是继承类的,但是我们可以确定每一个z()函数地址所存放的slot,它在virtual table中的位置是确定的。
通过这些信息编译器可以在编译器将该调用转化成:
(*ptr->vptr[4])(ptr);1
1
通过执行期获取到ptr的具体类型,就实现了多态。
上面是比较美好的单一继承的情况,多继承下需要考虑this指针的调整问题,可以选择使用thunk技术(以适当offset调整this指针,跳到virtual function 去),或者像cfont编译器的做法一样,将每一个virtual table slot调整成含有offset的集合体。
Derived class中会含有额外的virtual table来识别base1,base2…baseN。每一个virtual table的slot中放置原始的地址或者thunk地址。
虚拟继承还需要考虑到virtual base类的offset调整,已经繁琐到让人不愿谈了。
3、sizeof一个类求大小(注意成员变量,函数,虚函数,继承等等对大小的影响)
直接给一个例子,大致覆盖一下这些情况。#include <iostream>
using namespace std;
class X{};
class Y:public virtual X{};
class Z:public virtual X{};
class A:public Y,public Z{};
class Point{
private:
char a;
char b;
char c;
//注释掉d,大小为3
float d;
};
class Point2d{
public:
virtual float getX(){ return x;}
virtual float getY(){ return y;}
private:
float x;
float y;
};
class Point3d{
public:
Point3d translate(const Point3d &pt){
x += pt.x;
y += pt.y;
}
private:
float x;
float y;
static const int chunkSize = 250;
float z;
};
class Point4d:public Point3d{
private:
float n;
};
int main(void){
//对于空的class,编译器安插进一个char,使其不同实例在内存中能各自有地址
cout << sizeof(X) << endl;
//首先空的虚基类被视为继承类最开头的一部分,空间为0
//而继承类自身有一个指向表格或者virtual base class subobject的
//指针,这里指针大小为8
cout << sizeof(Y) << endl;
cout << sizeof(Z) << endl;
//base Y + base Z
cout << sizeof(A) << endl;
cout << sizeof(void *) <<endl;
cout << sizeof(float) <<endl;
//注意这里编译器会使用对齐调整,补一个字节
std::cout << sizeof(Point) << std::endl;
//static成员并不占用对象的空间
std::cout << sizeof(Point3d) << std::endl;
//只要有虚函数,就会生成一个vptr指针,可能在内存布局的头或者尾
//大小为vptr + 2*sizeof(float)
std::cout << sizeof(Point2d) << std::endl;
//继承类会追加基类的成员
//大小为sizeof(base)+sizeof(drived)
std::cout << sizeof(Point4d) <<std::endl;
return 0;
}
Running /home/ubuntu/workspace/gdbTest/testForData.cc
1
8
8
16
8
4
8
12
16
1612
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
总的来说,编译器会自动加上一些额外的data members,用以支持某些语言特性,并会做边界的对齐调整。这里没有对多重继承,虚继承做详细讲解,我觉得自己猜测内存布局的情况,并且动手测一下效果更好。
4、指针和引用的区别(一般都会问到)
已经是问烂的问题了,除了可以用来间接的引用其他对象,基本没什么共同点。参考《more effecive c++》 1. 首先,引用的值不能为空,它必须总是指向某些对象。但是记住你可以声明一个指针变量,赋值为空,然后把变量声明为引用。
char *pc = 0; char &rc = *pc;1
2
1
2
2. 因为引用肯定会指向一个对象,因此必须初始化,其实和1是一回事。指针无此限制,但是,其实指针的未初始化,过不了coverity这些工具的检测。
3. 指针可以重新赋值,引用不可以,初始化后就不可改变。
4. sizeof结果不同,指针返回的是指针本身大小,引用返回的是引用对象的大小
5.引用既然限制这么多,为什么不干脆都用指针,因为引用不占用空间,它只是个别名
如果你指向对象可能为空或者需要改变指向的时候,使用指针,如果指向一个对象后不会改变指向或者重载某个操作符的时候,使用引用。
5、多重类构造和析构的顺序
顺序就是构造时候基类的先构造,析构的时候继承类的先析构。析构的调用顺序和构造相反。
6、stl各容器的实现原理(必考)
参考《STL源码剖析》,或者自己用code Insight查看一下STL的类的实现。 简单的提一下吧。
STL中的容器大致分为两类:序列式容器和关联式容器,涵盖了常用的各种数据结构。
序列是指容器中的元素可序,但未必有序。除了C++提供的array之外,STL另外提供了vector,list,deque,stack,queue等。
