[redis读书笔记] 第一部分 数据结构与对象 字典
2017-02-21 10:58
351 查看
三 字典
字典是Hash对象的底层实现,比如用HSET创建一个HASH的对象,底层可能就是用一个字典实现的键值对。
字典的实现主要设计下面三个结构:
他们之间的关系如下图:
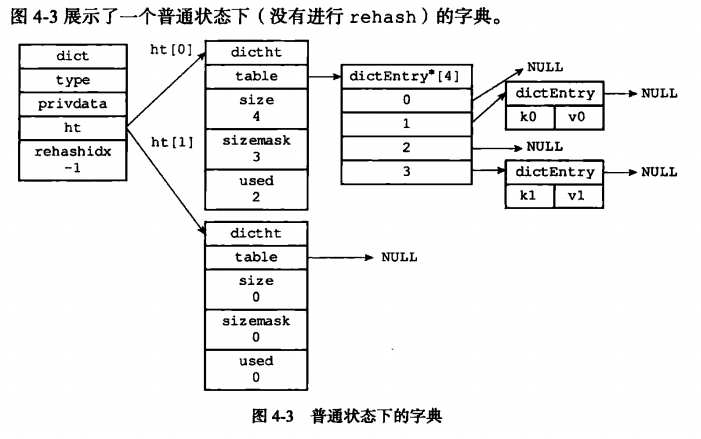
- dict.type里会注册回调函数,用来实现计算哈希值(hashFunction(),redis使用MurmurHash2算法来计算哈希值(dictEncObjHash))等等功能,用dict.sizemask计算索引值,即dictentry[i]的下标值

- 键冲突:不同的键分配到同一个索引,就在这个dictentry[i]上构成单向链表
- rehash:哈希表有一个负载因子的概念,load_factor=ht[0].used/ht[0].size,当这个值大于等于1(或者满足以下条件),会进行rehash,也代表了保存的键值过多,进行重新的散列操作,从ht[0]转移所有的hashNode到ht[1]。
rehash过程中,dict.rehashidx用来标明是否在rehash(-1为非rehash),每做一个就加1,最终全部做完后,置为-1,然后将ht[1]的所有entry拷贝回ht[0],这样不需要一次性完成所有node的rehash,避免了rehash时的庞大而集中的计算量。
rehash过程中,如果有对字典的删除,查找和更新操作,可能会对ht[0]和ht[1]都进行操作,比如查找会先到ht[0]找,找不到会到ht[1]找,如果新建,则会保存到ht[1],ht[0]不做新增,保证ht[0]里的键值对只减不增,并随着rehash最终成为空表
字典是Hash对象的底层实现,比如用HSET创建一个HASH的对象,底层可能就是用一个字典实现的键值对。
字典的实现主要设计下面三个结构:
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
/*
* 哈希表
*
* 每个字典都使用两个哈希表,从而实现渐进式 rehash 。
*/
typedef struct dictht {
// 哈希表数组
// [JZ]: 即二维数组/链表
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
/*
* 字典类型特定函数
*/
typedef struct dictType {
// 计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/*
* 字典
*/
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */
} dict;他们之间的关系如下图:
- dict.type里会注册回调函数,用来实现计算哈希值(hashFunction(),redis使用MurmurHash2算法来计算哈希值(dictEncObjHash))等等功能,用dict.sizemask计算索引值,即dictentry[i]的下标值
- 键冲突:不同的键分配到同一个索引,就在这个dictentry[i]上构成单向链表
- rehash:哈希表有一个负载因子的概念,load_factor=ht[0].used/ht[0].size,当这个值大于等于1(或者满足以下条件),会进行rehash,也代表了保存的键值过多,进行重新的散列操作,从ht[0]转移所有的hashNode到ht[1]。
rehash过程中,dict.rehashidx用来标明是否在rehash(-1为非rehash),每做一个就加1,最终全部做完后,置为-1,然后将ht[1]的所有entry拷贝回ht[0],这样不需要一次性完成所有node的rehash,避免了rehash时的庞大而集中的计算量。
rehash过程中,如果有对字典的删除,查找和更新操作,可能会对ht[0]和ht[1]都进行操作,比如查找会先到ht[0]找,找不到会到ht[1]找,如果新建,则会保存到ht[1],ht[0]不做新增,保证ht[0]里的键值对只减不增,并随着rehash最终成为空表

相关文章推荐
- [redis读书笔记] 第一部分 数据结构与对象 整数集合
- [redis读书笔记] 第一部分 数据结构与对象 对象类型
- [redis读书笔记] 第一部分 数据结构与对象 对象特性
- [redis读书笔记] 第一部分 数据结构与对象 链表
- [redis读书笔记] 第一部分 数据结构与对象 简单动态字符串
- [redis读书笔记] 第一部分 数据结构与对象 压缩列表
- [REDIS 读书笔记]第一部分 数据结构与对象 跳跃表
- 《Redis设计与实现》[第一部分]数据结构与对象-C源码阅读(二)
- 《Redis设计与实现》[第一部分]数据结构与对象-C源码阅读(一)
- 数据文件结构分析——第一部分
- SQL Server数据对象结构的动态建立与访问
- user_source数据字典和oracle中对象的源代码
- C#基础系列(4)-- 第一部分 基础数据类型与操作 -- 枚举类型与位标志(4)
- Web Services模式——第一部分:基本数据类型
- Sharp-ORM 自动将数据库封装成对象的生成器,三层数据访问结构
- 对象继承结构到设计数据表方式谈
- C#基础系列(2)-- 第一部分 基础数据类型与操作 -- 位运算(2)
- C#基础系列(1)-- 第一部分 基础数据类型与操作 -- 位运算(1)
- Web Services模式——第一部分:基本数据类型
- 创建数据字典各种对象的函数组SIFD