vector:与array相似,采用线性连续空间,但是提供了扩容的功能,当新的元素加入,且原空间不足的时候,它内部会自动分配空间,移动拷贝数据,释放旧空间。注意vector有容量的概念,为了防止频繁的分配拷贝,因此申请的空间比需求的要更大一些。
list:list相对于vector这种线性空间的好处就是利用率高,插入删除一个元素,就分配释放一个元素的空间,元素的插入和删除是常数时间。STL的list就是一个环形的双向链表,使用bidirection Iterators,就是具备前移,后移能力的迭代器,注意stl中的几种不同型别迭代器。其操作就是一些指针操作。
deque:deque是双向开口的连续线性空间,vector也可以做成双向的,但是其头部的操作效率奇差,需要大量的移动后面的数据。deque通过动态的分段的连续空间的组合,完成头端常数时间内的插入删除操作。deque内部通过对各种指针操作的重载,完成缓冲区边缘的处理。
deque的大致结构如图所示:
stack:stack是先进后出的数据结构,只有一个出口,结构就是以deque为底部结构,然后封闭其头端开口,形成单向结构。这种改法称为适配器。
queue:queue就是队列了,两个出口,先进先出。元素的操作都在顶端和底端,最顶端取出,最底端加入。结构同样是以deque为底部结构,然后封闭底端出口和顶端的入口。至于怎么封闭,你不给出相对应接口函数就好了嘛。
priority_queue:拥有权值观念的queue。权值最高的排在队列头部,元素入队的时候会按照权值排列。priority_queue缺省情况下用vector作为容器,然后使用堆的一些泛型算法实现。
关联容器的每笔数据都有一个key和value。当元素插入容器时,容器内部依照键值的大小和某种规则将其放置到合适位置。
STL中关联式容器分为set和map两大类。
set:set所有元素会根据键值自动排序,set的key就是value。并且不允许两个元素有相同的key。set的底层就是红黑树,这里不对红黑树做直接的介绍了。注意set的插入使用了RB-tree的insert_unique()函数来保证没有重复的key,其结构本身是不限制key的重复的。
multiset:和set主要的区别就是允许有重复的key值,用法和其他特性和set相同。插入操作使用insert-equal()。
map:map的元素都是一对pair,同时拥有key和value,不允许同key。注意map的key不可更改,value可更改。map的数据类型是pair,结构底层使用RB-tree。
multimap:类似set和multiset,差别只是插入函数的不同。
hash_set:使用hashtable为底层机制,就是一个vector+list的开链法的hash结构。
hash_map:同样是以hashtable为底层,转调用其操作。只是数据节点的类型是map而已。
hash_multiset:和hash_set插入函数不同。
hash_multimap:和hash_map插入函数不同。
7、extern c 是干啥的,(必须将编译器的函数名修饰的机制解答的很透彻)
c++编译器为了支持重载,会对函数的名称进行特殊的处理,在编译函数的过程中会将函数的参数类型也添加到编译后的代码中。
使用backtrace等函数打印堆栈时,就会显示被修改过后的函数名字_Z3foov,使用c++filt可以将名称转化成正常的形式。
然而C语言不支持函数的重载,编译C语言代码时函数不应带上函数的参数,以此保证在C++中能够正确调用C开发的库,能够找到对应的函数,使用extern C可以抑制函数的name mangling。
extern C的主要含义:
1.告诉编译器其函数或者变量的声明在其他模块中,并且在链接阶段从其他模块中找到次函数。
2.函数按照C语言的方式编译和链接。
8、volatile是干啥用的,(必须将cpu的寄存器缓存机制回答的很透彻)
当对象的值可能在程序的控制或者检测之外被改变时,应该将对象声明为volatile。告诉编译器不应该对这样的对象进行优化。当要求使用其声明的变量值得时候,需要从它所在的内存地址中读取数据,而不是从CPU的寄存器中读取。因为编译器可能会将变量从内存装入cpu寄存器中作为缓存,提高读取速度。
9、static const等等的用法,(能说出越多越好)
static声明外部对象时,可以达到隐藏外部对象的目的,限定其作用域为被编译源文件的剩余部分。 static声明局部变量时,它将一直存在,不像自动变量一样随函数的退出而消失。static类型的内部变量时一种只能在某个特定函数中使用单一直占据存储空间的变量。
const是一种语义约束,而编译器会强制实施这项约束,它允许你告诉编译器和其他程序员某值应该保持不变。《effictive c++》中有一条是尽可能使用const。
const可修饰的东西非常多,常量,文件,函数,类内的static和non-static成员变量。
在《C++primer》中使用顶层和底层const限定来区别const修饰的是指针自身还是指针所指物。
其实很好区分,const出现在星号左边,表示被指物是常量,出现在右边,表示指针自身是常量。
const char *p;//const data char* const p;//const pointer const char* const p;//const pointer,const data1
2
3
1
2
3
const可以在函数声明时使用,与函数返回值,参数,函数自身产生关联。
1.令函数返回一个常量值,可以防止返回值被当成左值被修改。
2.如果没有赋值的意思,应使用const修饰参数,以区别输入和输出。
3.const修饰成员函数,一是声明那个函数可改动对象内容,二是使其可以操作const对象。注意两个成员函数如果只是常量性不同,可以被重载。
const还可以把引用绑定到const对象上,对常量的引用不能被用作修改它所绑定的对象。
最后,使用const_cast可以解除对象的const限定。
